论文连接: http://arxiv.org/abs/1509.01626
github: https://github.com/zhangxiangxiao/Crepe
数据集:http://goo.gl/JyCnZq
github(Tensorflow): https://github.com/mhjabreel/CharCNN
摘要
本文对字符级卷积网络进行文本分类进行了实证探索。本文构建了几个大规模数据集来展示字符级卷积玩咯可以实现最先进的或者具有竞争力的结果。对传统模型(例如BOW,n-grams和TFIDF变形),和深度学习模型(例如基于词的卷积神经网络和递归神经网络)进行比较。
介绍
- 什么是文本分类:自然语言处理的经典问题,为自由文档分配预定义类别。
文本分类的研究范围:从设计最佳的特征到选择最佳的机器学习分类器进行分类
本文提出之前,几乎所有的文本分类技术都是基于词的,对有序的词组合(例如n-grams)进行简单的统计时效果最佳 - 另一方面,许多研究人员发现卷积网络被用于从原始信号中抽取信息,从计算机视觉到语音识别等。
特别是,用于深度学习研究的早期的时延网络实质上是对序列数据进行卷积网络建模。 - 本文探索将测试文本作为字符级别的原始信号,采用一维卷积神经网络。
对于这篇文章,仅使用分类任务作为一种方式举例说明卷积神经网络理解文本能力。
从历史上看,卷积神经网络通常需要大规模数据集来工作,因此需要构建大规模数据集来进行实验,传统模型和其他的深度学习模型提供了广泛的比较。 - 已有文献表明,卷积神经网络可以直接应用于分布式或离散的词嵌入,而不需要对一门语言在句法和语义结构上的理解。
- 一些工作使用字符级特征来进行语言处理,包括使用带有线性分类器的字符级n-grams,将字符级特征与卷积神经网络集合起来。
卷积神经网络通常是基于词的,在词或词n-grams级别提取字符级忒恶整形成分布式表示。在词性标注和信息检索方面有所改进。 - 这篇文章表明,当训练大规模数据集时,深度卷积神经网络不需要单词的知识,除了先前的研究,卷积神经网络也不需要语言的句法和语义的知识。
这样的工程简化对于可以用于不容语言的一个简单系统来说是至关重要的,不管是否分割成单词,字符都是必要的构成。
仅使用字符进行处理的优点是:
1)自然地学习拼写错误、表情等异常字符的组合
字符级卷积神经网络
ConvNets的设计是模块化的,其中通过反向传播获得梯度以执行优化。
关键模块
这个模块的主要组成是具有简单的一维卷积计算的时间卷积模块(temporal convolutional module)。
- 离散的输入函数:g(x)
--> R
离散的核函数:f(x) -->R
卷积
–>R
R在f(x)和g(x)之间 ,步幅d被定义为欸
,其中c = k - d + 1是偏置常数 - 模型是一组核函数
参数化,称之为权重,
输入集 , 是输入特征,m是输入特征大小
输出集 , 是输出特征,n是输出特征大小
输出 是通过 和 之间的卷积求和来得到 - 训练更深层模型的关键是temporal max-pooling ,计算机神经视觉一维max-pooling模块给出一个离散输入函数
