爬取流程
- 从煎蛋网妹子图第一页开始抓取;
- 爬取分页标签获得最后一页数字;
- 根据最后一页页数,获得所有页
URL; - 迭代所有页,对页面所有妹子图片
url进行抓取;访问图片URL并且保存图片到文件夹。
开始
通过上一篇文章的爬取过程,我们基本上理解了抓取一个网站的大致流程。因为一个网站虽然有很多页,但是大部分网站每一页的HTML标签内容都是相同的。我们只要获取到一页的内容,就可以获得所有页的内容了。那么开始之前,我们来分析一下煎蛋网妹子图页面的URL。
第一页的 url:http://jandan.net/ooxx/page-1
第二页:http://jandan.net/ooxx/page-2
最后一页:http://jandan.net/ooxx/page-49
不难发现,煎蛋网的 url 的规律是比较简单的,每一页后面 page 的数字就是几。那么我们可以通过一个循环就可以获得所有的页面 URL 了。但是大家应该想到,这个网站每天都会更新,
所以我们需要通过页面的标签信息让程序自己获得页数,我们访问http://jandan.net/ooxx/这个页面时,就相当于我们直接访问了最后一页。大家可以自己试试看。
爬虫首先第一步就是分析网站 像我现在这种小白 一般就f12还有右键查看源代码就ok了
还有一点 requests返回的是右键源代码那个文件

里面很多东西是没有的 所以就需要兄弟你去分析了
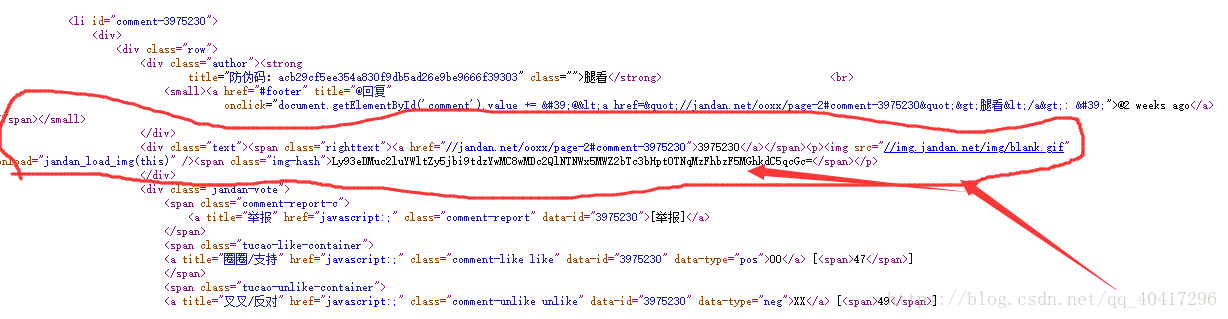
这就是我分析出来的我们需要的东西,然后我们就爬取这个
但是上面给我们的地址并不能访问
因为他是通过base64加密了
Base64编码是一种“防君子不防小人”的编码方式。广泛应用于MIME协议,作为电子邮件的传输编码,生成的编码可逆,后一两位可能有“=”,生成的编码都是ascii字符。
优点:速度快,ascii字符,肉眼不可理解
缺点:编码比较长,非常容易被破解,仅适用于加密非关键信息的场合

在python中调用base64库就可以了
import base64
s="Ly93dzMuc2luYWltZy5jbi9tdzYwMC8wMDZYTkVZN2d5MWZ2a2Z3bnBkNGlqMzE4dTFrd2FvZy5qcGc="
w=base64.b64decode(s)
print(w)
不多说了我直接上代码 读者可以直接使用 就可以爬煎蛋上面的妹子图片了
from bs4 import BeautifulSoup
import requests
import os #文件操作模块
import base64
import lxml
def makefile(str):
path1=os.getcwd()#获取当前目录位置
print("当前目录位置: "+path1)
path1=path1+"//"+str
if not os.path.isdir(path1):
print("当前路径不存在文件夹 "+str)
os.mkdir(str)
print("创建"+str+"photo文件夹成功")
else :
print("前路径存在文件夹 "+str)
print("前路径存在路径 "+path1)
return path1
def downphoto(netadress,localadress):
# print(os.getcwd())
# z="D:\\Python程序\\煎蛋photo\\"
z=os.getcwd()+"\\煎蛋photo\\"
# print(z)
# print("--------------------\n")
# print(z1)
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"}
re=requests.get(netadress,headers=headers)
lo=z+netadress.split("/")[4]
f= open(lo,"wb")
f.write(re.content)
f.close()
def test(NextUrl,localadress):
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"}
url = NextUrl #"https://movie.douban.com/top250"
f = requests.get(url,headers=headers,timeout=5)
# print(f.content)
# print("--------------------------\n")
soup = BeautifulSoup(f.content, "lxml")
# print(soup)
#####获取图片url
# print("--------------------------\n")
qq=soup.find_all("span",class_="img-hash")
# print(soup.title)
ImgUrl=[]
for i in qq:
ImgUrl.append(str(i))
# print(i)
del qq
temp=[]
for i in ImgUrl: #
uu=base64.b64decode(((i.split(">"))[1]).split("<")[0])#解码base64
ww=uu.decode("utf-8")
temp.append("http:"+ww)
for i in temp:
print("iii: *"+i+"\n")
downphoto(i,localadress) #调用下载图片函数
path1=makefile("煎蛋photo")+"\\"
for i in range(49):
try:
url="http://jandan.net/ooxx/page-"+(str)(i+1)+"#comments" #http://jandan.net/ooxx http://jandan.net/ooxx/page-41#comments
test(url,path1)
except Exception :
pass