需配置好OpenCV和OCR环境下运行
1、OpenCV简介
OpenCV的全称是Open Source Computer Vision Library,是一个跨平台的计算机视觉库。
OpenCV用C++语言编写,它的主要接口也是C++语言,但是依然保留了大量的C语言接口。该库也有大量的Python, Java and MATLAB/OCTAVE (版本2.5)的接口。这些语言的API接口函数可以通过在线文档获得。现在也提供对于C#, Ruby的支持。
它有以下特点:
1) 开放的C/C++源码
2) 基于Intel处理器指令集开发的优化代码
3) 统一的结构和功能定义
4) 强大的图像和矩阵运算能力
5) 方便灵活的用户接口
6)同时支持MS-WINDOWS、LINUX平台
作为一个基本的计算机视觉、图像处理和模式识别的开源项目,OPENCV可以直接应用于很多领域,作为第二次开发的理想工具。
2、OCR简介
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;即,对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。如何除错或利用辅助信息提高识别正确率,是OCR最重要的课题,ICR(Intelligent Character Recognition)的名词也因此而产生。衡量一个OCR系统性能好坏的主要指标有:拒识率、误识率、识别速度、用户界面的友好性,产品的稳定性,易用性及可行性等。
3、OpenCV.jar包对图像实现灰度化原理
我们知道,在一个24位彩色图像中,每个像素由三个字节表示,通常表示为RGB。通常,许多24位彩色图像存储为32位图像,每个像素多余的字节存储为一个alpha值,表现有特殊影响的信息。在RGB模型中,如果R=G=B时,则彩色表示一种灰度颜色,其中R=G=B的值叫灰度值,因此,灰度图像每个像素只需一个字节存放灰度值(又称强度值、亮度值),灰度范围为0-255。这样就得到一幅图片的灰度图。
几种灰度化的方法
①、分量法
将彩色图像中的三分量的亮度作为三个灰度图像的灰度值,可根据应用需要选取一种灰度图像。
F1(i,j) = R(i,j)
F2(i,j) = G(i,j)
F3(i,j) = B(i,j)
代码示例:
import cv2.cv as cv
image = cv.LoadImage('mao.jpg')
b = cv.CreateImage(cv.GetSize(image), image.depth, 1)
g = cv.CloneImage(b)
r = cv.CloneImage(b)
cv.Split(image, b, g, r, None)
cv.ShowImage('a_window', r)
cv.WaitKey(0)
②、 最大值法
将彩色图像中的三分量亮度的最大值作为灰度图的灰度值。
F(i,j) = max(R(i,j), G(i,j), B(i,j))
代码示例:
image = cv.LoadImage('mao.jpg')
new = cv.CreateImage(cv.GetSize(image), image.depth, 1)for i in range(image.height):
for j in range(image.width):
new[i,j] = max(image[i,j][0], image[i,j][1], image[i,j][2])
cv.ShowImage('a_window', new)
cv.WaitKey(0)
③、平均值法
将彩色图像中的三分量亮度求平均得到一个灰度值。
F(i,j) = (R(i,j) + G(i,j) + B(i,j)) / 3
代码示例:
image = cv.LoadImage('mao.jpg')
new = cv.CreateImage(cv.GetSize(image), image.depth, 1)for i in range(image.height):
for j in range(image.width):
new[i,j] = (image[i,j][0] + image[i,j][1] + image[i,j][2])/3
cv.ShowImage('a_window', new)
cv.WaitKey(0)
④、加权平均法
根据重要性及其它指标,将三个分量以不同的权值进行加权平均。由于人眼对绿色的敏感最高,对蓝色敏感最低,因此,按下式对RGB三分量进行加权平均能得到较合理的灰度图像。
F(i,j) = 0.30R(i,j) + 0.59G(i,j) + 0.11B(i,j))
代码示例:
image = cv.LoadImage('mao.jpg')
new = cv.CreateImage(cv.GetSize(image), image.depth, 1)for i in range(image.height):
for j in range(image.width):
new[i,j] = 0.3 * image[i,j][0] + 0.59 * image[i,j][1] + 0.11 * image[i,j][2]
cv.ShowImage('a_window', new)
cv.WaitKey(0)
上面的公式可以看出绿色(G 分量)所占的比重比较大,所以有时候也会直接取G 分量进行灰度化。