–>R, –>R,
max-pooling函数
--> R
g(x)被定义为:
,其中c = k -d +1 是一个偏移常数
这个池化模块可是ConvNets的训练深度达到6层 - 模型中使用的阈值函数h(x) = max{0,x},使卷积层类似于ReLU。具有128个小批量随机梯度下降SGD,momentum 0.9,initial step size:0.01每3轮减半,持续10次。每一轮采样都是在类之间均与采样固定数量的随机样本,使用Torch实现。
字符量化
- 一个编码字符序列作为输入,通过为输入的语言规定一个大小为m的字母表进行编码,采用1-of-m或者one-hot对字符进行编码。
- 字符序列转换为具有固定长度 ,大小为m的矢量序列。
- 忽视任何超过长度 的向量,任何不在字母表彰的空字符均被量化成全零向量。
- 问题:
字符量化的顺序使反向的,最新读取的字符总是最接近输出的起始位置,容易导致全连接层将权重同最新读取关联 - 所有模型中使用的字母表包含70个字符,包括26个英文字母,10个数字,33个其他字符和新兴字符。非空格字符是:
abcdefghijklmnopqrstuvwxyz0123456789-,;.!?:"’/|_@#$%^&*~`±=<>()[]{} - 对区分大小写的不同字母表的模型进行比较
模型设计
- 模型结构:
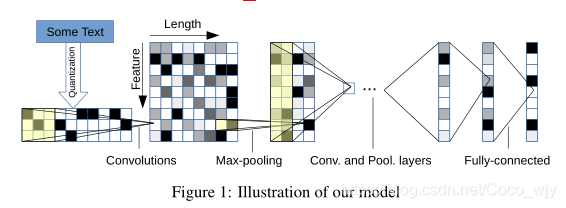
设计两个ConvNets,一大一小。均具有9层深,包括6个卷积层,三个全连接层 - 由于字符量化方法的原因,输入字符特征的数量是70,输入特征长度是1014,1014个字符似乎已经可以捕捉到大部分感兴趣的文本。
- 在三个全连接层之间插入两个dropout模块用以正则化,dropout的概率为0.5
- 卷积层的配置:
步长为1,卷积层非重叠
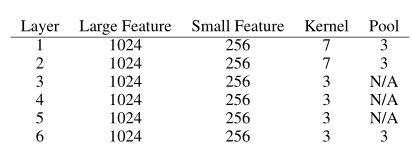
高斯分布初始化权重,平均值和标准差初始化大小模型,大模型(0,0.02),小模型(0,0.05) - 全连接层的配置:
最后一层全连接的输出单元数由问题来决定,比如,10-分类 分类问题,就是10

不同问题的输入长度不同,frame length也不同。在本文的模型设计中,被给定的输入长度是 ,输出frame length在最后一个卷积层之后(任一全连接层之前)是 ,第一个全连接的输入维度是最后一个卷积层输出的frame length乘以第6层的frame size
使用同意词库对数据进行替换
- 研究者发现适当的数据增强在控制深度学习模型的泛化错误上是有效的。当找到模型应该具有的适当的不变性性能时,数据增强技术通常是有效的。
- 就文本而言,使用图像、语音识别中的信号转换的数据增强方式是不合理的,因为字符的确切顺序会形成严谨的句法和语义。
- 数据增强的最佳方法:
人工对句子进行改写
缺点:
对于数据集中大量的样本来说,这个方法非常的不现实且价格昂贵
所以:
使用同义词对单词或者短语进行替换,单词、短语的每一个同义词按语义的接近度排序常见含义 - 有多少个单词被替换?
