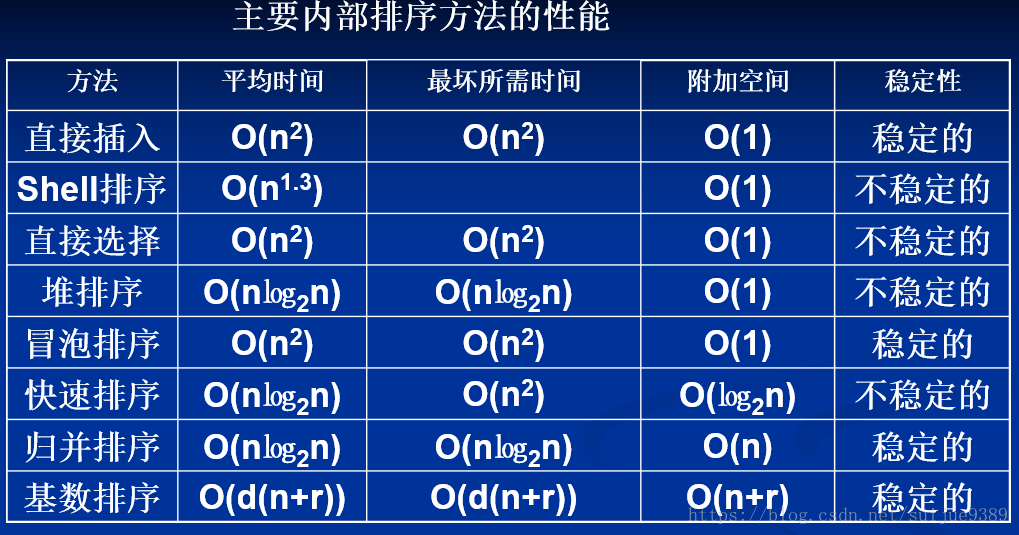
1.排序算法的稳定性:如果序列中两个元素相等,排序后两个元素的相对顺序不变,则称所用的排序方法是稳定的,反之,是非稳定的。(有人会说,两个元素相等为什么还考虑相对顺序? 在单一属性元素的排序中确实不重要,但在结构体数据的排序中,算法的稳定性很重要),一般来说,若存在不相邻元素间交换,则很可能是不稳定的排序。
2.算法的复杂度:一个算法的质量优劣将影响到算法乃至程序的效率,主要从时间复杂度和空间复杂度两个维度考虑。
(算法的复杂度一般表示的是平均复杂度,但有的算法平均复杂度不好求取,可以求取最坏情况时的复杂度和最好情况时的复杂度,两者平均近似平均复杂度,时间复杂度分析主要分析比较次数和移动次数)
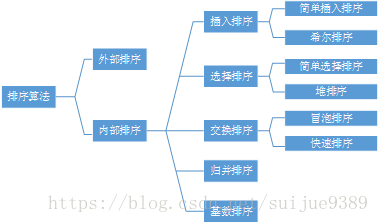
3.排序算法分类
排序原则分类:内部排序算法主要包括 插入排序、交换排序、选择排序、归并排序和基数排序等五类
排序时间复杂度分类:1)简单的排序方法,时间复杂度O(n2)
2)先进的排序方法,时间复杂度O(nlogn)
3)基数排序,时间复杂度O(d*n)
排序算法很多,但并不存在一种最好的方法适用于各种情况下,每种算法都有优缺点,有它适合的使用场景。一般来说,选择使用哪种排序,具有以下的经验。
经验:一般来说,1)当数据规模较小或数据基本有序时,应选择简单排序(直接插入排序、冒泡排序和简单选择排序),因为任何排序算法在数据量小时基本体现不出来差距。
2)考虑数据的类型,比如如果全部是正整数,那么考虑使用基数序为最优。
3)从平均性能而言,快速排序最佳,时间最省,但快速排序在最坏情况下的时间性能不如堆排序和归并排序。
1.插入排序
1).简单插入排序
简单插入排序时最简单的排序方法,一次插入排序是指将一个记录插入到已经排序好序的有序表中,从而得到一个新的,记录加一的有序表
C++核心程序:
void sort_insert(int *a,int n)
{ int temp=0; //辅助空间 O(1)
for(int i=1;i<=n-1;i++)//长度为n的序列需要进行n-1次直接插入排序
{
if(a[i]<a[i-1])
{
temp=a[i];
a[i]=a[i-1];
int j=0;
for(j=i-2;a[j]>temp&&j>=0;j--)
{
a[j+1]=a[j];
}
a[j+1]=temp;
}
}
}
时间复杂度分析:数据序列是正序时,比较次数为n-1,移动次数为0,时间复杂度为O(n)
数据序列是逆序时,比较次数为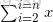
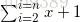
平均一下,时间复杂度为O(n2)
空间复杂度分析:O(1)
直接插入排序的过程中,不需要改变相等数值元素的位置,所以它是稳定的算法
2).希尔排序
直接插入排序具有以下特点,a)在数据量比较少时,效率比较高
b)在数据基本有序时,效率比较高
希尔排序就是从这两点出发对直接插入排序进行的改进,又称“缩小增量排序”
C++核心程序:
void shellinsert(int *a,int n,int dk)
{ int temp=0; //辅助空间 O(1)
for(int i=dk;i<=n-1;i++)//长度为n的序列需要进行n-1次直接插入排序
{
if(a[i]<a[i-dk])
{
temp=a[i];
a[i]=a[i-dk];
int j=0;
for(j=i-dk;a[j]>temp&&j>=0;j-=dk)
{
a[j+dk]=a[j];
}
a[j+dk]=temp;
}
}
}
void sort_shellinsert(int *a,int n,int *dk,int m)
{ //a 待排序数组地址,n 数组长度
//dk 增量数组地址, m 增量数组长度,最后一个增量为1
for(int i=0;i<m;i++)
{
shellinsert(a,n,dk[i]);
}
}
时间复杂度分析:因为时间复杂度与增量选取有关,分析起来比较复杂
空间复杂度分析:O(1)
希尔排序中相等数据可能会交换位置,所以希尔排序是不稳定的算法
2.选择排序
1).简单选择排序
一次简单的选择排序操作为:通过n-i次关键字的比较,从n-i+1个记录中选出关键字最小(大)的记录,并和第i个记录交换。
C++核心程序:
void sort_choose(int *a,int n)
{
int temp;
for(int i=0;i<n-1;i++)//外侧循环
{
int index=i;
for(int j=i+1;j<n;j++)
{