代码示例:
image = cv.LoadImage('mao.jpg')
new = cv.CreateImage(cv.GetSize(image), image.depth, 1)for i in range(image.height):
for j in range(image.width):
new[i,j] = image[i,j][1]
cv.ShowImage('a_window', new)
cv.WaitKey(0)
而OpenCV的Java实现中采用的是加权法来实现图片的灰度化。
4、OpenCV.jar包对图像进行二值化处理原理
图像的二值化处理就是将图像上的点的灰度置为0或255,也就是将整个图像呈现出明显的黑白效果。即将256个亮度等级的灰度图像通过适当的阈值选取而获得仍然可以反映图像整体和局部特征的二值化图像。在数字图像处理中,二值图像占有非常重要的地位,特别是在实用的图像处理中,以二值图像处理实现而构成的系统是很多的,要进行二值图像的处理与分析,首先要把灰度图像二值化,得到二值化图像,这样子有利于在对图像做进一步处理时,图像的集合性质只与像素值为0或255的点的位置有关,不再涉及像素的多级值,使处理变得简单,而且数据的处理和压缩量小。为了得到理想的二值图像,一般采用封闭、连通的边界定义不交叠的区域。所有灰度大于或等于阈值的像素被判定为属于特定物体,其灰度值为255表示,否则这些像素点被排除在物体区域以外,灰度值为0,表示背景或者例外的物体区域。如果某特定物体在内部有均匀一致的灰度值,并且其处在一个具有其他等级灰度值的均匀背景下,使用阈值法就可以得到比较的分割效果。如果物体同背景的差别表现不在灰度值上(比如纹理不同),可以将这个差别特征转换为灰度的差别,然后利用阈值选取技术来分割该图像。动态调节阈值实现图像的二值化可动态观察其分割图像的具体结果。
5、OpenCV.jar包对图像进行腐蚀处理原理
对二值图腐蚀过程:
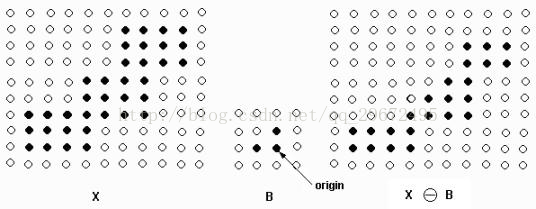
在下图中,左边是被处理的图象X(二值图象,我们针对的是黑点),中间是结构元素B,那个标有origin的点是中心点,即当前处理元素的位置。腐蚀的方法是,拿B的中心点和X上的点一个一个地对比,如果B上的所有点(指的是所有黑点)都在X的范围内(即X图上处理元素所在的位置以及它上,左两个点都是黑色),则该点保留,否则将该点去掉(变为白点);右边是腐蚀后的结果。可以看出,它仍在原来X的范围内,且比X包含的点要少,就像X被腐蚀掉了一层。
对灰度图像的腐蚀:
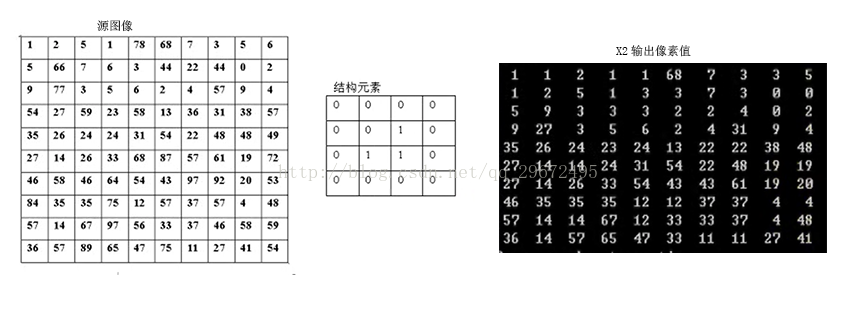
如下图,左边是要处理图像,中间是结构元素,右边是与对应每个像素的灰度值。
处理过程就是:与上面的B一样,中间是要处理的元素所在的位置,三个1所在的位置对应三个灰度值,然后将中间这个1对应的灰度值改成这三个最小的,如源图像第一个灰度值1,它上左都没有灰度值,所以最小就是它本身,所以输出也是1,再比如处理灰度值为22那个点的时候,上面是7左边是44,所以22应改为7。
6、OCR识别提取图片中文字原理
· 预处理:对包含文字的图像进行处理以便后续进行特征提取、学习。这个过程的主要目的是减少图像中的无用信息,以便方便后面的处理。在这个步骤通常有:灰度化(如果是彩色图像)、降噪、二值化、字符切分以及归一化这些子步骤。经过二值化后,图像只剩下两种颜色,即黑和白,其中一个是图像背景,另一个颜色就是要识别的文字了。降噪在这个阶段非常重要,降噪算法的好坏对特征提取的影响很大。字符切分则是将图像中的文字分割成单个文字——识别的时候是一个字一个字识别的。如果文字行有倾斜的话往往还要进行倾斜校正。归一化则是将单个的文字图像规整到同样的尺寸,在同一个规格下,才能应用统一的算法。
· 特征提取和降维:特征是用来识别文字的关键信息,每个不同的文字都能通过特征来和其他文字进行区分。对于数字和英文字母来说,这个特征提取是比较容易的,因为数字只有10个,英文字母只有52个,都是小字符集。对于汉字来说,特征提取比较困难,因为首先汉字是大字符集,国标中光是最常用的第一级汉字就有3755个;第二个汉字结构复杂,形近字多。在确定了使用何种特征后,视情况而定,还有可能要进行特征降维,这种情况就是如果特征的维数太高(特征一般用一个向量表示,维数即该向量的分量数),分类器的效率会受到很大的影响,为了提高识别速率,往往就要进行降维,这个过程也很重要,既要降低维数吧,又得使得减少维数后的特征向量还保留了足够的信息量(以区分不同的文字)。
· 分类器设计、训练和实际识别:分类器是用来进行识别的,就是对于第二步,对一个文字图像,提取出特征给,丢给分类器,分类器就对其进行分类,告诉你这个特征该识别成哪个文字。
· 后处理:后处理是用来对分类结果进行优化的,第一个,分类器的分类有时候不一定是完全正确的(实际上也做不到完全正确),比如对汉字的识别,由于汉字中形近字的存在,很容易将一个字识别成其形近字。后处理中可以去解决这个问题,比如通过语言模型来进行校正——如果分类器将“在哪里”识别成“存哪里”,通过语言模型会发现“存哪里”是错误的,然后进行校正。第二个,OCR的识别图像往往是有大量文字的,而且这些文字存在排版、字体大小等复杂情况,后处理中可以尝试去对识别结果进行格式化,比如按照图像中的排版排列什么的,举个栗子,一张图像,其左半部分的文字和右半部分的文字毫无关系,而在字符切分过程中,往往是按行切分的,那么识别结果中左半部分的第一行后面会跟着右半部分的第一行诸如此类。
