运行环境python3.0+效果如下
1. 获取首页图片列表
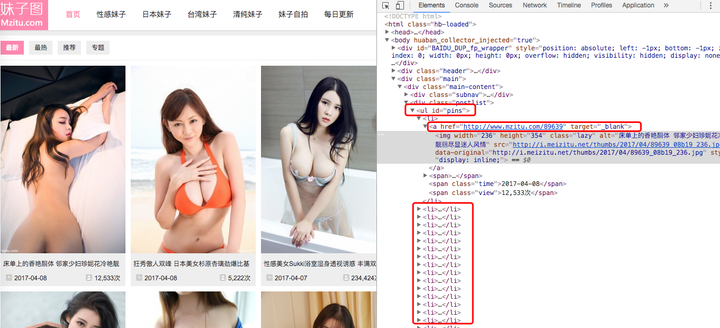
打开网站看看,进入详情页的链接是放在li标签的a标签中,很好,这里结构比较简单,有前几节课程的基础的话应该很快能获取到图片链接列表,我们先把这一块链接抓下来
# coding:utf-8
import requests
from lxml import html
# 获取主页列表
def getPage():
baseUrl = 'http://www.mzitu.com/'
selector = html.fromstring(requests.get(baseUrl).content)
urls = []
for i in selector.xpath('//ul[@id="pins"]/li/a/@href'):
urls.append(i)
return urls
if __name__ == '__main__':
urls = getPage()
for url in urls:
print url
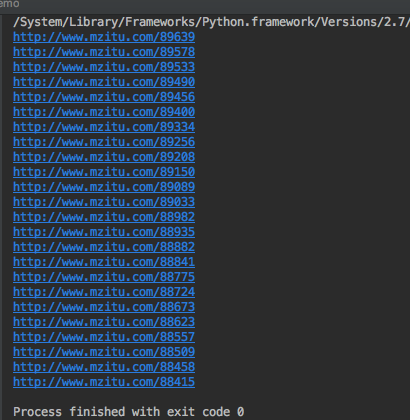
运行结果,点进去一个链接应该就是每个主题的详情页
比较基础就不多解释了,我们继续开车,哦不,继续学习
2. 详情页处理
详情页的处理,我们应该先思考需要提取出什么,首先是标题吧,我们可以拿标题当文件夹名字,嗯想法可以的,接着呢,接着肯定是图片主体是吧,就要找到图片的链接,才能下载,最后网站的分页规则也是写在URL中了,所以我们还要知道这个主题到底有多少页内容
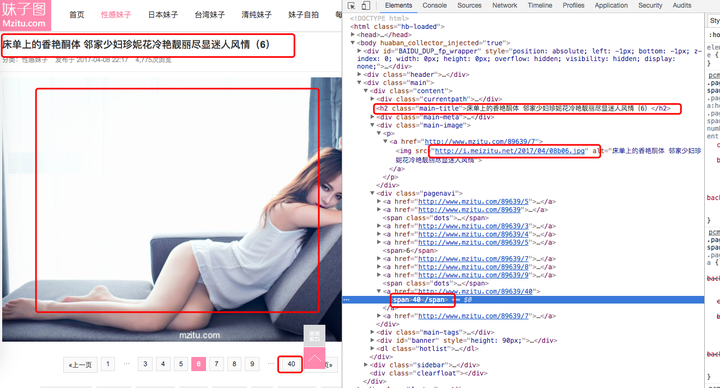
看看底下的分页栏里,在一堆的a标签里头,最后一页的页码是在“下一页”的前一项,“下一页”又是最后一项,那就把倒数第二项抓出来就好伐!
