前言
这里和前面不同的是我把标题进行了修改。有人可能会问,同样是排序为什么去掉了排序两个字呢?这是因为,排序只是堆的一种应用。而堆作为一个数据结构,在很多应用场景下都有它的身影。
二叉堆
二叉堆必须为一棵完全二叉树,即叶节点只能出现在最下层和次下层,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树。如图所示:
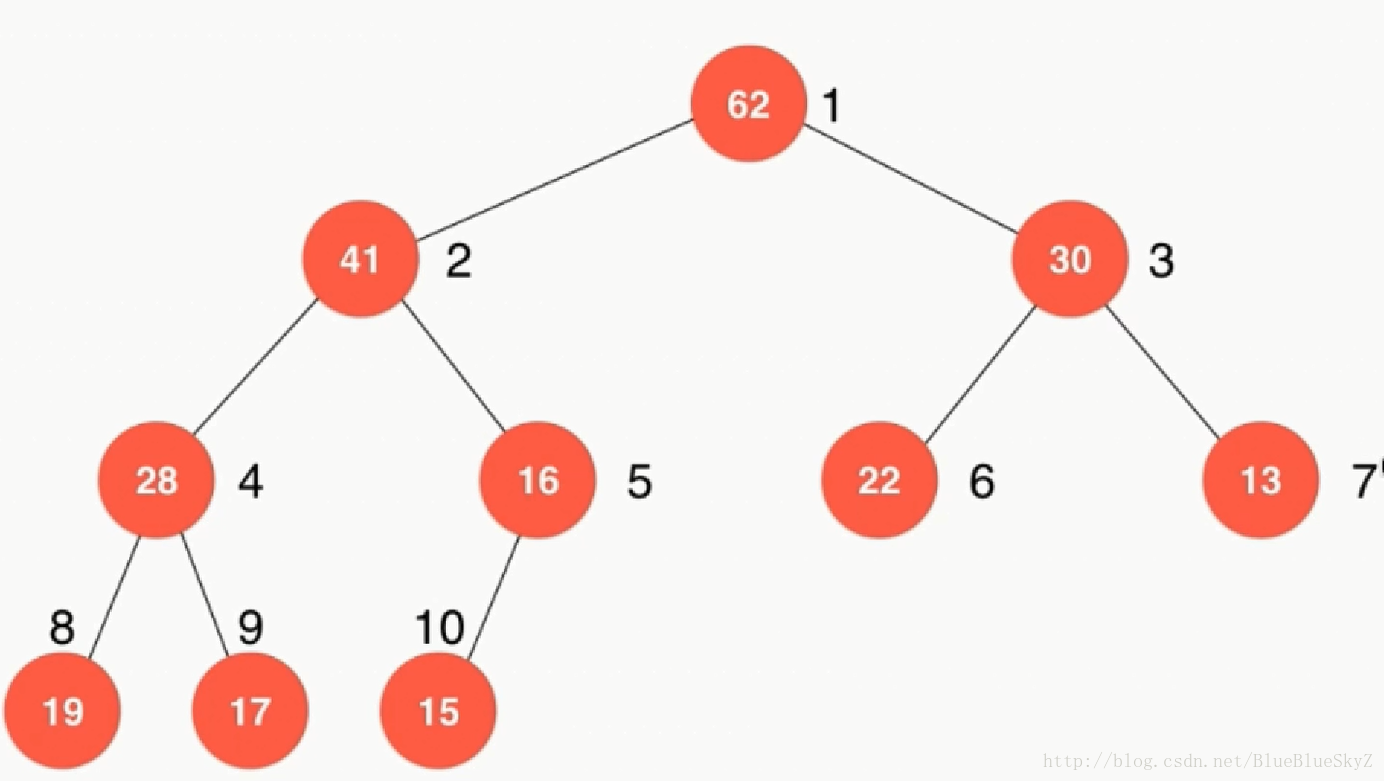
与此同时,大家还应该能看出它的第二个性质,即任意节点的值都不大于其父节点的值。当然,这里必须指出的是,这是最大堆,与之相对应的就是最小堆,大家也很容易就理解其定义,维基定义是根结点的键值是所有堆结点键值中最小者的堆。
当然,二叉堆只是堆的一种特殊情况,其实最根本的形式是d叉堆,只是叶子节点的个数发生了改变。
堆排序
原理
我们通过上面二叉堆的解释可以看出,根节点是最大(小)值,所以我们可以通过取出根节点,然后重新维护整个堆让其继续保持最大(小)堆的性质,达到排序的目的。
这里我们使用数组的方式进行维护堆,如上图所示,我们很容易就从上到下对这些数字进行标记,这样我们就可以使用数组的索引进行操作了。而且最大堆的这些索引之间有一定的数学逻辑,我们假设父节点的索引为k,那么:
- 左叶子结点的索引为2*k
- 右叶子结点的索引为2*k+1
需要注意的是,我们的索引是从1开始的,如果是从0开始的,那么其中的关系是不同的。同时我们可以注意到,虽然父节点不小于子节点,但是并不保证左边一定小于右边,下面一层的一定小于上面一层的数,这点我们之后实现的时候会注意到。
代码实现
我们需要定义一个类MaxHeap类,其中需要有数组的指针,现在存放的数量和容量三个属性,与此同时还需要保存维护堆的方法。
其中shiftUp是当我们插入一个数据时,将其放入正确的位置。因为之前提到的,子节点一定比父节点小,但是左右大小不定,上下大小也不定,所以我们只需要对父节点进行比较即可。如图所示:

shiftDown是取出元素时,对堆进行维护。一般我们只会取出根节点,因为只有这里是确定为整个堆的最大值。取出根节点之后,我们将最后一个数字放到根节点,这样就保证是一棵完全二叉树。同样因为上面的性质,我们必须对左右两个子节点进行比较,保证与较大的子节点进行交换,这样才能保证最大堆的性质。