代码:
TestOcr类:
package com.njupt.yangmaohu;
import java.io.File;
import java.io.IOException;
public class TestOcr {
public static void main(String[] args) {
// TODO 自动生成的方法存根
//输入图片地址
String path = "G:/ka.jpg";
PictureManage pictureManage = new PictureManage(path); //对图片进行处理
pictureManage.imshow();
try {
String valCode = new OCR().recognizeText(new File("xintu.jpg"), "jpg");//jpg是图片格式
System.out.println("图片中文字为:"+"\n"+valCode);
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
}
PictureManage类:
package com.njupt.yangmaohu;
import java.awt.Graphics;
import java.awt.Image;
import java.awt.image.BufferedImage;
import java.awt.image.DataBufferByte;
import java.io.File;
import java.io.IOException;
import javax.imageio.ImageIO;
import org.opencv.core.Core;
import org.opencv.core.CvType;
import org.opencv.core.Mat;
import org.opencv.core.Size;
import org.opencv.highgui.Highgui;
import org.opencv.imgproc.Imgproc;
public class PictureManage {
private Mat image;
//private JLabel jLabelImage;
public PictureManage(String fileName) {
System.loadLibrary(Core.NATIVE_LIBRARY_NAME);
this.image= Highgui.imread(fileName);
}
/**
* 图片画质处理
* @param image
* @return
*/
public static Mat setMatImage(Mat image) {
Mat loadeMatImage = new Mat();
//灰度处理
Imgproc.cvtColor(image,image,Imgproc.COLOR_RGB2GRAY);
//二值化处理
Mat binaryMat = new Mat(image.height(), image.width(), CvType.CV_8UC1);
Imgproc.threshold(image, binaryMat,20, 300, Imgproc.THRESH_BINARY);
//图像腐蚀
Mat element = Imgproc.getStructuringElement(Imgproc.MORPH_RECT,
new Size(500,500));
Imgproc.erode(binaryMat, image,element);
//loadeMatImage = image;
loadeMatImage = binaryMat;
return loadeMatImage;
}
/**
* Mat转image
* @param matrix
* @return
*/
private Image toBufferedImage(Mat matrix) {
int type = BufferedImage.TYPE_BYTE_GRAY;
if (matrix.channels()>1) {
type = BufferedImage.TYPE_3BYTE_BGR;
}
int bufferSize = matrix.channels()*matrix.cols()*matrix.rows();
byte[] buffer = new byte[bufferSize];
matrix.get(0, 0, buffer);
BufferedImage image = new BufferedImage(matrix.cols(), matrix.rows(),type);
final byte[] targetPxiels = ((DataBufferByte)image.getRaster().getDataBuffer()).getData();
System.arraycopy(buffer, 0, targetPxiels, 0, buffer.length);
return image;
}
