编译器的整个宏观流程
我们先来看看整个编译过程编译器做了那些事情吧。这里我们随便写一个复杂的 Hello World 程序。
#include <stdio.h>
int main(int argc, char* argv[]) {
int age = 45;
if (age >= 17 + 8 + 20) {
printf("Hello old man!\\n");
}
else {
printf("Hello young man!\\n");
}
return 0;
}如果我们要读懂它,我们首先需要读懂每一个单词。int 是 数据类型,age 是 变量名,= 是操作符,45 是 字面变量。我们需要对每个单词认识、理解,这是第一步。下一步,我们光认识每个单词的意思还不够,还需要理解整一个 “int age = 45;” 是什么意思,进而我们接下来要做的就是分析句子的语法结构。这一步就好比我们在学习英语阅读之前,老师都会教我们一些简单句的结构,如:主谓、主谓宾、主系表等。再下一步,当我们完全掌握了程序每一个语句的语法结构以后,就可以对其进行语义分析,了解语句所表达的意思。那么到此为止,编译器已经完全读懂代码所表达的意思了,前面这整个流程我们称作编译器的前端技术。
读懂代码以后,接下来的流程就属于编译器后端技术。进一步,我们需要生成中间代码,然后对代码进行优化,最终生成机器可执行的目标代码。
整个流程图如下。
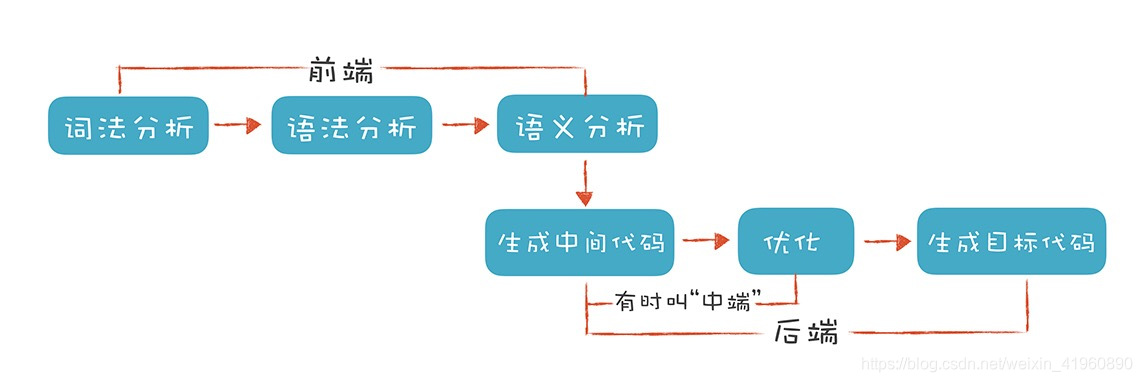
- 前端:编译器对程序代码的分析和理解过程,只跟语言的语法有关,与目标机器无关。
- 后端:申城目标代码的过程,跟目标机器有关。
前端技术详解
我们前面已经通过例子大致认识到什么是编译器的前端技术了,这里我们更详细的分析每一个步骤。
词法分析(Lexical Analysis)
通常,词法分析是编译器的第一项工作。就好比我们做阅读一样,程序的组成也是由一个一个“单词”组成,这里的“单词”我们称为“词法记号”,英文就是 Token。我们继续以上面的代码为例子。
在代码中,我们能够识别 if, else, int 等关键字,main, printf, age 这样的标识符,+, -, = 这样的操作符号,还有花括号,圆括号,分号这样的符号,以及数字字面量,字符串字面量等等。这些都是 Token。
那么如何写一个程序来识别 Token 呢?
这一步也就是NLP里的“分词”操作。我们可以指定相应的规则来区分不同的 Token,例如:
- 识别 age 这样的标识符:以字母开头,后面可以接字母或者数字,直到遇到一个既不是字母也不是数字的字符时结束。
- 识别 >= 这样的操作符:当扫描到一个 > 字符的时候,就要注意,他可能是一个 GT(Greater Than)操作符。但由于 GE(Greater Equal)操作符也是以 > 开头的,因此需要再往下看一位,如果是等于,则Token是GE,否则就是GT。
- 识别 45 这样的数字字面量:当扫描到数字字符的时候,就开始把它看作数字,直到遇到非数字的字符。
这些都是我们所定义出的规则,每个程序员需要跟着对应的规则编写代码,否则代码中的一些Token就无法被编译器识别,或者使编译器产生混乱。下一步,我们需要将对应的规则通过代码表达出来。
规则通常使用“正则文法”表达,符合正则文法的表达式称为“正则表达式”,这个大家应该都有听过。生成工具可以读入正则表达式,生成一种叫“有限自动机”的算法,来完成具体的词法分析任务。
这里的有限自动机怎么理解呢?