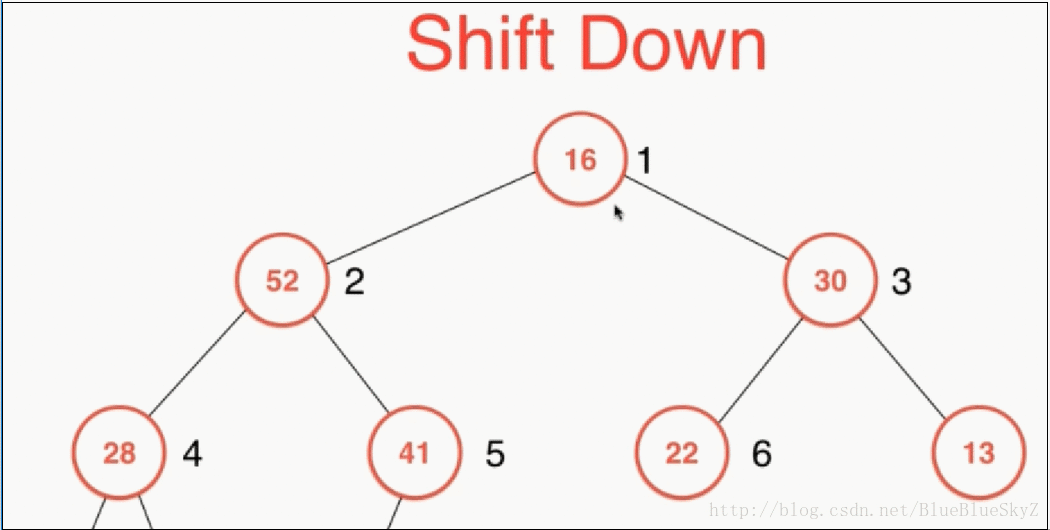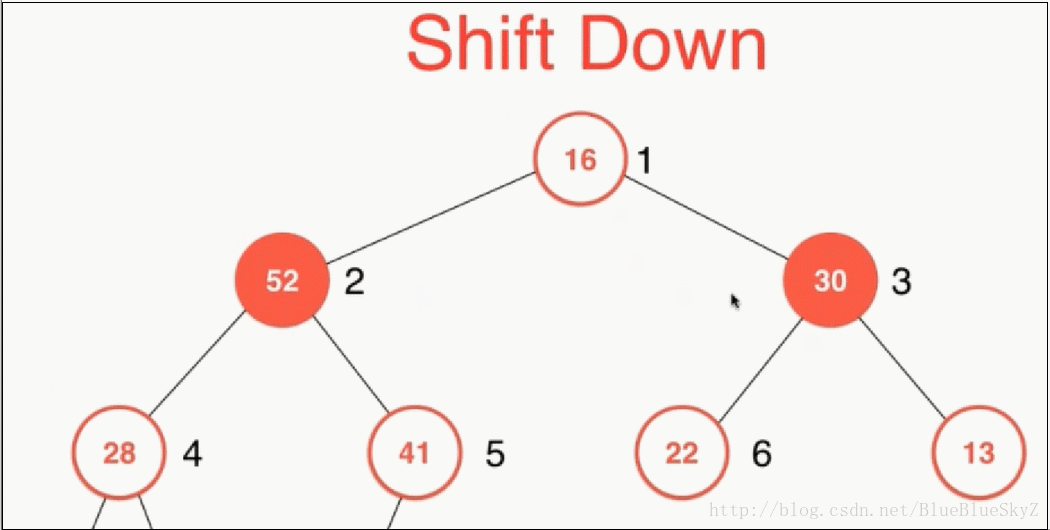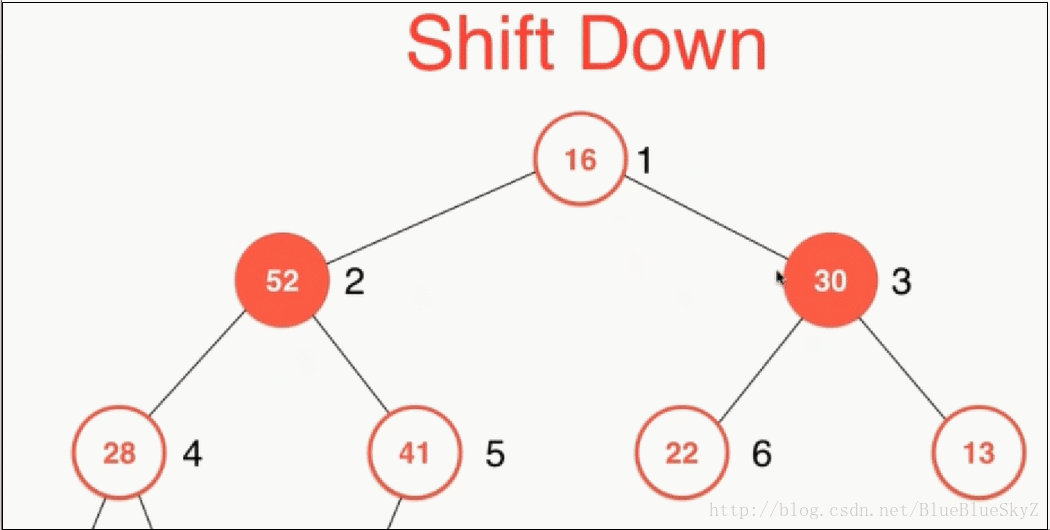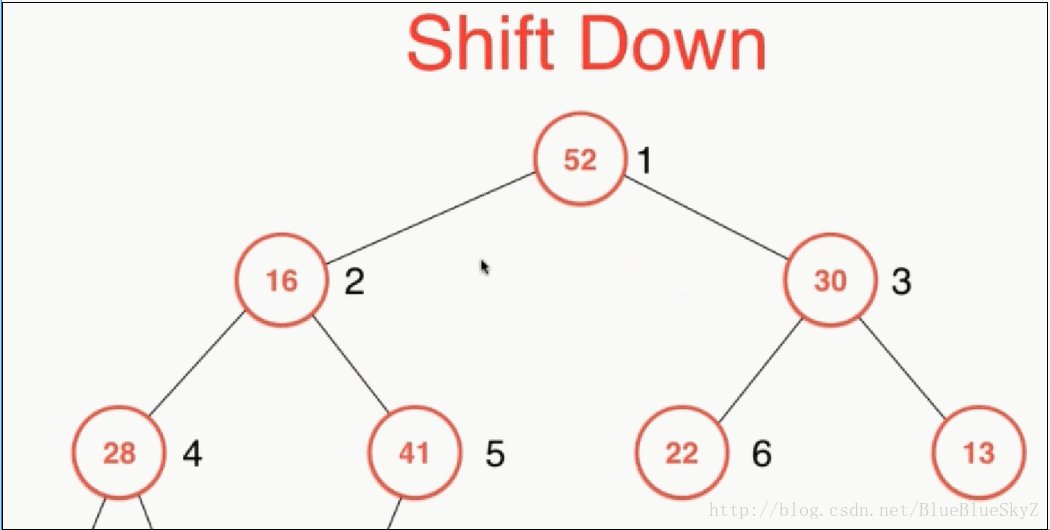
代码实现如下:
template<typename Item>
class MaxHeap{
private:
Item* data;//数组指针
int count;//现在有的数字
int capacity;//数组容量
//保持最大堆定义,维护索引k位置的元素
void shiftUp(int k){
//与父节点进行比较
while(k > 1 && data[k/2] < data[k]) {
swap(data[k/2], data[k]);
k /= 2;
}
}
void shiftDown(int k){
//存在左孩子则继续
while(2*k <= count) {
//data[k]与data[j]交换位置
int j = 2*k;
if(j + 1 <= count && data[j+1] > data[j] )
j += 1;
//如果位置正确直接跳出
if(data[k] >= data[j])
break;
swap(data[k], data[j]);
k = j;
}
}
public:
//构造函数
MaxHeap(int capacity){
//开辟空间
data = new Item[capacity + 1];
count = 0;
this->capacity = capacity;
}
~MaxHeap(){
delete [] data;
}
int size(){
return count;
}
bool isEmpty(){
return count == 0;
}
//插入一个数字
void insert(Item item){
//检查是否超出了容量,可以进行修改
assert(count + 1 <= capacity);
data[count+1] = item;
count++;
shiftUp(count);
}
//取出最大值(根节点)
Item extractMax(){
assert(count > 0);
Item ret = data[1];
//保持二叉堆性质
swap(data[1], data[count]);
count--;
shiftDown(1);
return ret;
}
};使用方法:
template<typename T>
