总体思路:
1.拿到数据后,首先查看数据基本情况,筛选需要的列。
2.进行数据预处理:数据去重、缺失值处理、异常值处理【该案例中'price'列需要进行格式清晰与数据类型转换】
3.建模与评估:首先需要对数据进行Z-score标准化,然后进行训练集与测试集的划分,用训练集训练模型,用测试集预测和对模型评估。
新知:
【数据格式清洗】
模版:
DataFrame['target_col'] = DataFrameDataFrame['target_col'].str.replace('old str', 'new str').astype(data_type)
【异常值的判断标准】
标准分判断(Zscore)
标准分:衡量数据距离均值多少个标准差;公式:(xi - xmean) / xstd
经验法则:约68%的数据位于距离均值1标准差范围内;约95%数据位于距离均值2标准差范围内;几乎全部数据位于距离均值3标准差范围内
模版:
z_score = (DataFrame['target_col'] - DataFrame['target_col'].mean()) / DataFrame['target_col'].std()
drop_index = DataFrame[z_score.abs() > 3].index
DataFrame.drop(drop_index, inplace = True)
【对数据进行Zscore标准化】
目的是为了去量纲
标准化所在库: from sklearn.preprocessing import StandardScaler
模版: DataFrame[target_cols] = StandardScaler().fit_transform(DataFrame[target_cols])
【回归模型的评估标准】
回归模型常使用均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)进行评估,三个指标的值越小越好
注意:分类模型和回归模型使用的评估方法不同,不能混用!


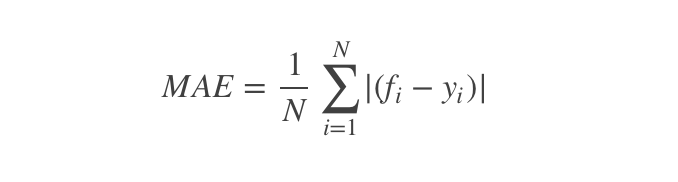
模型评估所在库: sklearn.metrics
模版:
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error
print(mean_squared_error(y_test, y_predict))
print(pow(mean_squared_error(y_test, y_predict), 0.5))
print(mean_absolute_error(y_test, y_predict))
print(r2_score(y_test, y_predict)) # R方值