从给定的文本提取所有可替换单词并且随机选择它们其中的r个被替换。数字r的概率由参数p的几何分布决定的,其中 ,给定一个单词选择同义词的索引s也是由另一个集合分布决定的, 。当选择同义词与最常见的含义相差甚远时,所选同义词的概率也会随之降低,这种新的数据增强方法的p = 0.5,q=0.5。
模型比较
传统模型
传统模型是指使用人工制作的特征抽取器和一个线性分类器。所有这些模型中都采用多项逻辑回归4
bag-of-words and its TFIDF
对于每个数据集,从训练子集中选择50000个出现频率最大的单词构建BOW。对于正常的BOW,每一个单词的计数作为特征,而TFIDF,用计数作为词频。
逆文档频率是:
样本总数与训练自己中带有单词的样本数量的除法的对数。通过划分最大特征值来标准化特征。
Bag-of-ngrams and its TFIDF
Bag-of-ngrams模型是从每一个数据集的训练子集中选取500000个出现最频繁的n-grams来构建的,特征值与词袋模型中的相同
Bag-of-means on word embedding
本实验模型使用从每一个数据集的训练子集学习的word2vec上的k-means,将其用作理解单词聚类的方法。接受所有训练子集中出现超过5次的单词,嵌入的尺寸为300,bag-of-means的特征与bag-of-words模型中的特征计算方式相同,聚类数为5000
Deep Learning Methods
对基于词的ConvNet和简单的长短时记忆网络(LSTM)递归神经网络模型进行比较。
Word-based ConvNets
基于词ConvNets文本分类在最近的众多研究中其中一点的差异就是选择使用预训练或者端到端学习词表示。本文提供两者在使用预训练wordvec嵌入和使用查询表的比较。两个案例中,embedding size均为300。
为了确保比较的公平性,每个案例均与基于字符的卷积神经网络具有相同的size,就其而言是layers的层数和每一层的输出size。实验也利用词库进行了数据增强
Long-shot term memory
这个模型是通过所有LSTM单元形成一个特征向量再对这个特征向量作多项逻辑回归形成的。输出的维度是512,使用梯度剪裁,其中梯度范数趋近于5


字母表的选择
对于英文字母表,一个明显的选择是是否区分大小写。在做大小写区分时通常会出现比较糟糕的结果,一种可能的解释是,语义不会随着书写方式的不同而改变,因此要进行正则化
大规模数据集和结果
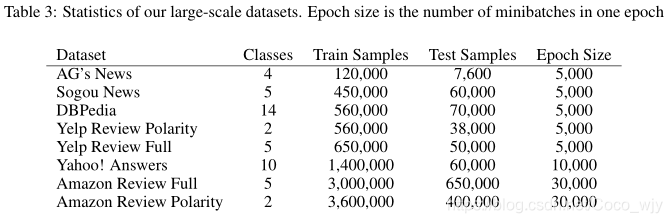
数据统计表
模型数据集的错误测试表
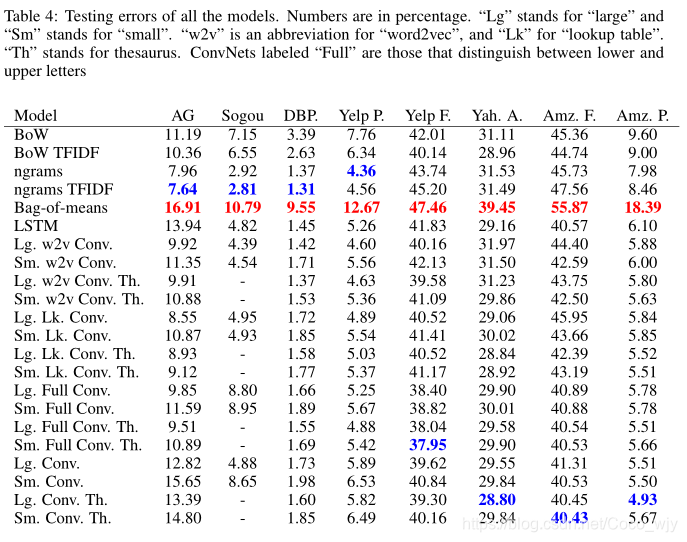
用蓝色标出最好的结果,用红色标出更差的结果。而且没有中文词库,所以Sogou News数据集使用词库进行数据增强没有任何结果。
Discussion
结论:
- 基于字符级ConvNets可以在不需要单词的情况下进行文本分类。这强烈表明语言也可以被认为是一种与任何其他类型无异的信号。
- 较大的数据集字符级ConvNets的效果越好
- 对于字母表来说,百万级数据量时,不区分大小写会更好,有一种可能的解释是存在正则化效应,有待验证
- 擅长识别拼写错误、表情符号等奇异的符号组合,在人为生成的数据上效果较好
- 字符级ConvNets分类时,与语义无关
- 每一种模型都是适合特定数据集的,做不到一种模型适用于所有数据集