void heapSort1(T arr[], int n) {
//放入最大堆中
MaxHeap<T> maxHeap = MaxHeap<T>(n);
for(int i = 0; i < n; i++) {
maxHeap.insert(arr[i]);
}
//从小到大排序
for(int i = n-1; i >=0; i--) {
arr[i] = maxHeap.extractMax();
}
}优化
优化1.0
我们上面的方式是采用一个一个数插入堆中形成一个最大堆,但是其实我们有一种更好的方法。利用一个性质:堆中最后一个非叶子节点是count的一半。当然这是对于索引从1开始的堆来说的。与此同时我们要注意数组是从0开始的,所以有一个1的偏移量。
这时,我们将非叶子节点一个个地进行shiftDown操作,这样就直接形成了一个堆,同时也比之前的插入少了很多步操作。演示如下:
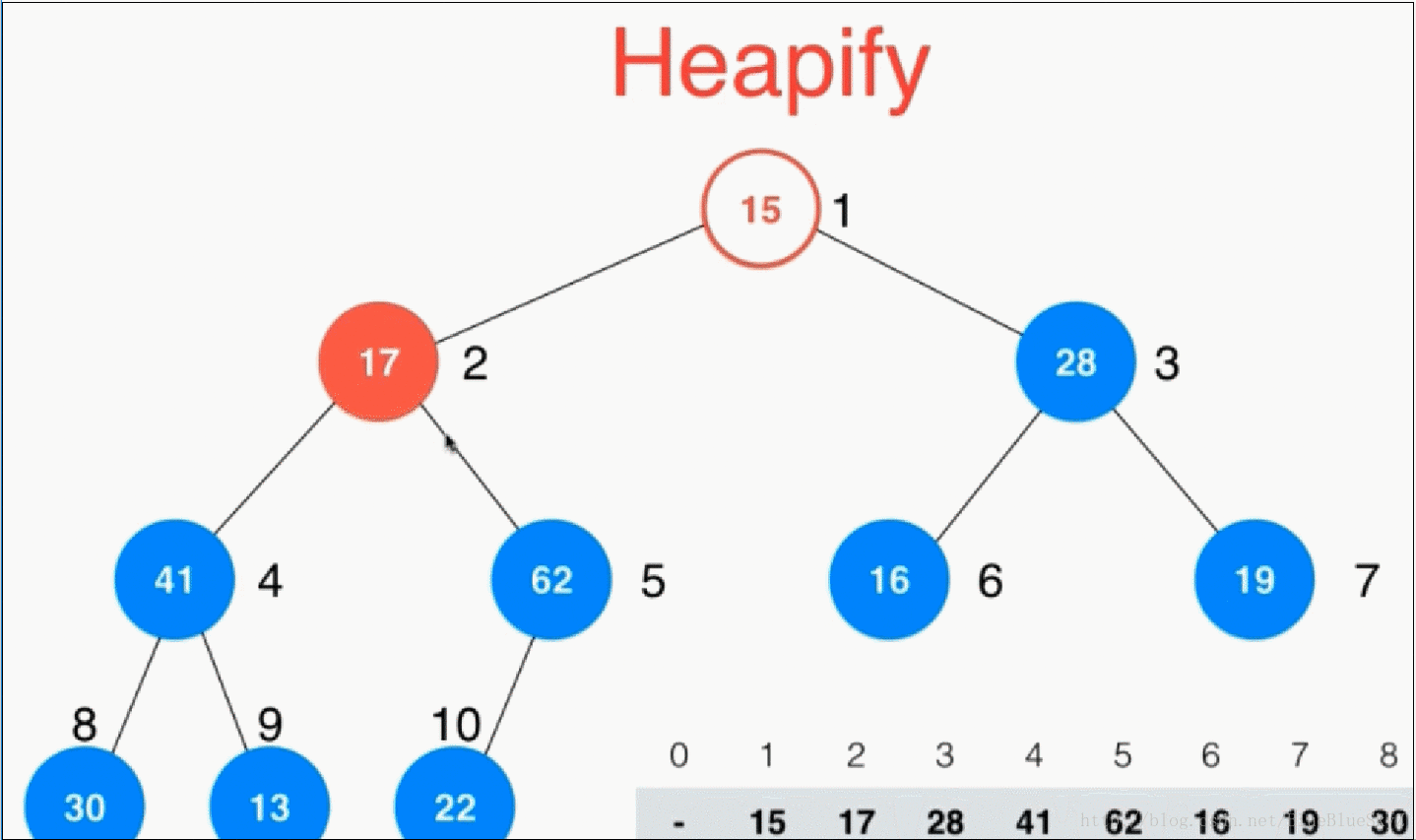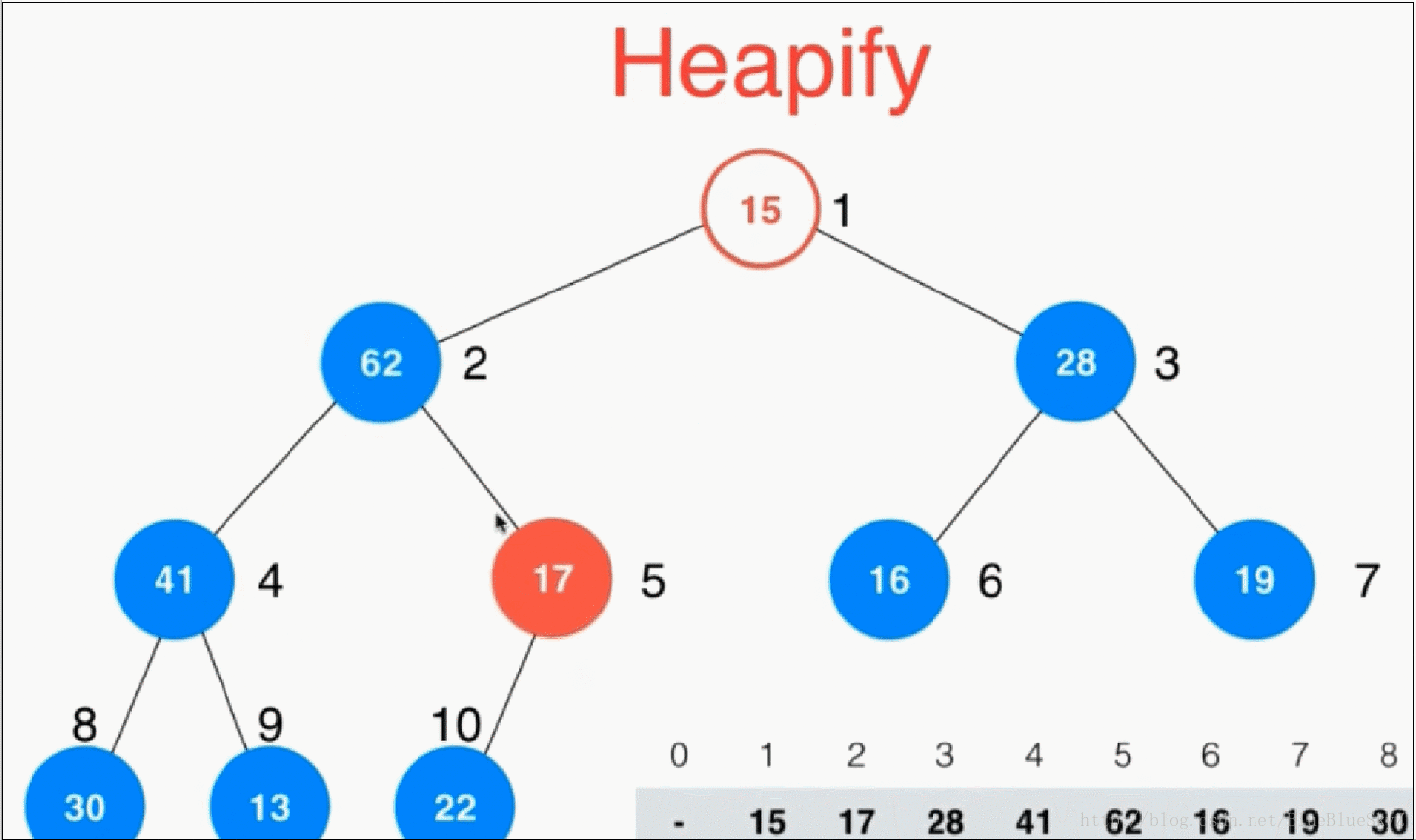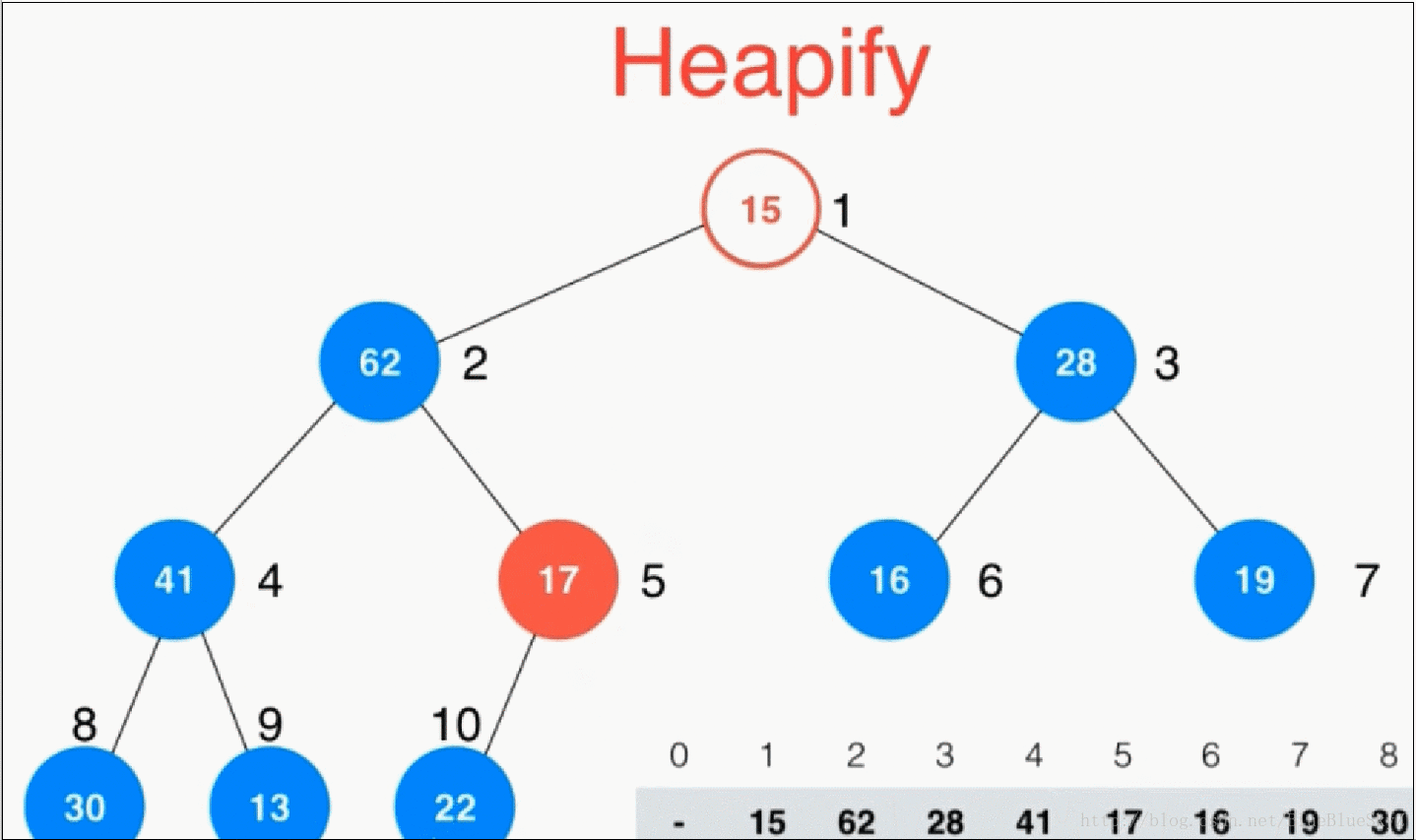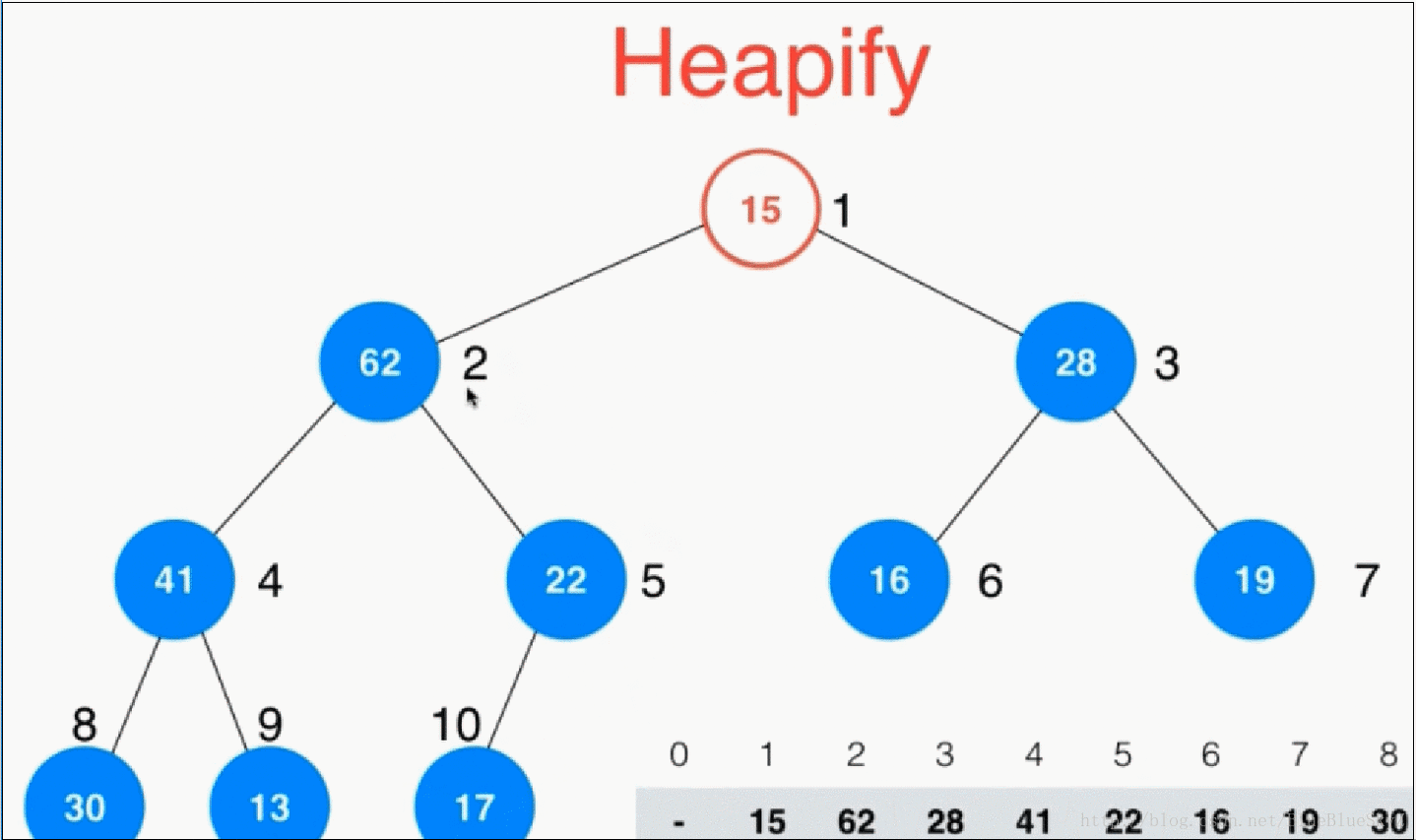
//第二种构造函数
MaxHeap(Item arr[], int n) {
data = new Item[n+1];
capacity = n;
for(int i = 0; i < n; i++) {
data[i+1] = arr[i];
}
count = n;
//对非叶子节点进行操作
for(int i = count/2; i >= 1; i--) {
shiftDown(i);
}
}使用方法:
template<typename T>
void heapSort2(T arr[], int n) {
//放入最大堆中
MaxHeap<T> maxHeap = MaxHeap<T>(arr, n);
//从小到大排序
for(int i = n-1; i >=0; i--) {
arr[i] = maxHeap.extractMax();
}
}优化2.0
我们可以发现,之前的方法都需要额外开辟一片空间进行排序,我们可以不可以就在原数组进行操作呢?答案当然是可以的,这里就引申出了原地堆排序。
需要注意的是这里我们索引就从0开始了,代码实现如下:
template<typename T>
