
独家揭秘:Kotlin编译器前端:解析阶段
Kotlin编译器对我来说就像一个黑盒子,虽然有关于Kotlin PSI在IDE插件中有使用的文档,但除了源代码中留下的注释之外,几乎没有其他信息可用。接下来的文章中我们来探索Kotlin编译器前端:解析阶段。
Kotlin编译器的独特之处在于其前端是建立在其之上,这使得前端易于与编译器插件和IDE插件共享。对于Kotlin,前端的目标是解析编写的代码并分析其解释结构,以便生成中间表示(IR)。然后,将此IR和额外生成的信息一起发送到编译器的后端,后端会进一步分析、增强和优化IR,最终将其转化为机器码。
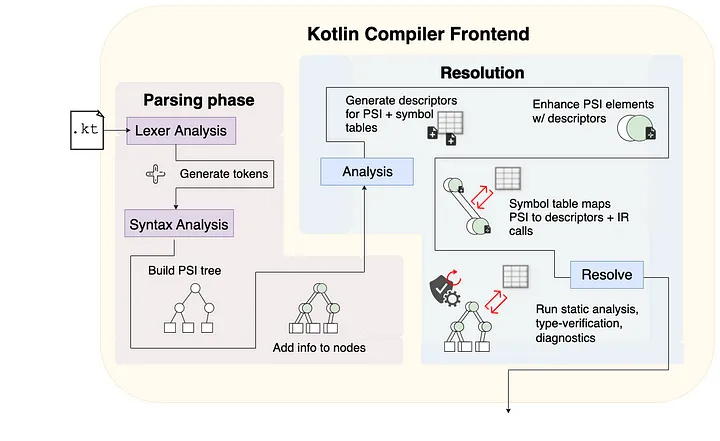
这个系列观察了当您通过Kotlin编译器提供代码时发生的情况:这是了解编译器在每个阶段所做的最简单的方式。本文介绍了前端部分的第一阶段,即解析阶段。
解析阶段
源代码编译时,编译器首先必须弄清开发人员实际编写了什么。假设我们通过编译器发送以下文件:
fun main() {
1 + 2
1.plus(2)
}
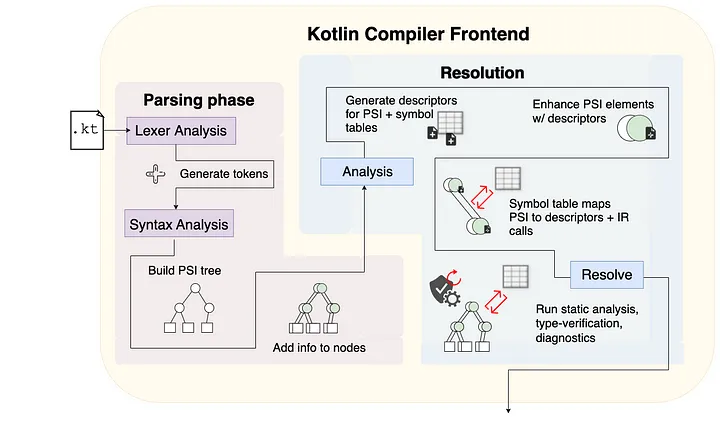
编译器可以通过解析并将人类可读代码翻译成编译器自己可以理解的格式来“理解”开发人员编写的内容。在下面的图片中,Kotlin文件首先被提供给解析阶段。创建了一个词法分析器来解析源文件并生成标记。然后将这些标记通过语法分析进行处理,从而创建了一个PSI结构(在语法分析阶段下面更详细地解释和说明)。
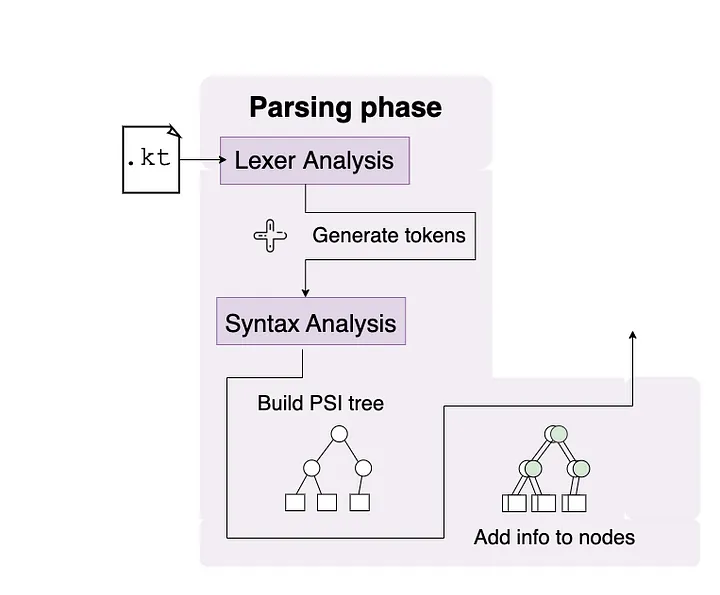
此时,编译器并不关心代码是否有效,只关心弄清楚文件中写了什么。解析阶段负责创建语法树,以便编译器在解析阶段后能够分析和验证代码。
解析的基础可以看作是以下两个阶段的过程:
- 词法分析:将文本文件解析为令牌。
- 语法分析:解析并组织令牌成为语法树。
词法分析
在词法分析期间,Kotlin解析器首先创建一个KotlinLexer。该Lexer扫描Kotlin文件并将文本拆分成一组称为KtTokens的标记。例如,KtTokens表示符号如下:
KtSingleValueToken LPAR = new KtSingleValueToken("LPAR", "(");
KtSingleValueToken RPAR = new KtSingleValueToken("RPAR", ")");
KotlinExpressionParsing将建立一个访问器来将这些记号安排成表达式节点的集合。这些表达式节点随后通过ASTNode附加以构建PSI树。