/***
* 将Image变量保存成图片
* @param im
* @param fileName
*/
public void saveImage(Image im ,String fileName) {
int w = im.getWidth(null);
int h = im.getHeight(null);
BufferedImage bi = new BufferedImage(w, h, BufferedImage.TYPE_3BYTE_BGR);
Graphics g = bi.getGraphics();
g.drawImage(im, 0, 0, null);
try {
ImageIO.write(bi, "jpg", new File(fileName));
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 图片处理
* @param args
*/
public void imshow(){
//添加原图
Image originalImage = toBufferedImage(image);
saveImage(originalImage, "yuantu.jpg");
//jLabelImage.setIcon(new ImageIcon(originalImage));
//添加处理图
Mat mat1 = setMatImage(image);
Image newImage = toBufferedImage(mat1);
saveImage(newImage, "xintu.jpg");
}
}
ImageIOHelper类:
package com.njupt.yangmaohu;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.util.Iterator;
import java.util.Locale;
import javax.imageio.IIOImage;
import javax.imageio.ImageIO;
import javax.imageio.ImageReader;
import javax.imageio.ImageWriteParam;
import javax.imageio.ImageWriter;
import javax.imageio.metadata.IIOMetadata;
import javax.imageio.stream.ImageInputStream;
import javax.imageio.stream.ImageOutputStream;
import com.sun.media.imageio.plugins.tiff.TIFFImageWriteParam;
public class ImageIOHelper {
/**
* 图片文件转换为tif格式
* @param imageFile 文件路径
* @param imageFormat 文件扩展名
* @return
*/
public static File createImage(File imageFile, String imageFormat) {
File tempFile = null;
try {
Iterator<ImageReader> readers = ImageIO.getImageReadersByFormatName(imageFormat);
ImageReader reader = readers.next();
ImageInputStream iis = ImageIO.createImageInputStream(imageFile);
reader.setInput(iis);
//Read the stream metadata
IIOMetadata streamMetadata = reader.getStreamMetadata();
//Set up the writeParam
TIFFImageWriteParam tiffWriteParam = new TIFFImageWriteParam(Locale.CHINESE);
tiffWriteParam.setCompressionMode(ImageWriteParam.MODE_DISABLED);
//Get tif writer and set output to file
Iterator<ImageWriter> writers = ImageIO.getImageWritersByFormatName("tiff");
ImageWriter writer = writers.next();
BufferedImage bi = reader.read(0);
IIOImage image = new IIOImage(bi,null,reader.getImageMetadata(0));
tempFile = tempImageFile(imageFile);
ImageOutputStream ios = ImageIO.createImageOutputStream(tempFile);
writer.setOutput(ios);
writer.write(streamMetadata, image, tiffWriteParam);