void __shiftDown(T arr[], int n, int k) {
//存在左孩子则继续
while(2*k + 1 < n) {
//arr[k]arr[j]交换位置
int j = 2*k + 1;
if(j + 1 < n && arr[j+1] > arr[j] )
j += 1;
//如果位置正确直接跳出
if(arr[k] >= arr[j])
break;
swap(arr[k], arr[j]);
k = j;
}
}
/**
原地堆排序
*/
template<typename T>
void heapSort(T arr[], int n) {
// 注意,此时我们的堆是从0开始索引的
// 从(最后一个元素的索引-1)/2开始
// 最后一个元素的索引 = n-1
//heapify 构建一个堆
for(int i = (n-1 - 1)/2; i >= 0; i--) {
__shiftDown(arr, n, i);
}
for(int i = n-1; i > 0; i--) {
swap(arr[0], arr[i]);
__shiftDown(arr, i, 0);
}
}这里也可以使用我们之前插入排序使用的一种优化思想:我们不必每次都交换位置,可以找到位置之后再进行交换。修改代码:
// 优化的shiftDown过程, 使用赋值的方式取代不断的swap,
// 该优化思想和我们之前对插入排序进行优化的思路是一致的
template<typename T>
void __shiftDown2(T arr[], int n, int k){
T e = arr[k];
while( 2*k+1 < n ){
int j = 2*k+1;
if( j+1 < n && arr[j+1] > arr[j] )
j += 1;
if( e >= arr[j] ) break;
arr[k] = arr[j];
k = j;
}
arr[k] = e;
}索引堆
这里其实也是一种优化方式,但是由于是一个概念,我就单独写出来了。
我们之前交换的是数字,这在计算机里进行交换是很方便的,但是如果我们的堆需要交换的是一段很大的文本或者说是一个文件,这样就很不方便,于是就有了索引的诞生。我们建立索引堆时,不对里面的内容进行交换,而仅仅交换索引,通过建立索引堆来提交效率。
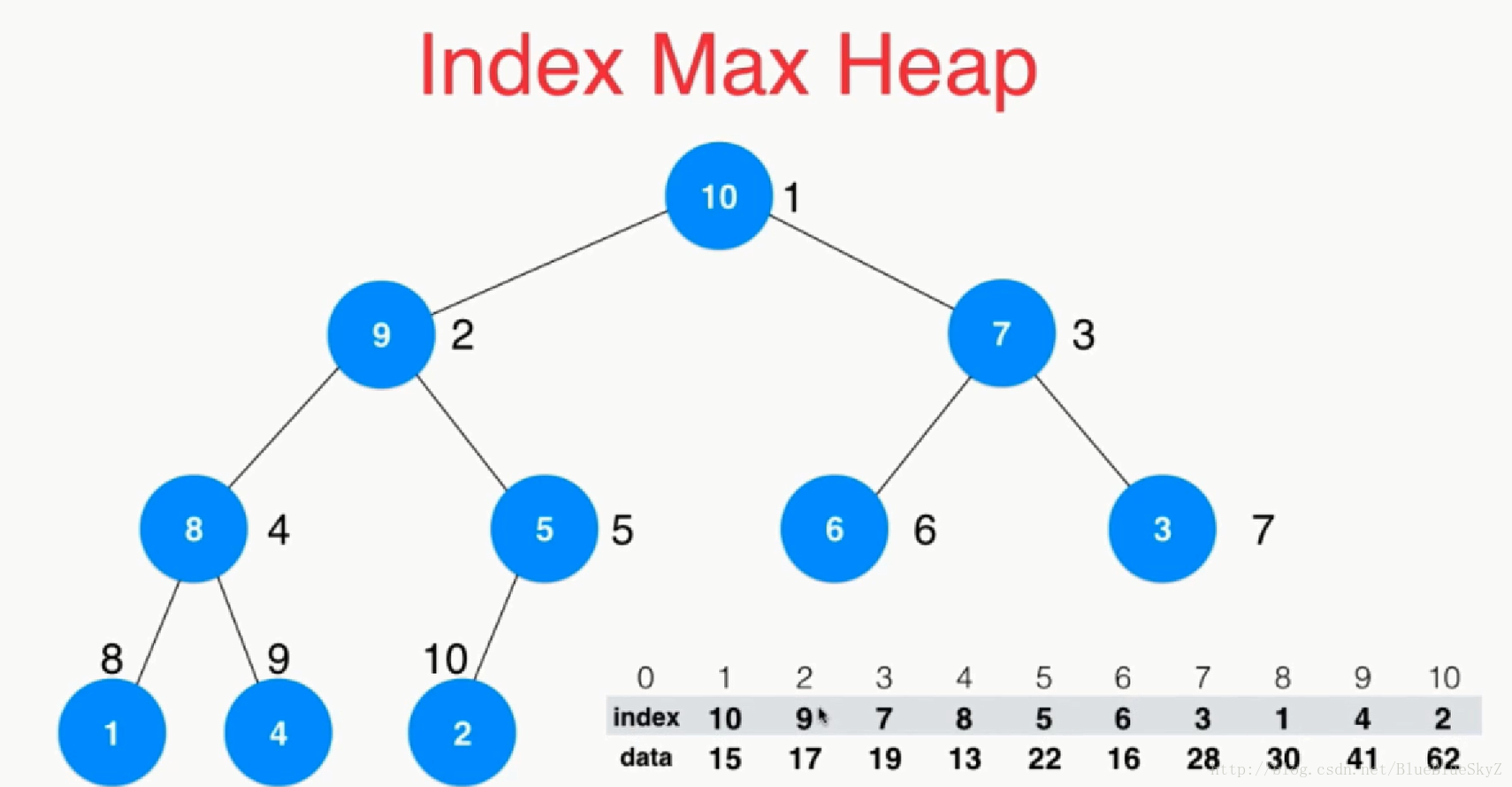
代码实现
这里实现的是最大索引堆,代码实现其实和之前的很类似,但是我们这里主要就是要另外使用indexes这是索引数组了。
