对OCR字符识别进行初步研究,发现Google有OCR的识别库,于是尝试测试一下。
OCR,即Optical Character Recognition,光学字符识别,是指通过扫描字符,然后通过其形状将其翻译成电子文本的过程,对应图形验证码来说,它们都是一些不规则的字符,这些字符是由字符稍加扭曲变换得到的内容,我们可以使用OCR技术来讲其转化为电子文本,然后将结果提取交给服务器,便可以达到自动识别验证码的过程。
pytesseract是Python的一个OCR识别库,但其实是对tesseract做的一层Python API封装,pytesseract是Google的Tesseract-OCR引擎包装器;所以它们的核心是tesseract,因此在安装tesserocr之前,我们需要先安装tesseract。
#安装tesseract
sudo apt-get install -y tesseract-ocr libtesseract-dev libleptonica-dev
#安装pytesseract
pip install pytesseract
测试图片(字符较大或较小时均能测试成功,但有其他干扰时可能检测不到):
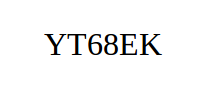
识别代码:
import pytesseract
import cv2
img = cv2.imread('test.jpg')
print(pytesseract.image_to_string(img))
识别结果为:
YT68EK
此外,不用opencv读图片,用PIL库也可以:
import pytesseract
from PIL import Image
image = Image.open('test.jpg')
print(pytesseract.image_to_string(image))
参考连接:
