一、KNN算法概述
kNN分类算法本身简单有效,既可以分类又可以进行回归。
核心原理:已知样本数据集的每一个数据的特征和所属的分类,将新数据的特征与样本数据进行比较,找到最相似(最近邻)的K(k<=20)个数据,选择K个数据出现次数最多的分类,作为新数据的分类。
简而言之: 物以类聚,人以群分
二、举例:
如下图所示:
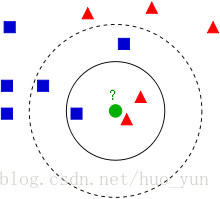
蓝色方块和红色三角是已知类别,绿色圆圈是我们的待测数据,需要对它进行分类。
如果K=3,绿色圆点的最近3个邻居是2个红色三角和1个蓝色方块,所以少数服从多数,绿色圆点属于三角形这一类。
如果k=5,绿色圆点的最近5个林俊是2个红色三角和3个蓝色,所以绿色圆点属于蓝色这一类。
距离计算:
比较常用的距离计算方法为欧式距离。欧式距离:样本 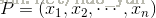
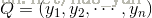
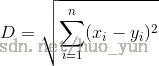
三、算法流程:
- 计算已知类别数据集中的点与当前点的距离
- 按照距离依次排序
- 选取当前点距离最小的k个点
- 确定前K个点所在类别的出现概率
- 返回当前K个点出现频率最高的类别作为当前点预测分类
四、代码实现:
# 计算待测点与样本点的距离
def classify0(inX, dataSet, lables, k):
dataSetSize = dataSet.shape[0]
diffmat = tile(inX, (dataSetSize, 1)) - dataSet # 将待测的点转换成与样本数据相等行数的矩阵,然后再与样本数据的矩阵进行相减
sqDiffMat = diffmat ** 2 # 将样本点与待测点的差值进行平方和计算
sqDistances = sqDiffMat.sum(axis=1) # 计算两点之间的距离和
distances = sqDistances ** 0.5 # 对和进行开根运算
sortedDistIndicies = distances.argsort() # 对两点间的距离进行从小到大排序
# print sortedDistIndicies
classCount = {}
for i in range(k):
# 选择距离最小的k个点
volteIlabel = lables[sortedDistIndicies[i]]
classCount[volteIlabel] = classCount.get(volteIlabel, 0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]五、总结
优点
KNN 算法本身简单有效,它是一种lazy-learning 算法。不需要使用训练集进行训练,训练时间复杂度为0。
缺陷:
计算复杂度高:需要与每一个样本数据计算距离,所以KNN的分类时间复杂度为O(n),与样本总数成正比。
K值的设定:K值的选取对算法的结果影响很大,如果K设置过小会降低分类精度,如果K值设置过大,且测试样本属于训练集中包含数据较少的类,则会增加噪声,降低分类效果。通常,K值的设定采用交叉检验的方式(以K=1为基准,且K<=20)经验规则:K一般低于训练样本数的平方根。
数据样本不平衡情况下导致误差较大:当样本不平衡时,如一个样本的容量很大,而其他样本容量很小时,有可能导致输入一个新样本时,该样本的K个邻居中大容量的样本占多数。解决:不同的样本给予不同权重项。