template<typename Item>
class IndexMaxHeap{
private:
Item* data;//数组指针
int* indexes;//索引数组
int count;//现在有的数字
int capacity;//数组容量
//保持最大堆定义,维护索引k位置的元素
void shiftUp(int k){
//与父节点进行比较
while(k > 1 && data[indexes[k/2]] < data[indexes[k]]) {
swap(indexes[k/2], indexes[k]);
k /= 2;
}
}
void shiftDown(int k){
//存在左孩子则继续
while(2*k <= count) {
//data[k]与data[j]交换位置
int j = 2*k;
if(j + 1 <= count && data[indexes[j+1]] > data[indexes[j]] )
j += 1;
//如果位置正确直接跳出
if(data[indexes[k]] >= data[indexes[j]])
break;
swap(indexes[k], indexes[j]);
k = j;
}
}
public:
//构造函数
IndexMaxHeap(int capacity){
//开辟空间
data = new Item[capacity + 1];
indexes = new Item[capacity + 1];
count = 0;
this->capacity = capacity;
}
~IndexMaxHeap(){
delete[] data;
delete[] indexes;
}
int size(){
return count;
}
bool isEmpty(){
return count == 0;
}
//传入的i对用户而言,计算机从0开始
void insert(int i, Item item){
//检查是否超出了容量,可以进行修改
assert(count + 1 <= capacity);
assert( i +1 >= 1 && i + 1 <= capacity);
i += 1;
data[i] = item;
indexes[count+1] = i;
count++;
shiftUp(count);
}
//取出最大值(根节点)
Item extractMax(){