# 图片链接列表,标题
# url是详情页链接
def getPiclink(url):
sel = html.fromstring(requests.get(url).content)
# 图片总数 倒数第二项里
total = sel.xpath('//div[@class="pagenavi"]/a[last()-1]/span/text()')[0]
# 标题
title = sel.xpath('//h2[@class="main-title"]/text()')[0]
# 接下来的链接放到这个列表
jpgList = []
for i in range(int(total)):
# 每一页
link = '{}/{}'.format(url, i+1)
s = html.fromstring(requests.get(link).content)
# 图片地址在src标签中
jpg = s.xpath('//div[@class="main-image"]/p/a/img/@src')[0]
# 图片链接放进列表
jpgList.append(jpg)
return title, jpgList
这个函数返回标题和图片地址的列表,标题可以用来当文件夹名称,然后图片地址用作下载
3. 图片下载
好了,到了亦可赛艇的一步了,下载图片和上节里下载文字到本地txt文件实质一样,用requests请求图片地址,返回一个二进制内容(content),再写入到本地.jpg文件中
import os
# 下载图片
# 因为上面函数返回的两个值,这里我们直接传入一个两个值tuple
def downloadPic((title, piclist)):
k = 1
# 图片数量
count = len(piclist)
# 文件夹格式
dirName = u"【%sP】%s" % (str(count), title)
# 新建文件夹
os.mkdir(dirName)
for i in piclist:
# 文件写入的名称:当前路径/文件夹/文件名
filename = '%s/%s/%s.jpg' % (os.path.abspath('.'), dirName, k)
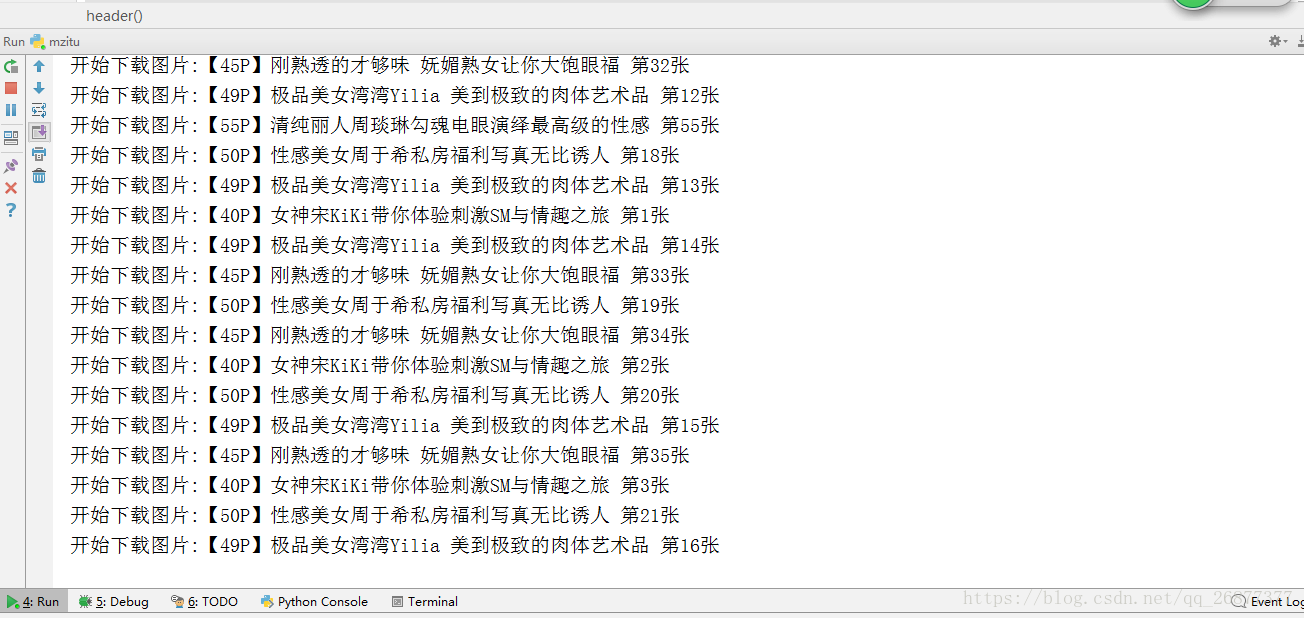
print u'开始下载图片:%s 第%s张' % (dirName, k)
with open(filename, "wb") as jpg:
jpg.write(requests.get(i).content)
time.sleep(0.5)
k += 1
好了,运行以下

好像成功了,好粗暴的名字啊哈哈哈哈
4. 最后
考虑到首页的分页(也是写在URL中),优化一下代码:
# coding:utf-8
import requests
from lxml import html
import os
import time
# 获取主页列表
def getPage(pageNum):
baseUrl = 'http://www.mzitu.com/page/{}'.format(pageNum)
selector = html.fromstring(requests.get(baseUrl).content)
urls = []
for i in selector.xpath('//ul[@id="pins"]/li/a/@href'):
urls.append(i)
return urls
# 图片链接列表, 标题
# url是详情页链接
def getPiclink(url):
sel = html.fromstring(requests.get(url).content)
# 图片总数
total = sel.xpath('//div[@class="pagenavi"]/a[last()-1]/span/text()')[0]
# 标题
title = sel.xpath('//h2[@class="main-title"]/text()')[0]
# 接下来的链接放到这个列表
jpgList = []
for i in range(int(total)):
# 每一页
link = '{}/{}'.format(url, i+1)
s = html.fromstring(requests.get(link).content)
# 图片地址在src标签中
jpg = s.xpath('//div[@class="main-image"]/p/a/img/@src')[0]
# 图片链接放进列表
jpgList.append(jpg)
return title, jpgList
# 下载图片
def downloadPic((title, piclist)):
k = 1
# 图片数量
count = len(piclist)
# 文件夹格式
dirName = u"【%sP】%s" % (str(count), title)
# 新建文件夹
os.mkdir(dirName)
for i in piclist:
# 文件写入的名称:当前路径/文件夹/文件名
filename = '%s/%s/%s.jpg' % (os.path.abspath('.'), dirName, k)
print u'开始下载图片:%s 第%s张' % (dirName, k)