有限自动机是有限个状态的自动机器。我们可以拿抽水马桶举例,它分为两个状态:“注水” 和 “水满”。摁下冲马桶的按钮,它转到“注水”的状态,而浮球上升到一定高度,就会把注水阀门关闭,它转到“水满”状态。
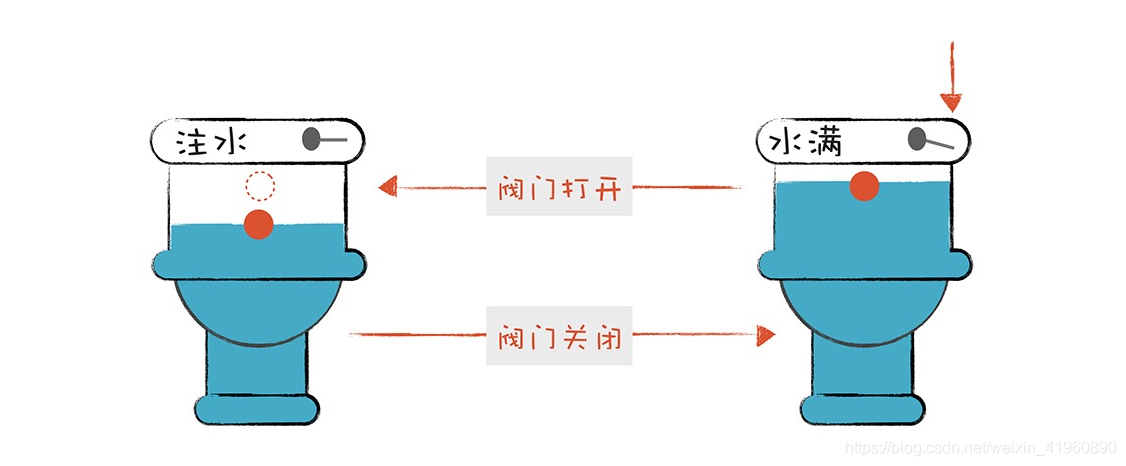
词法分析器也是一样的,只是它含有的状态比较多。它在分析整个程序的字符串,当遇到不同类型字符时候,会趋势它迁移到不同的状态。比如:词法分析器扫描到 age 的时候,是出于“标识符”状态,等他遇到了一个 >= 就切换到了“比较操作符”状态。词法分析的过程,就是一个一个状态转移的过程。

语法分析(Syntactic Analysis)
完成词法分析后,下一步就是语法分析。词法分析已经完成了识别一个一个的单词,而语法分析是在词法分析的基础上识别程序的语法结构。这个结构是一个树状结构,是计算机容易理解和执行的结构。
举个例子。
“我喜欢又聪明又勇敢的你” 这个句子包含了“主、谓、宾”三个部分。主语是“我”,谓语是“喜欢”,宾语部分是“又聪明又勇敢的你”。其中宾语部分又可以拆成两部分,“又聪明又勇敢”是定语部分,用来修饰“你”。定语部分又可以分成“聪明”和“勇敢”两个最小的单位。也就是如下图的表达。