assert(count > 0);
Item ret = data[indexes[1]];
//保持二叉堆性质
swap(indexes[1], indexes[count]);
count--;
shiftDown(1);
return ret;
}
//取出最大值(根节点)的索引
int extractMaxIndex(){
assert(count > 0);
int ret = indexes[1] - 1;
//保持二叉堆性质
swap(indexes[1], indexes[count]);
count--;
shiftDown(1);
return ret;
}
Item getItem(int i) {
return data[i+1];
}
void change(int i, Item newItem) {
//与索引存放位置有关
i += 1;
data[i] = newItem;
//找到索引i在indexes中的位置
//尝试上移下移
for(int j = 1; j <= count; j++) {
if(indexes[j] == i) {
shiftUp(j);
shiftDown(j);
return;
}
}
}
};反向查找
我们上面的索引堆看似已经比较完善了,但还是存在一个问题。当我们需要change的时候我们需要遍历一遍索引,当我们有N个数要修改时,时间复杂度就是O(N^2)了,这显然不是一个好的方法。
这时我们又加入了一个反向索引,来表示i在indexes(堆)中的位置,我们可以得到如下图的性质:

这意味着我们同时也需要维护反向索引,因此我们继续修改代码,完成反向索引的建立后,我们查找的时间复杂度就下降为O(logN)了。
template<typename Item>
class IndexMaxHeap{
private:
Item* data;//数组指针
int* indexes;//索引数组
int* reverse;//反向索引
int count;//现在有的数字
int capacity;//数组容量
//保持最大堆定义,维护索引k位置的元素
void shiftUp(int k){
//与父节点进行比较
while(k > 1 && data[indexes[k/2]] < data[indexes[k]]) {
swap(indexes[k/2], indexes[k]);
reverse[indexes[k/2]] = k/2;