ios.close();
writer.dispose();
reader.dispose();
} catch (IOException e) {
e.printStackTrace();
}
return tempFile;
}
private static File tempImageFile(File imageFile) {
String path = imageFile.getPath();
StringBuffer strB = new StringBuffer(path);
strB.insert(path.lastIndexOf('.'),0);
return new File(strB.toString().replaceFirst("(?<=//.)(//w+)$", "tif"));
}
}
OCR类:
package com.njupt.yangmaohu;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
import org.jdesktop.swingx.util.OS;
public class OCR {
private final String LANG_OPTION = "-l"; //英文字母小写l,并非数字1
private final String EOL = System.getProperty("line.separator");
private String tessPath = "C://Program Files (x86)//Tesseract-OCR";//tesseract-ocr安装地址
//private String tessPath = new File("tesseract").getAbsolutePath();
public String recognizeText(File imageFile,String imageFormat)throws Exception{
File tempImage = ImageIOHelper.createImage(imageFile,imageFormat);
File outputFile = new File(imageFile.getParentFile(),"output");
StringBuffer strB = new StringBuffer();
List<String> cmd = new ArrayList<String>();
if(OS.isWindowsXP()){
cmd.add(tessPath+"//tesseract");
}else if(OS.isLinux()){
cmd.add("tesseract");
}else{
cmd.add(tessPath+"//tesseract");
}
cmd.add("");
cmd.add(outputFile.getName());
//cmd.add(LANG_OPTION);
//cmd.add("chi_sim");
//cmd.add("eng");
ProcessBuilder pb = new ProcessBuilder();
pb.directory(imageFile.getParentFile());
cmd.set(1, tempImage.getName());
pb.command(cmd);
pb.redirectErrorStream(true);
Process process = pb.start();
//tesseract.exe 1.jpg 1 -l chi_sim
int w = process.waitFor();
//删除临时正在工作文件
tempImage.delete();
if(w==0){
BufferedReader in = new BufferedReader(new InputStreamReader(new FileInputStream(outputFile.getAbsolutePath()+".txt"),"UTF-8"));
String str;
while((str = in.readLine())!=null){
strB.append(str).append(EOL);
}
in.close();
}else{
String msg;
switch(w){
case 1:
msg = "Errors accessing files.There may be spaces in your image's filename.";
break;
case 29:
msg = "Cannot recongnize the image or its selected region.";
break;
case 31:
msg = "Unsupported image format.";
break;
default:
msg = "Errors occurred.";
}
tempImage.delete();
//throw new RuntimeException(msg);
}
new File(outputFile.getAbsolutePath()+".txt").delete();
return strB.toString();
}
}
[java] view plain copy