if(a[j]<a[index])
{
index=j;//最小值下标
}
}
temp=a[index];//交换数据
a[index]=a[i];
a[i]=temp;
}
}
时间复杂度分析:不论数据序列是正序还是逆序,比较次数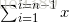
空间复杂度分析:O(1)
简单选择排序的过程中,不需要改变相等数值元素的位置,所以它是 稳定的算法2).堆排序
堆排序是在简单选择排序基础上改进的,为建少比较次数,采用堆形结构存储数据,当想得到一个序列中前k个最小的元素的部分排序序列,最好采用堆排序
堆的定义如下:举例来说,对于n个元素的序列{S0, S1, ... , Sn}当且仅当满足下列关系之一时,称之为堆:
(1) Si <= S2i+1 且 Si <= S2i+2 (小顶堆)
(2) Si >= S2i+1 且 Si >= S2i+2 (大顶堆)
已知叶子节点序号为i,则根节点序号为 i/2-1
堆排序主要包括2个操作:a) 由无序数据建立一个堆序列
b) 输出堆顶元素后,在将剩余元素调整为堆序列
堆排序的详细介绍可以参考:http://www.cnblogs.com/jingmoxukong/p/4303826.html
C++核心代码:
void heap_adjust(int arr[], int i, int n)
{
int j = i * 2 + 1;//子节点
while (j<n)
{
if (j+1<n && arr[j] > arr[j + 1])//子节点中找较小的
{
j++;
}
if (arr[i] < arr[j])
{
break;
}
swap(arr[i],arr[j]);
i = j;
j = i * 2 + 1;
}
}
void makeheap(int arr[], int n)//建堆
{
int i = 0;
for (i = n / 2 - 1; i >= 0; i--)//((n-1)*2)+1 =n/2-1
{
heap_adjust(arr, i, n);
}
}
void HeapSort(int arr[],int len)
{
int i = 0;
makeheap(arr, len);
for (i = len - 1; i >= 0; i--)
{
swap(arr[i], arr[0]);
heap_adjust(arr, 0, i);
}
}
时间复杂度分析:因为堆排序的时间复杂度是O(n+klog2n),若k≤n/log2n,则可得到的时间复杂度为O(n)
空间复杂度分析:O(1)
堆排序中相等数据可能会交换位置,所以堆排序是不稳定的算法
3.交换排序
1)冒泡排序
第i趟冒泡排序是指第1个元素到第n-i+1个元素之间两两比较,若为逆序则交换顺序
排序结束的标志是在某一趟排序中无数据交换顺序。
C++核心程序:
void sort_pop(int *a,int n)
{
int temp;
int flag=1;//排序结束表示
for(int i=0;i<n-1&&flag;i++)//flag==0,排序结束
{
flag=0;
for(int j=i;j<n-i-1;j++)
if(a[j]>a[j+1])
{ flag=1;
temp=a[j+1];
a[j+1]=a[j];
a[j]=temp;
}
}
}
2)快速排序
快速排序是对冒泡排序的一种改进,基本思想是通过一趟排序将序列分割为两个独立的部分,其中一部分序列均比另一部分小,在分别对两部分独立的序列进行快速排序,最后达到序列正序
C++核心程序:
int partition(int *a,int low,int high)
{
int temp=a[low];
while(low<high)
{
while(low<high&&a[high]>=temp)
high--;
a[low]=a[high];
while(low<high&&a[low]<=temp)
low++;
a[high]=a[low];
}
a[low]=temp;
out(a,10);
return low;
}
void sort_quick(int *a,int low,int high)
{
int p=0;
if(low<high)
{
p=partition(a,low,high);
sort_quick(a,low,p-1);
sort_quick(a,p+1,high);
}
}
时间复杂度分析:数据越随机分布时,快速排序性能越好;数据越接近有序,快速排序性能越差,最好情况下O(nlogn),最坏情况下退化为冒泡排序O(n2)
空间复杂度分析:O(nlogn)
在快速排序中,相等元素可能会因为分区而交换顺序,所以它是不稳定的算法