reverse[indexes[k]] = k;
k /= 2;
}
}
void shiftDown(int k){
//存在左孩子则继续
while(2*k <= count) {
//data[k]与data[j]交换位置
int j = 2*k;
if(j + 1 <= count && data[indexes[j+1]] > data[indexes[j]] )
j += 1;
//如果位置正确直接跳出
if(data[indexes[k]] >= data[indexes[j]])
break;
swap(indexes[k], indexes[j]);
reverse[indexes[k]] = k;
reverse[indexes[j]] = j;
k = j;
}
}
public:
//构造函数
IndexMaxHeap(int capacity){
//开辟空间
data = new Item[capacity + 1];
indexes = new Item[capacity + 1];
reverse = new Item[capacity + 1];
for(int i = 0; i <= capacity; i++)
reverse[i] = 0;
count = 0;
this->capacity = capacity;
}
~IndexMaxHeap(){
delete[] data;
delete[] indexes;
delete[] reverse;
}
int size(){
return count;
}
bool isEmpty(){
return count == 0;
}
//传入的i对用户而言,计算机从0开始
void insert(int i, Item item){
//检查是否超出了容量,可以进行修改
assert(count + 1 <= capacity);
assert( i +1 >= 1 && i + 1 <= capacity);
i += 1;
data[i] = item;
indexes[count+1] = i;
reverse[i] = count + 1;
count++;
shiftUp(count);
}
//取出最大值(根节点)
Item extractMax(){
assert(count > 0);
Item ret = data[indexes[1]];
//保持二叉堆性质
swap(indexes[1], indexes[count]);