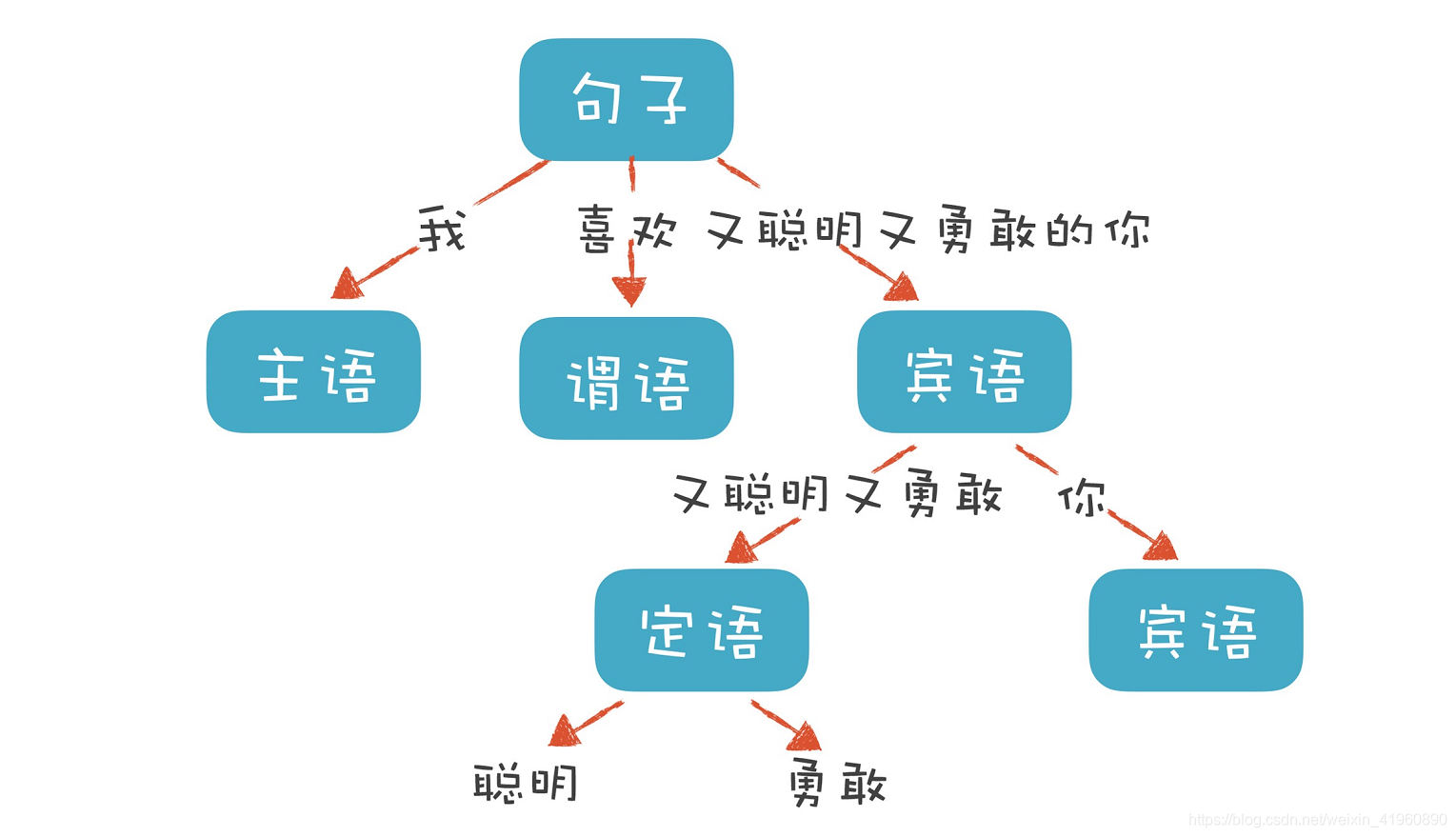
程序也有定义良好的语法结构,它进行语法分析的过程,也就是在构造这一棵树。一个程序就是一棵树,这棵树叫做 抽象语法树(AST)。树的每一个节点(子树)是一个语法单元,这个单元的构成规则就叫“语法”。每个节点下面还可以有下级节点。
我们对上述程序进行AST树的生成,部分结果如下:
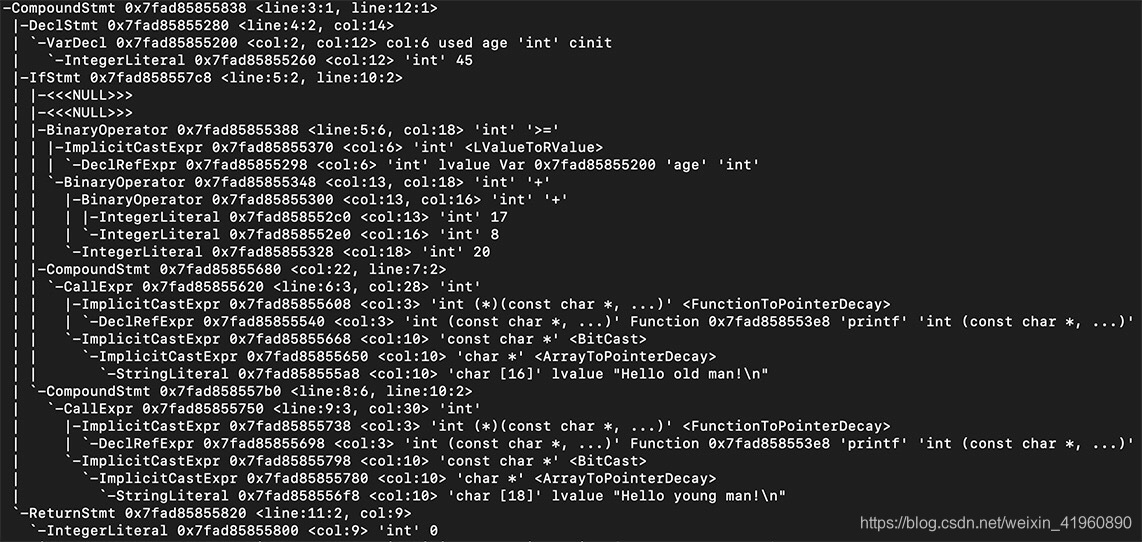
这里有一个网页 https://resources.jointjs.com/demos/javascript-ast,可以更直观的画出 AST 的结构。
如果在其中输入 a + b,我们可以得到一下结果。
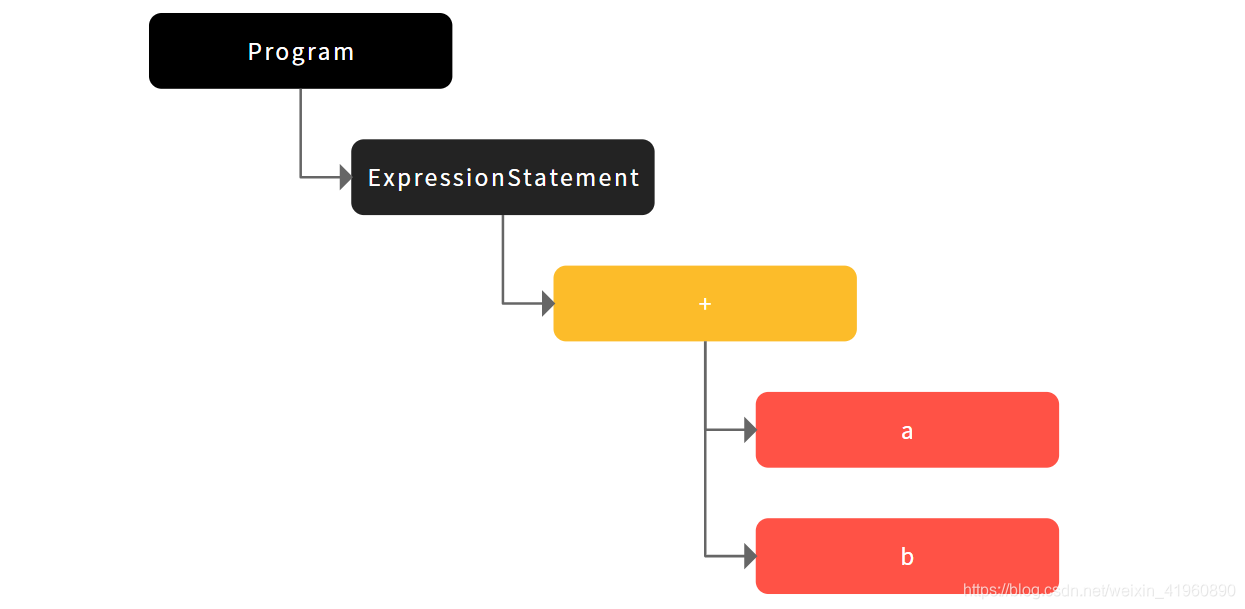
再稍微复杂一点,我们添加一些赋值语句,可以更好地对 AST 有清晰的认识。
var a = 38
var b = 36
c = a+b