Programming Structure Interface(PSI)是JetBrains构建的一种抽象。它有点像重量级的通用语法树,可以在他们的IDE中处理文本/代码/语言。这些树是在语法分析期间生成的内存中表示,并且需要编译器生成附加的数据,并以后的阶段递归分析自身以进行代码验证。PSI对于编译器插件和IDEA插件很有用,因为您可以过滤PSI以拦截特定的代码片段。
简而言之,Kotlin解析器创建连接层次关系中的节点的结构。例如,如果KotlinExpressionParsing捕获到throw关键字,则会解析另一个元素,并将其转换为PSI元素添加到树中:
/*
* : "throw" element
*/
private void parseThrow() {
assert _at(THROW_KEYWORD)
PsiBuilder.Marker marker = mark();
advance(); // THROW_KEYWORD
parseExpression();
marker.done(THROW);
}
在接下来的部分中,语法分析将创建一个包装记号作为PsiElements的PSI解析器。每个节点都包含一个描述,递归地描述了源代码的语法结构。
语法分析
生成的PSI文件描述了一组PsiElements(称为PSI树),构建了语法和语义代码模型。PSI树更像是抽象语法树(AST)还是具体语法树(CST)?嗯,似乎生成的PSI树具有两者的特点。
Eli Bendersky关于抽象v.具体语法树的博客在更大的细节范围内很好地解释了两者之间的区别。像一个CST树一样,PSI结构包含所写内容的更正式的表示,包括符号。然而,像AST一样,PSI树在每个节点本身中保留了其他有用的信息。
在IntelliJ IDEA中,您可以下载插件PSIViewer来检查您编写的代码的PSI。您还可以突出显示代码的某些部分,以查看PSIViewer在其呈现的树中选择的内容。
下面的图像显示了PSIViewer如何将5.minus(2)解释为一个名为DOT_QUALIFIED_EXPRESSION的节点,其第一个子节点是INTEGER_CONSTANT 表示5,第二个子节点是DOT表示.,第三个子节点是CALL_EXPRESSION 表示minus(2)。
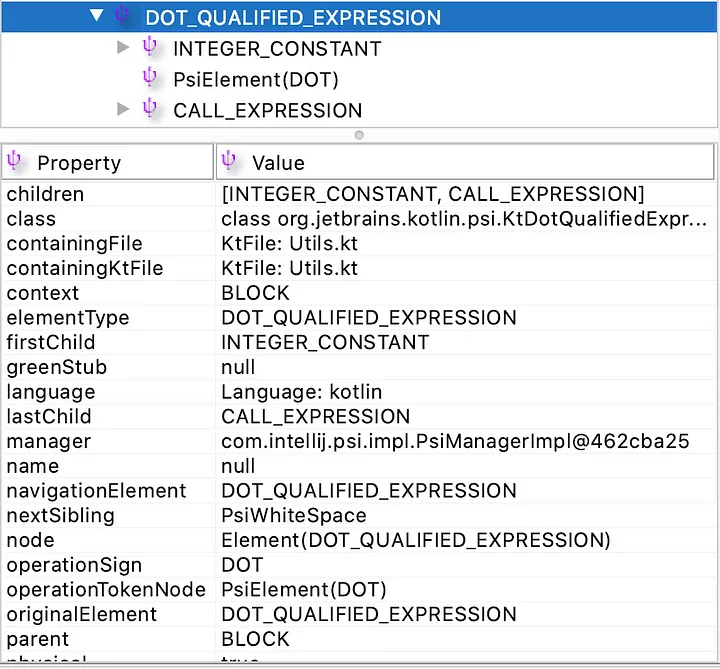
这些PSI元素包含标记,并能够保留可能与其持有关系的子元素和父元素的信息。随着编译器从中构建并生成更多的信息,这些PSI结构变得更加复杂。PSI结构具有CST和AST的特征,虽然它们的结构随着时间的推移变得更加类似于AST。为了讨论和方便起见,我们将用AST的术语来指代这些树。
考虑表达式5—2。生成的AST如下图所示,树的较深色节点表示为元素,较浅色节点表示为标记。