reverse[indexes[1]] = 1;
reverse[indexes[count]] = 0;
count--;
shiftDown(1);
return ret;
}
//取出最大值(根节点)返回索引
int extractMaxIndex(){
assert(count > 0);
int ret = indexes[1] - 1;
//保持二叉堆性质
swap(indexes[1], indexes[count]);
reverse[indexes[1]] = 1;
reverse[indexes[count]] = 0;
count--;
shiftDown(1);
return ret;
}
/**
判断是否存在于数组中
*/
bool contain(int i) {
assert(i + 1 >= 1 && i + 1 <= capacity);
return reverse[i+1] != 0;
}
Item getItem(int i) {
//判断索引i是否在堆中
assert(contain(i));
return data[i+1];
}
void change(int i, Item newItem) {
//判断索引i是否在堆中
assert(contain(i));
//i与索引存放位置有关
i += 1;
data[i] = newItem;
//找到索引i在indexes中的位置
//尝试上移下移
// for(int j = 1; j <= count; j++) {
// if(indexes[j] == i) {
// shiftUp(j);
// shiftDown(j);
// return;
// }
// }
int j = reverse[i];
shiftUp(j);
shiftDown(j);
}
};当然这个还是有点绕的,说实话我现在都有点搞不清。。。不过这个思想却是之后能用上的,先记着吧。。
总结
之前学了几个排序,它们之间的对比如下:
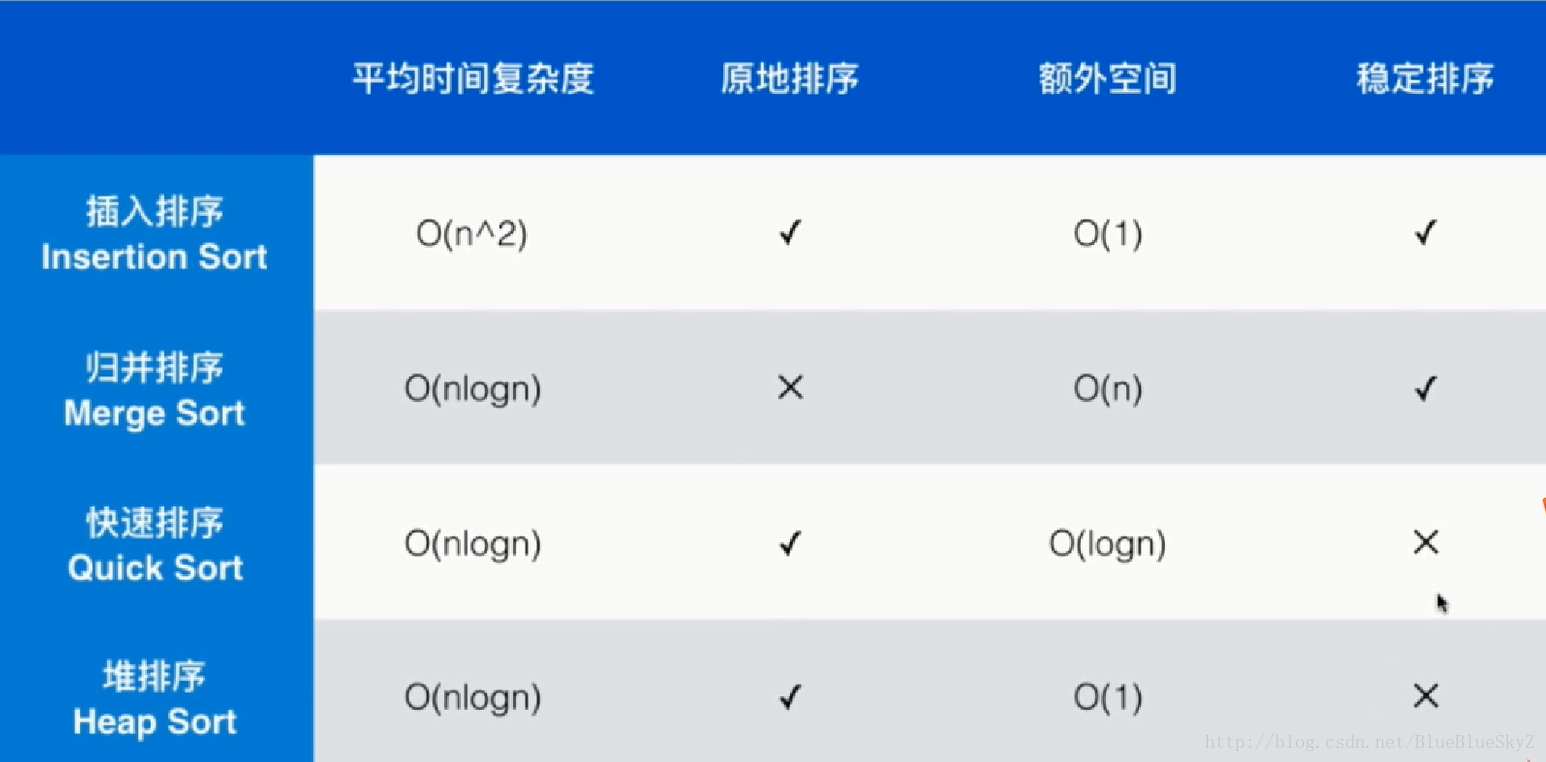
稳定排序是指如果有相同大小的数字,那么如果它们的相对位置不发生改变即为稳定。这和我们的代码实现有关,如果我们写的代码不好的话,可能前面两个也无法稳定。
我们也可以看到并没有一个算法是完美的,可能存在,但它尚未被发现,所以我们在实现算法的时候也要根据实际情况进行选择。
最后附上我github地址,之前写的代码也一并放了上去:
github