版权声明:@潘广宇博客, https://blog.csdn.net/panguangyuu/article/details/89297343
一、索引的存储分类
MySQL 提供4种索引:
B-Tree(大部分引擎都支持)、Hash(Memory)、R-Tree(MyISAM,空间索引)、Full-text(MyISAM,全文索引)
其中:Hash索引只能在Memory引擎中,且where条件为=时才会生效
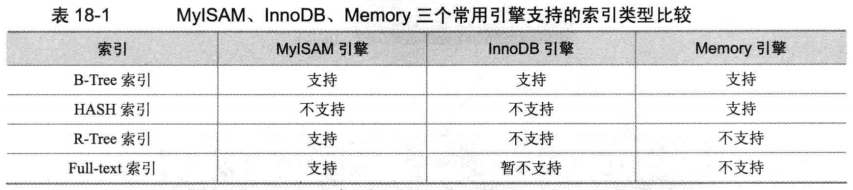
二、MySQL如何使用索引
B-Tree 索引:平衡二叉树结构,可以进行全关键字、关键字范围、关键字前缀查询。
MySQL 索引使用条件:
1)对联合索引中所有列都指定值。
select * from rental where rental_date='2005-05-25 17:22:10' and inventory_id = 373 and customer_id = 343\G;
-- 其中:rental_date,inventory_id,customer_id 是一个联合索引2)对索引的列进行范围查找
select * from rental where customer_id >= 373 and customer_id < 400\G;
-- 其中 customer_id 是一个索引列3)匹配最左前缀,仅使用索引的最左边列进行查找
alter table payment add index idx_payment_date(payment_date, amount, last_update);
-- 建立了一个联合索引 payment_date, amount, last_update
select * from payment where payment_date = '2005-05-25 11:30:37' and amount = 2.99 and last_update = '2006-02-15 22:12:30'\g;
-- 当查询 (payment_date, amount, last_update)、(payment_date, amount)、(payment_date)、(payment_date, last_update) 索引生效。4)select 的列为包含在索引时,查询效率更高
alter table payment add index idx_payment_date(payment_date, amount, last_update);
-- 建立了一个联合索引 payment_date, amount, last_update
select last_update from payment where payment_date = '2005-05-25 11:30:37' and amount = 2.99\g; 5)仅使用联合索引的索引第一列,并且只包含索引第一列开头的一部分进行查找
create index idx_title_desc on file_text(title(10), description(20));
-- 创建联合索引 title(10), description(20)
explain select * from film_text where title like 'AFRICAN%'\G;
-- 查找联合索引的第一列的一部分开头6)索引部分匹配精确,部分进行范围查询
explain select inventory_id from rental where rental_date = '2006-02-14 15:16:03' and customer_id >= 300 and customer_id <=400 \g;7)如果列名是索引,使用 列名 is null 会使用索引
explain select * from payment where rental_id is null;
-- 其中 rental_id 是一个索引列8)MySQL 5.6 后引入 ICP(index condition pushdown) 把某些条件过滤放在存储引擎
explain select * from rental where rental_date = '2006-02-14 15:16:03' and customer_id >= 300 and customer_id <=400 \g;5.6 以前:

5.6 之后的版本:

三、索引失效情况
1)以%开头的like查询不能使用B-Tree索引
2)数据类型出现隐式转换的时候不会使用索引,如当列是字符型时,where条件需要加上引号,如:
-- last_name 为varchar列,且建有索引
explain select * from actor where last_name = 1\G; -- 将不会使用索引,全表扫描
explain select * from actor where last_name = '1'\G; -- 索引生效3)破坏最左前缀原则
4)若MySQL估计使用索引比全表扫描更慢,则不使用索引。如like模糊查询时返回的记录比例较大可能会出现。
可通过 trace 查看 table_scan 和 index 对应的索引的 rows 和 cost 值,当 表扫描的 cost 小于 index 对应索引的 cost,则会使用表扫描代替索引。
5)用or分割的条件,如果or前的条件的列有索引,后面的列没索引,则涉及的索引都不会被用到。
explain select * from payment where customer_id = 203 or amount = 3.96\G;
-- customer_id 有索引,amount 没索引。最终整个查询都不会使用索引(因为or后面的列没索引,则需要走全表扫描)四、查看索引使用情况
show status like 'Handler_read%';
-- 当索引有效工作时,Handler_read_key 值将很高,该值表示一个行被索引值读取的次数
-- 当 Handler_read_rnd_next 值很高时,表示查询低效,该值表示在数据文件中读取下一行的请求数(一般在大量表扫描中发生)