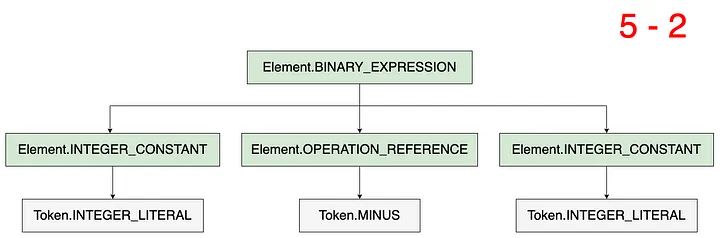
工具PSIViewer将类似的树形结构呈现在您的IntelliJ IDE中,其中所有元素都定义为PsiElement类型。为了简单起见,此图像使用较浅的节点表示令牌(表示为“Token. p s i E l e m e n t ”),使用较暗的节点表示元素(表示为“ E l e m e n t . {psiElement}”),使用较暗的节点表示元素(表示为“Element. psiElement”),使用较暗的节点表示元素(表示为“Element.{psiElement}”)。
表达式5 - 2可以分解为由两个整数常数组成的二元表达式,作为操作数和一个OPERATION_REFERENCE作为运算符。但是,表达式5.minus(2),即使其计算结果与5 - 2相同,其AST结构也完全不同。
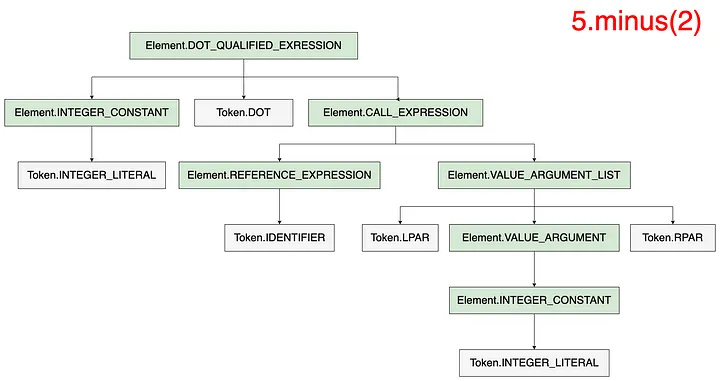
与将5-2定义为BINARY_EXPRESSION不同,5.minus(2)中的DOT_QUALIFIED_EXPRESSION包含了一个CALL_EXPRESSION,其REFERENCE_EXPRESSION是“minus”,VALUE_ARGUMENT_LIST是“(2)”。
PSI树告诉我们代码是如何被终端用户编写的,但目前为止并没有太多信息。这意味着在此阶段,编译器只能告诉我们代码是如何被编写的,但它并不知道代码是否能够编译通过。
无论代码是否正确,都可以构建PSI树。请考虑下面IntelliJ IDEA的屏幕截图。面板左侧显示了Utils.kt中的代码。在main函数中,有两个语句,函数的第二行是5.((2)而不是5.minus(2)。我们知道(IDE也知道)像5.((2)这样的语句将无法编译。但要记住,PSI树不需要知道这一点。它会生成元素,尽管可能无法准确解释层次关系。
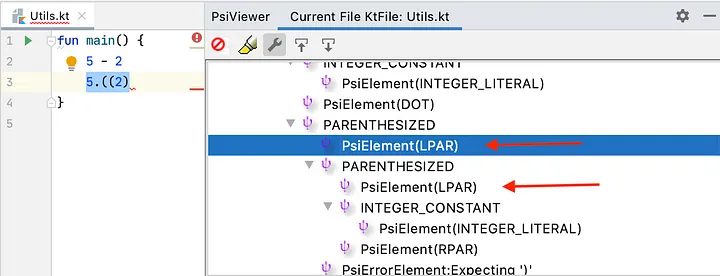
IDE如何能在屏幕截图的左侧窗格中给出红色波浪线?这正是Resolution阶段负责的,这给了我们下一篇文章的完美过渡。下一篇文章将深入探讨Resolution阶段,该阶段创建了必要的分析,帮助判断代码是否可以编译。请关注!
参考
https://www.youtube.com/watch?v=wUGfuWHCqrc&t=281s&ab_channel=KotlinbyJetBrains
https://github.com/ahinchman1/Kotlin-Compiler-Crash-Course/blob/master/README.md