在了解其内容前,首先要明白名词的含义
- 前端(Front End):编译器对程序代码的分析和理解过程。
- 后端(Back End):生成目标代码的过程,与目标机器有关。
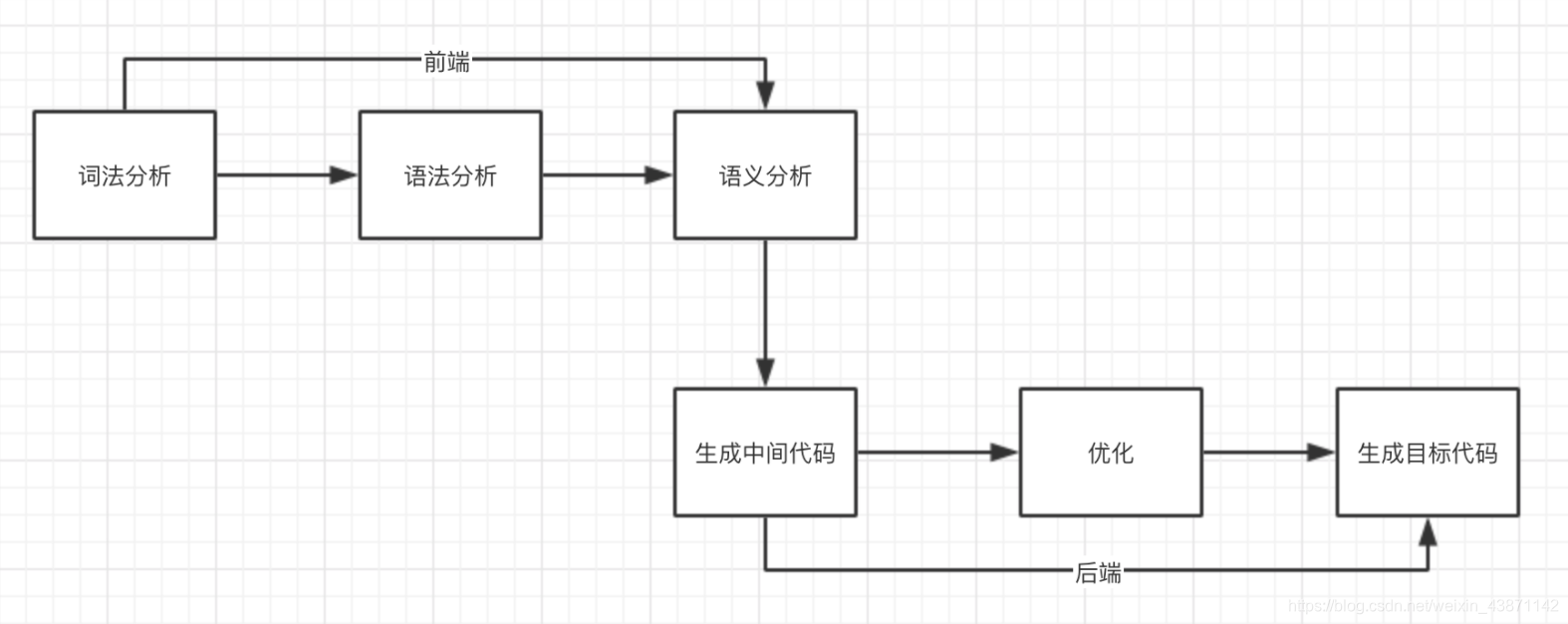
词法分析(Lexical Analysis)
程序是由一个个“词法记号(Token)”组成,所以编译器的第一步理所当然的是由词法分析器解析出一个个的Token。
词法分析器可以手写也可以通过一些生成工具(如Lex或Flex)来形成。是基于一些规则(用“正则文法”表达)来工作。符合正则文法的表达式称为正则表达式。
有限自动机:有限个状态的自动机器。(例:抽水马桶的“注水”和“水满”)
词法分析器也是一样,他分析整个程序的字符串,当遇到不同的字符时,会驱使它迁移到不同的状态。

语法分析(Syntactic Analysis, or Parsing)
语法分析是识别一个个的单词,而语法分析是在词法分析的基础上识别出程序的语法结构。
这个结构是一个树状结构(抽象语法树AST),树的每个节点是一个语法单元,这个单元的构成规则就叫“语法”,是计算机容易理解和执行的。
形成AST的好处是计算机很容易去处理。
如何构造AST,一种非常直观的构造方法是自上而下进行分析,这种算法称为递归下降算法,同时与之对应也有自底向上的算法。
语义分析(Semantic Analysis)
语义分析就是要让计算机理解我们的真实意图,把一些模凌两可的地方消除掉。
计算机语言的语义一般可以表达为一些规则,你只要检查是否符合这些规则就行了。
语义分析就是根据语义规则进行分析判断。语义分析工作的某些成果,会作为属性标注在抽象语法树上。(比如所处的源代码行号)
总结
- 词法分析是把程序分割成一个个Token的过程,可以通过构造有限自动机来实现。
- 语法分析是把程序的结构识别出来,并形成一棵便于由计算机处理的抽象语法树,可以用递归下降的算法来实现。
- 语义分析是消除语义模糊,生成一些属性信息,让计算机能够依据这些信息生成目标代码。
