1.windows下的Tesseract-OCR安装
Tesseract-OCR下载: http://pan.baidu.com/s/1miRU6EG
识别语言库:
官网地址: https://github.com/tesseract-ocr/langdata
或者网盘:
http://pan.baidu.com/s/1kV18iov
安装完后ocr后,将语言库文件到到安装目录~\Tesseract-OCR\tessdata\里(替换)
2.linux下的Tesseract-OCR安装
Tesseract-OCR安装:
下载地址: https://github.com/tesseract-ocr/tesseract
或者百度网盘: http://pan.baidu.com/s/1i5v69VJ
leptonica安装:
官网: http://www.leptonica.com/ 上下载
或者网盘下载,下载地址:
http://pan.baidu.com/s/1mhTGk4K
同样,安装完后ocr后,将语言库文件到到安装目录~\Tesseract-OCR\tessdata\里。
3.命令执行
tesseract的用法:
参数1:需要识别的文件
参数2:输出的文件名称,输出的是文本文件,里面保存了识别的信息
识别英文这两个参数就可以了,下面做个实验:

我们在命令行输入:tesseract 5.jpg 6 ,可以看到程序生成了一个6.txt ,里面保存着识别后的文本,怎么样简单又给力~
上面说道tesseract 是支持中文的,所以么,接下来看看如何使用tesseract 实现我们中文的识别,下面继续介绍其他参数
参数3:-l
参数4: 使用的语言库
参数3 -l 应该是知道参数4所使用的语言库,默认英文,也就是为什么上面识别英文的例子,并没有输入参数3和参数4,也实现了识别。
下面继续我们的实验:
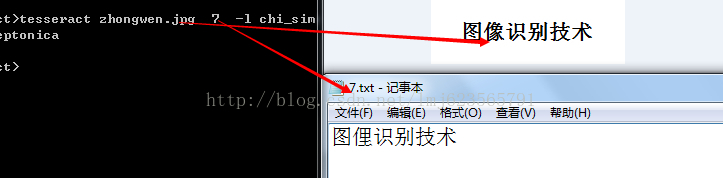
我们准备了一张图片,然后使用tesseract zhongwen.jpg 7 -l chi_sim 指明了中文语言,然后效果图上,还是很不错的,毕竟我们的中文是如此的博大精深,并且tesseract可以经过训练,然后识字的能力就会大幅度提升。
有时候会遇到如下错:
Please make sure the TESSDATA_PREFIX environment variable is set to the parent directory of your “tessdata” directory.
需要将安装目录配置到系统路径中,如添加
TESSDATA_PREFIX=D:\Program Files\Tesseract-OCR\
linux 的方法类似。
4.利用java执行
try {
Process pro = Runtime.getRuntime()
.exec(new String[]{"D:/Program Files (x86)/Tesseract-OCR/tesseract.exe",
"E:/resImage.jpg",
"E:/result"});
pro.waitFor();
} catch (IOException e) {
e.printStackTrace();
}
运行以上代码后,会在E盘目录中看到result.txt的内容就为resImage.jpg的数字内容。
转载地址:https://blog.csdn.net/zmx729618/article/details/78123851