1、目标网站地址:http://sc.chinaz.com/tupian/meinvtupian.html
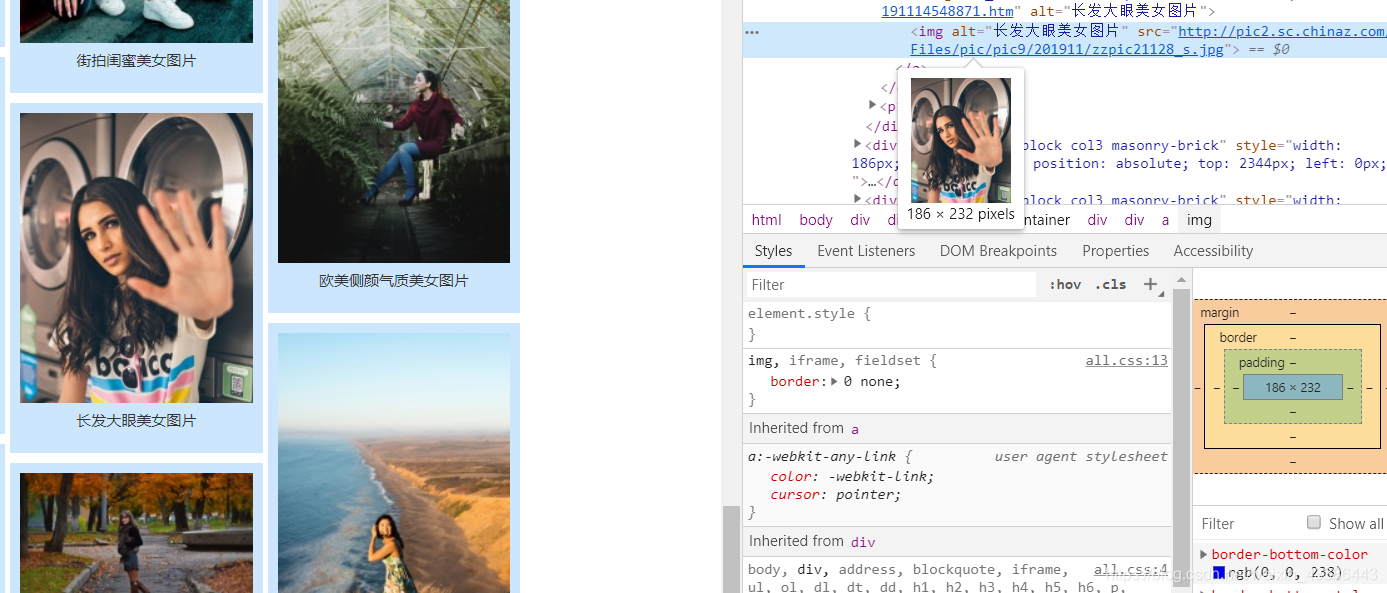
2、分析第2页的url:
3、源码展示:

from lxml import etree
import requests
import urllib.request
imgs = []
#获取图片列表
def getAllsrc(url):
res = requests.get(url)
html = etree.HTML(res.text)
result = html.xpath('//a[@target="_blank"]/img')
for temp in result:
img = temp.attrib.values()[0];
imgs.append(img)
#下载图片-urllib.request-
def downlocal():
num = 0
path = "D:/Temp/images/"
for imgurl in imgs:
num += 1
print("正在下载第 "+str(num)+" 个图像")
try:
urllib.request.urlretrieve(imgurl, '{0}{1}.jpg'.format(path, num)) # 打开imgList,下载图片到本地
except BaseException:
pass
print('图片下载完成,注意查看文件夹')
#这个太慢了
def downlocal2():
num = 0
for imgurl in imgs:
num += 1
path = "D:/Temp/images/"+str(num)+'.jpg'
r = requests.get(imgurl)
try:
with open(path,'wb') as f:
f.write(r.content)
print("正在下载第 "+str(num)+" 张图")
except BaseException:
pass
print('图片下载完成,注意查看文件夹')
#主入口
if __name__ == "__main__":
for i in range(68):
if(i==0):
tempsrc = 'http://sc.chinaz.com/tupian/meinvtupian.html'
else:
tempsrc = 'http://sc.chinaz.com/tupian/meinvtupian_'+str(i)+'.html'
i += 1;
getAllsrc(tempsrc)
#调用
downlocal()
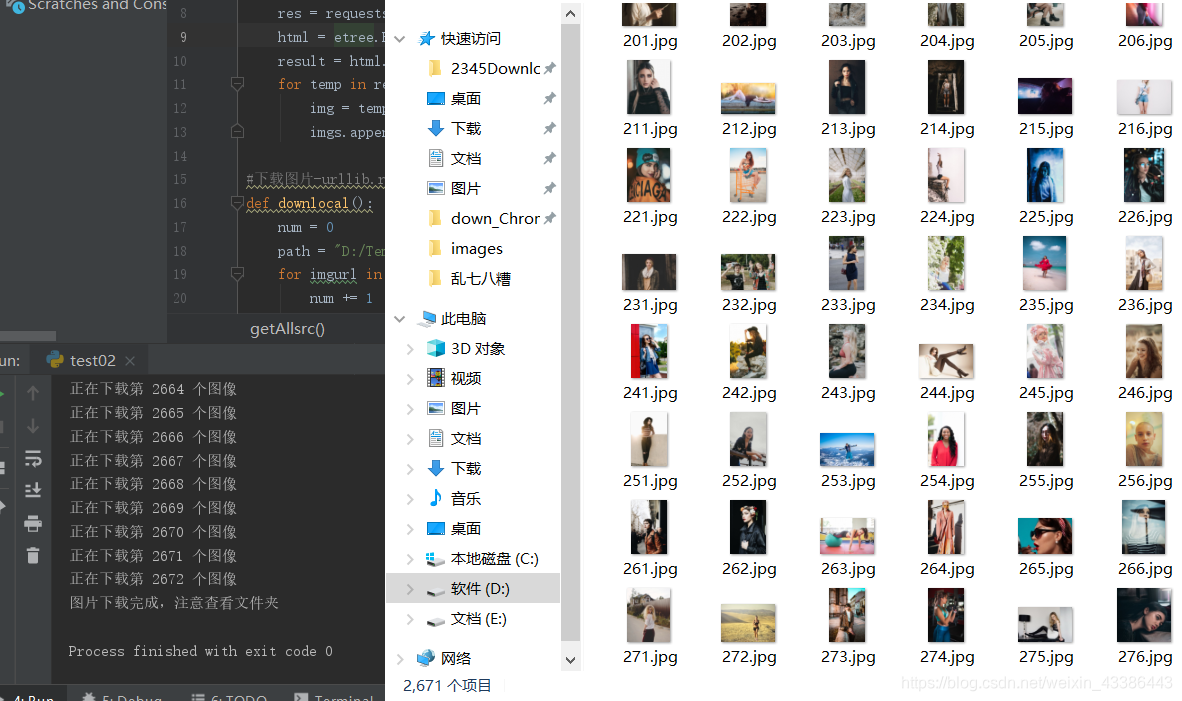
4、效果图: