Study on Information Diffusion Analysis in Social Networks and Its Applications
社交网络中的信息扩散分析及其应用研究
给出了本文的概述。我们从第2节介绍一些社交网络。第3节介绍了三种基本的信息传播模型。第4节中列出用于评估权限和影响的方法。第5节和第6节分别介绍了影响最大化和信息源检测的解决方案。最后,在第7节中总结了一些进一步研究的可能方向。
下图是论文框架
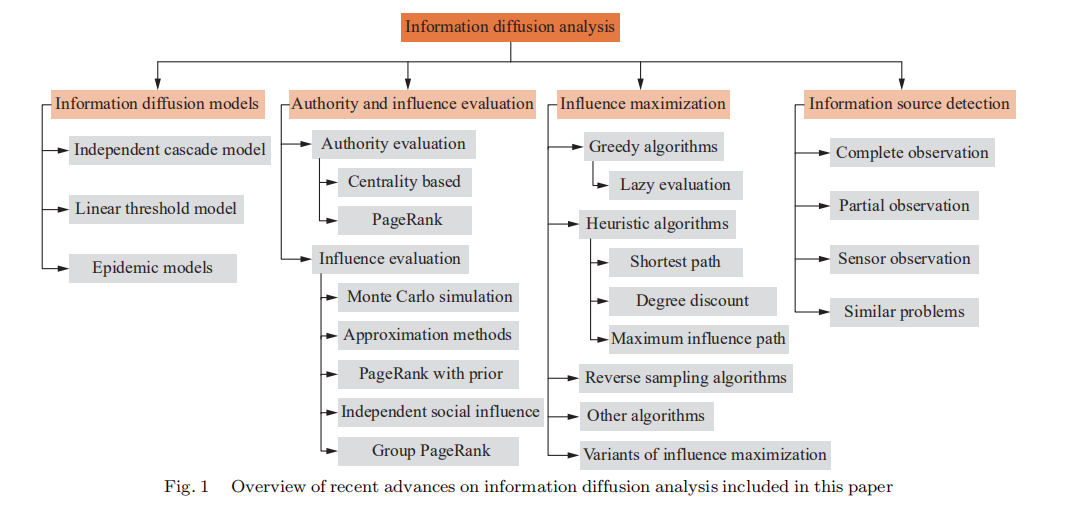
1 介绍
由于社交网络服务的普及,人们越来越关注探索信息如何在这些网络中传播以及用户之间如何相互影响,这种应用具有广泛的应用,例如病毒式营销,重新发布预测和社交推荐。 因此,在本文中,我们回顾了社交网络中信息扩散分析的最新进展及其应用。 具体来说,我们首先阐明几种流行的模型来描述社交网络中的信息传播过程,这可以实现三种实际应用,即影响评估,影响最大化和信息源检测。 然后,我们讨论了如何基于网络结构评估权限和影响。 之后,分别详细讨论影响最大化和信息源检测的当前解决方案。 最后,列出了一些可能的信息扩散分析研究方向,以供进一步研究。
这些社交网络具有开放性(即每个人都可以加入并与外界保持联系),交互作用(即用户可以通过回覆或重新发布来与朋友就电影或事故进行互动)的特征,以及 及时性(即用户可以随时更新状态消息)
口碑效应:用户看到有趣的内容后,就可以将这些内容转发或转发给他们的朋友。 如果他们的朋友也喜欢这些内容,则可以进一步与他们自己的朋友分享这些内容,从而导致信息在网络中传播。
信息如何通过网络传播通常是未知的。 了解大量信息背后的传播机制对于广泛的应用非常重要,例如病毒式营销,社会行为预测,社会推荐和社区检测。这个问题吸引了来自流行病学,计算机科学和社会学等各个领域的研究人员。 他们提出了各种信息扩散模型来描述和模拟此过程,例如独立级联(IC)模型,线性阈值(LT)模型和流行病模型。大多数模型具有传染性,并假定信息开始从源(或种子)节点集中传播,其他节点只能从其邻居访问信息。
发现的传播模型已被应用于许多实际应用中。 例如,首先,通过评估用户的影响力,我们可以确定有影响力的传播者,并找到专家。 其次,通过选择种子用户并解决所谓的影响最大化问题,我们可以最大化受影响用户的数量。 这对于通过口碑效应推广新产品,或放置传感器以快速检测城市供水网络中的污染物具有重要意义。 第三,在信息从一组源节点传播了一段时间之后,它将影响更多的节点。 我们可以根据这些观察到的受影响节点来推断源节点,这称为信息源检测。 它可以帮助防止流行病的爆发,并追踪社交网络中的谣言来源。
2.准备工作
微博网络:
引文网络:
协作网络:
电子邮件网络:
不同种类的信息可以在社交网络中传播,例如创新,对特定事件的看法。当节点采用此类信息,则会受到影响,受影响的节点将进一步将该信息传播到其邻居,即口碑效应,这将导致信息在网络中扩散。因此,除了具体说明之外,每个节点都具有两个状态:活动和非活动。例如,在Twitter中,重新发布有趣推文的用户处于活动状态,而其他用户则处于非活动状态。
有许多网站提供开放的社交网络数据集进行研究。 在这里,我们列出其中一些以方便参考。
Stanford large network dataset collection。 它是从数以万计的节点和边缘到数以千万计的节点和边缘的50多个大型网络数据集的集合,包括社交网络,Web图形,道路网络,Internet网络,引用网络,协作网络和通信网络 。
Aminer6。 它提供了用于社交网络分析的外部数据集的存储库,包括微博网络,Patentminer.org的专利数据集,知识链接数据集,移动数据集和其他在线社交网络。
Social computing data repository。 它托管来自许多不同社交媒体站点的数据集,其中大多数具有博客功能,例如BlogCatalog,Twitter,MyBlogLog,Digg,StumbleUpon,del.icio.us,MySpace,LiveJournal,非官方Apple Weblog(TUAW),Reddit 等
Koblenz Network Collection (KONECT)。 是一个收集大型网络数据集以进行网络科学及相关领域研究的项目。 它包括数百个各种类型的网络数据集,包括有向,无向,两方,加权,未加权,有符号和评级网络。
3 信息传播模型
许多研究者从各个领域研究信息在网络中的传播过程,它们大多具有传染性并且通常遵循以下两个原则:
1)每条信息的扩散都始于几个源节点。
2)每个传播者只能从其邻居那里访问该信息。
所有信息传播模型都与规则2一致,但是以不同的方式实现规则2。它们可以分为两类:渐进模型(progressive models),其中节点可以从非活动状态切换为活动状态,但不能在另一个方向上进行切换; 非渐进模型(progressive models),其中节点可以在两个方向进行转换,并允许多次。在下一部分中,我们将介绍三种基本的信息传播模型,即独立级联(IC)模型,线性阈值(LT)模型和流行模型,这些模型已被广泛使用,并且对于个人影响力评估,影响力最大化等至关重要。
3.1 独立级联模型(IC)
它假定信息从遵循规则1的一组活动种子节点$A_{0}$开始。对于病毒式营销,$A_{0}$是拥有折扣并愿意在其朋友中促销产品的一群用户。在该模型中,每个活动节点无法切换回非活动状态。随着时间的流逝,非活动节点可以从活动节点接收信息。在时刻t,$A_{t}$是一组处于活动状态的节点,对于$A_{t}$中的一个节点u,它只有一次机会以概率$w_{uv}$去影响非活动状态的邻居节点v。如果节点v成功被激活为活动状态,节点v将在下一个时刻t+1时以相同的方式去影响其他节点;如果节点v有不止一个处于活动状态的邻居节点,那么这些邻居节点对节点v的影响是相互独立的,这解释了独立级联模型是如何遵循规则2的。这个过程将一直进行,直到没有更多的节点被激活为止。
独立级联模型是渐进随机的,所以最终处于活动状态的节点集合$A_{\infty }$可能会随活动种子节点的选择不同而不同。
3.2 线性阈值模型(LT)
假设每个节点v都有一个特定的阈值$\theta _{v}$,该阈值从间隔[0,1] 中均匀采样,且$\sum _{u\in V}w_{uv}\leq 1$。
同样假定信息从遵循规则1的一组活动种子节点$A_{0}$开始,它的传播过程是以离散的步骤进行的。在第t步,上一步中处于活动状态的节点将保持活动状态,对于非活动节点v,如果下式成立,则被激活(1):
$\sum _{u\in N_{in}(v))}w_{uv}\geq \theta _{v}$
这个过程也将一直进行,直到没有更多的节点被激活为止。我们可以看到不活动的节点变为活动状态的概率随着其更多邻居变得活动而单调增加。而且,v的阈值可以视为v的邻居的加权分数。
LT和IC的区别在于:LT允许活动节点多次影响非活动节点,而IC只有一次机会;LT让父节点对子节点的作用是加权的,而在IC中作用是独立的。
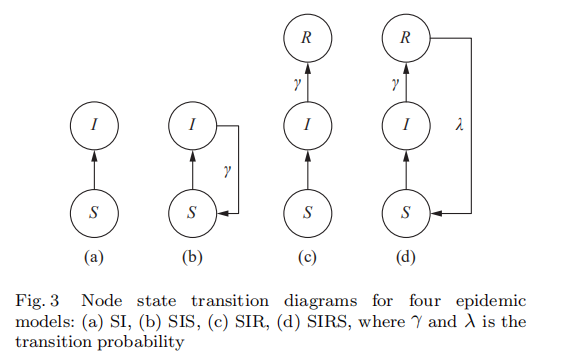
3.3 传染病模型
一些研究人员采用流行病模型来模拟网络中节点的感染和恢复过程,最初是在流行病学中描述疾病如何在人群中传播。同上,假定信息/传染病从遵循规则1的一组活动种子节点$A_{0}$开始。
最简单的是susceptible-infected(SI)模型,它假定每个节点都有两种可能的状态:易感(susceptible)和感染(infected)。 当节点处于易感状态时,它可能会被信息感染。一旦节点u受感染,那么它将永远保持感染的状态,并且以它只有一次机会以概率$w_{uv}$去影响易感状态的邻居节点v,这种传播过程是独立的。
7结论和未来发展
总而言之,我们回顾了社交网络中信息传播分析的最新进展及其在本文中的应用。具体来说,我们首先介绍了三种典型的信息扩散模型,即独立级联(IC)模型,线性阈值(LT)模型和流行病模型,它们可用于描述信息如何在网络中扩散。然后,我们展示了三个实际问题:权威和影响力评估,影响力最大化以及信息源检测。社交网络中的权威和影响力评估对于有影响力的吊具识别和专家发现很重要,而影响力最大化则有助于病毒式营销和传感器放置。信息源检测具有广泛的应用,例如流行病爆发的预防和社交网络中谣言源的追踪。尽管已为解决这些问题做出了许多努力,但仍有一些改进空间。在这里,我们将列出一些可能的方向,以供进一步研究。
首先,当前的信息传播模型具有完善的理论属性可用于进一步分析,但简化了实际上非常复杂的现实情况。 用户可以从外部资源(例如电视,报纸和其他网站)访问信息,而不仅仅是从社交网络中的邻居访问信息。 此外,网络中可能同时传播多种类型的信息,例如竞争产品的信息。 因此,有希望在外部影响下对异构社会网络中的多种信息传播进行建模。 例如,迈尔斯(Myers)等人提出了一种模型,其中信息可以通过社交网络的链接或通过外部来源的影响到达节点。 此外,詹等研究了在线社交网络中多个部分对齐的异构环境中的影响最大化问题。
其次,大的可伸缩性是在现实应用中,尤其是对于大型网络,应用影响力最大化和信息源检测的最大挑战之一。 Borgs等人提出了反向采样算法后,影响最大化的解决方案有了很大的进步,因此,我们可以像Nguyen等人那样借鉴经验,加快信息源检测的解决方案。 此外,在分布式编程中实现这些解决方案是另一个实用的方向。
第三,大多数当前解决方案都适用于静态网络,而他们却忽略了网络是动态且不断发展的。 例如,用户可能会在一段时间内取消关注他的一些朋友,并且他的个人兴趣可能会在不同主题上发生变化。 也就是说,不同用户之间的联系强度随时间变化。 我们应该考虑到这一事实,以便更好地分析社交网络中的信息传播。
第四,深度学习最近已应用于社交网络分析的许多任务,例如网络嵌入(network embedding)和链接预测(link prediction)。 社交网络中信息传播的真实过程非常复杂,有时甚至无法观察。 我们可以设计深度学习方法来分析信息扩散吗? 例如,当我们将网络结构和用户属性(例如年龄,性别,职位)输入到基于深度学习的模型中时,我们可以输出该用户的影响力。 Bourigault等人 提出了一种用于社交网络中信息源检测的表示学习方法。 它既不依赖于已知的扩散图也不依赖于假设的扩散定律,而是直接从扩散记录中推断出来源。
最后,将信息传播分析与其他实际问题结合起来很有吸引力,例如针对社会用户的行为预测[8,133,134]。例如,社交用户通常同时受到多个公司的影响,不仅用户利益,而且这些社交影响都将影响用户的消费行为。 Ma等[135]提出了一种一般方法,要同时考虑目标用户的兴趣和多种社会影响因素,从而确定进行社会营销的目标用户。有价值的用户应具有最佳的平衡影响熵(“犹豫”)和效用得分(“感兴趣”)。 Wu et al。[133]以潜在的社会理论来解释和建模用户的两种行为的演变:用户的偏好(反映在用户-项目交互行为中)和社交网络结构(反映在用户-用户交互行为中)。徐等。[8]试图揭示社交传播如何影响出租车司机未来行为的预测。