with open(filename, "wb") as jpg:
jpg.write(requests.get(i).content)
time.sleep(0.5)
k += 1
if __name__ == '__main__':
pageNum = input(u'请输入页码:')
for link in getPage(pageNum):
downloadPic(getPiclink(link))
6. Update
根据反爬虫的修改,增加下载图片的headers就好了
def header(referer):
headers = {
'Host': 'i.meizitu.net',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/59.0.3071.115 Safari/537.36',
'Accept': 'image/webp,image/apng,image/*,*/*;q=0.8',
'Referer': '{}'.format(referer),
}
return headers
下载链接
with open(filename, "wb+") as jpg:
jpg.write(requests.get(jpgLink, headers=header(jpgLink)).content)
全部代码:
# coding:utf-8 import requests from lxml import html import os import time from multiprocessing.dummy import Pool as ThreadPool def header(referer): headers = { 'Host': 'i.meizitu.net', 'Pragma': 'no-cache', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6', 'Cache-Control': 'no-cache', 'Connection': 'keep-alive', 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/59.0.3071.115 Safari/537.36', 'Accept': 'image/webp,image/apng,image/*,*/*;q=0.8', 'Referer': '{}'.format(referer), } return headers # 获取主页列表 def getPage(pageNum): baseUrl = 'http://www.mzitu.com/page/{}'.format(pageNum) selector = html.fromstring(requests.get(baseUrl).content) urls = [] for i in selector.xpath('//ul[@id="pins"]/li/a/@href'): urls.append(i) print(i) return urls # 图片链接列表, 标题 # url是详情页链接 def getPiclink(url): sel = html.fromstring(requests.get(url).content) # 图片总数 total = sel.xpath('//div[@class="pagenavi"]/a[last()-1]/span/text()')[0] # 标题 title = sel.xpath('//h2[@class="main-title"]/text()')[0] # 文件夹格式 dirName = u"【{}P】{}".format(total, title) # 新建文件夹 os.mkdir(dirName) n = 1 for i in range(int(total)): # 每一页 try: link = '{}/{}'.format(url, i+1) s = html.fromstring(requests.get(link).content) # 图片地址在src标签中 jpgLink = s.xpath('//div[@class="main-image"]/p/a/img/@src')[0] # print(jpgLink) # 文件写入的名称:当前路径/文件夹/文件名 filename = '%s/%s/%s.jpg' % (os.path.abspath('.'), dirName, n) print(u'开始下载图片:%s 第%s张' % (dirName, n)) with open(filename, "wb+") as jpg: jpg.write(requests.get(jpgLink, headers=header(jpgLink)).content) n += 1 except: pass if __name__ == '__main__': pageNum = input(u'请输入页码:') p = getPage(pageNum) with ThreadPool(4) as pool: pool.map(getPiclink, p)