形成 AST 后有什么好处呢?方便计算机处理!比如,针对表达式形成的这棵树,从根节点遍历整棵树就可以获得表达式的值。再添加上循环语句,判断语句,赋值语句等节点,我们就相当于实现了一门脚本语言。而执行脚本语言的过程,就是遍历 AST 的过程。
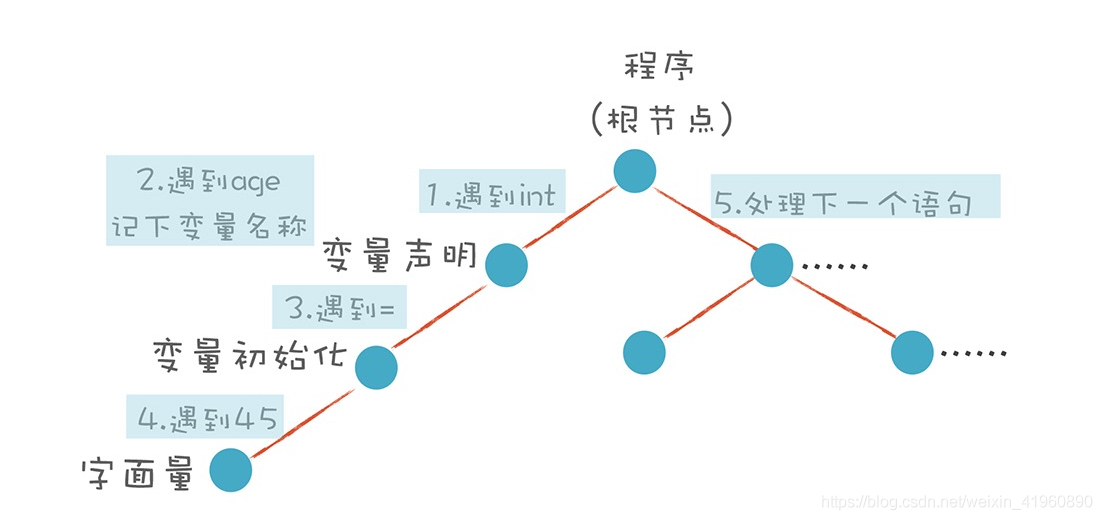
使用递归下降法,自顶向下构造 AST。首先构造根节点,代表整个程序,之后向下扫描 Token 串,构建它的子节点。当它看到一个 int 类型的 Token 时,知道这儿遇到了一个变量声明语句,于是建立一个“变量声明”节点;接着遇到 age,建立一个子节点,这是第一个变量;之后遇到 =,意味着这个变量有初始化值,那么建立一个初始化的子节点;最后,遇到“字面量”,其值是 45。
这样一颗子树就扫描完毕了,陈旭退回到根节点,开始构建第二个子节点。
语义分析(Semantic Analysis)
完成了词法分析和语法分析后,接下来的工作就是完成语义分析,就是让计算机完全理解我们真实的意图。
你可能会觉得理解自然语言的含义已经很难了,所以计算机语言的语义分析也一定很难。其实语义分析没那么复杂,因为计算机语言的语义一般可以表达为一些规则,你只要检查是否符合这些规则就行了。比如:
- 某个表达式的计算结果是什么数据类型?如果有数据类型不匹配的情况,是否要做自动转换?
- 如果在一个代码块的内部和外部有相同名称的变量,我在执行的时候到底用哪个? 就像“我喜欢又聪明又勇敢的你”中的“你”,到底指的是谁,需要明确。
- 在同一个作用域内,不允许有两个名称相同的变量,这是唯一性检查。你不能刚声明一个变量 a,紧接着又声明同样名称的一个变量 a,这就不允许了。
语义分析基本上就是做这样的事情,也就是根据语义规则进行分析判断。
语义分析工作的某些成果,会作为属性标注在抽象语法树上。比如在 age 这个标识符节点和 45 这个字面量节点上,都会标识它的数据类型是 int 型的。
属性完全标注后,我们就可以根据这些信息去生成目标代码啦!
总结
- 词法分析就是完成分词的过程,最终分成一个一个Token,可以根据有限自动机来实现。
- 语法分析就是把程序的结构识别出来,并形成一棵便于计算机处理的抽象语法树。可以用递归下降的算法实现。
- 语义分析是消除语义模糊,生成一些属性信息,添加到AST中,让计算机能够根据这些信息生成目标代码。
个人原创学习笔记,参考极客时间。
