对卷积的理解:https://www.zhihu.com/question/22298352
卷积层(特征提取)
假如有一幅1000*1000的图像,如果把整幅图像作为向量,则向量的长度为1000000(10^6)。在假如隐含层神经元的个数和输入一样,也是1000000;那么,输入层到隐含层的参数数据量有10^12,妈呀,什么样的机器能训练这样的网络呢。所以,我们还得降低维数,同时得以整幅图像为输入(人类实在找不到好的特征了)。于是,牛逼的卷积来了。接下来看看卷积都干了些啥。
局部感知(卷积核大小):
卷积神经网络有两种神器可以降低参数数目,第一种神器叫做局部感知野。一般认为人对外界的认知是从局部到全局的,而图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。网络部分连通的思想,也是受启发于生物学里面的视觉系统结构。视觉皮层的神经元就是局部接受信息的(即这些神经元只响应某些特定区域的刺激)。如下图所示:左图为全连接,右图为局部连接。

在上右图中,假如每个神经元只和10×10个像素值相连,那么权值数据为1000000×100个参数,减少为原来的千分之一。而那10×10个像素值对应的10×10个参数,其实就相当于卷积操作。
权值共享(卷积操作,卷积核移动):
但其实这样的话参数仍然过多,那么就启动第二级神器,即权值共享。在上面的局部连接中,每个神经元都对应100个参数,一共1000000个神经元,如果这1000000个神经元的100个参数都是相等的,那么参数数目就变为100了。
怎么理解权值共享呢?
我们可以这100个参数(也就是卷积操作)看成是提取特征的方式,该方式与位置无关。这其中隐含的原理则是:图像的一部分的统计特性与其他部分是一样的。这也意味着我们在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征。
更直观一些,当从一个大尺寸图像中随机选取一小块,比如说 8×8 作为样本,并且从这个小块样本中学习到了一些特征,这时我们可以把从这个 8×8 样本中学习到的特征作为探测器,应用到这个图像的任意地方中去。特别是,我们可以用从 8×8 样本中所学习到的特征跟原本的大尺寸图像作卷积,从而对这个大尺寸图像上的任一位置获得一个不同特征的激活值。
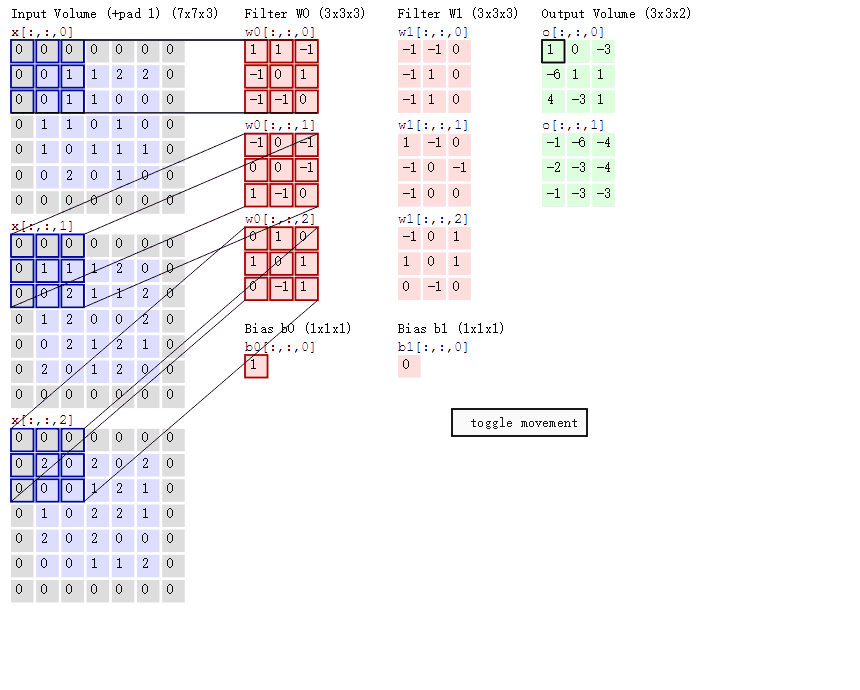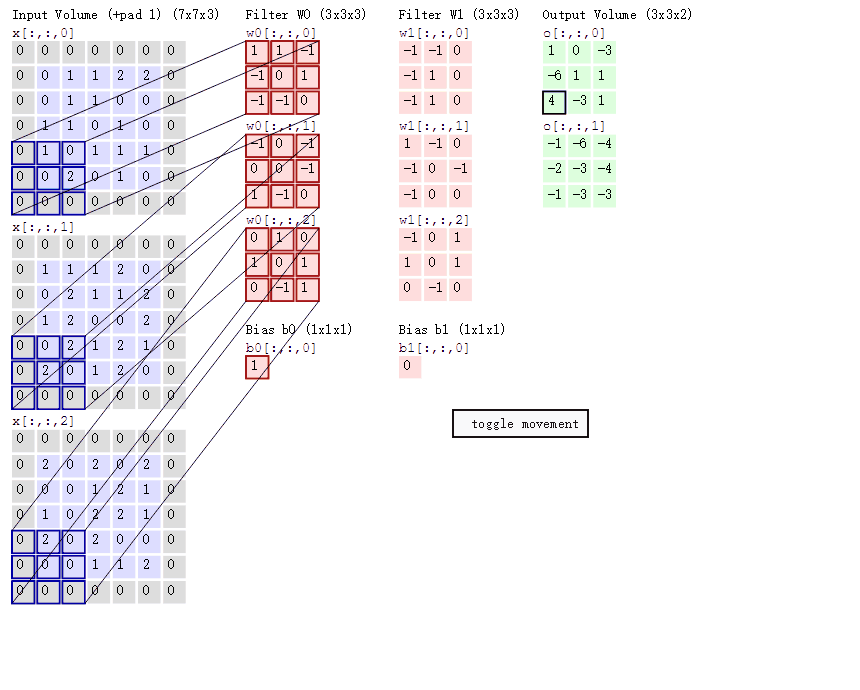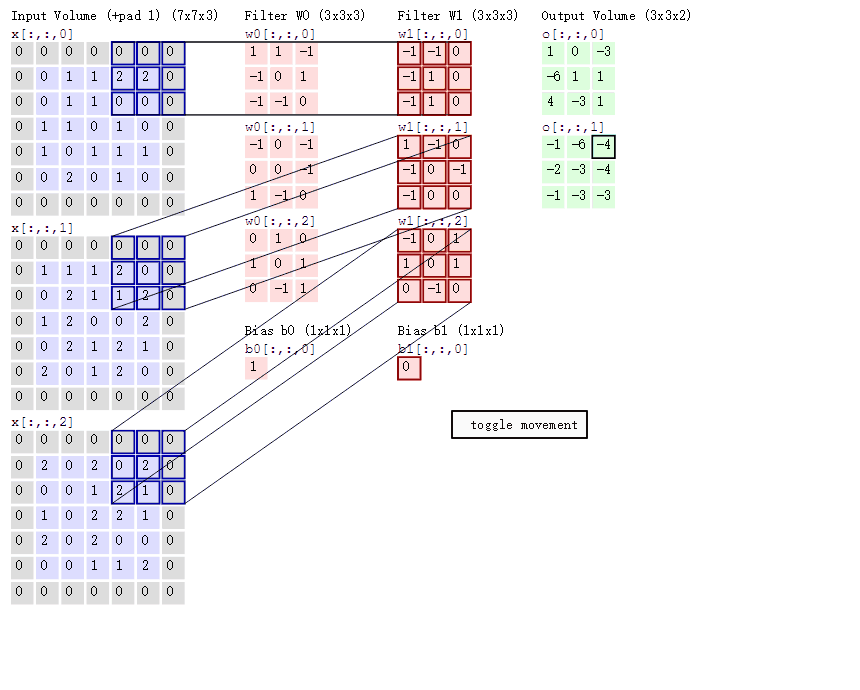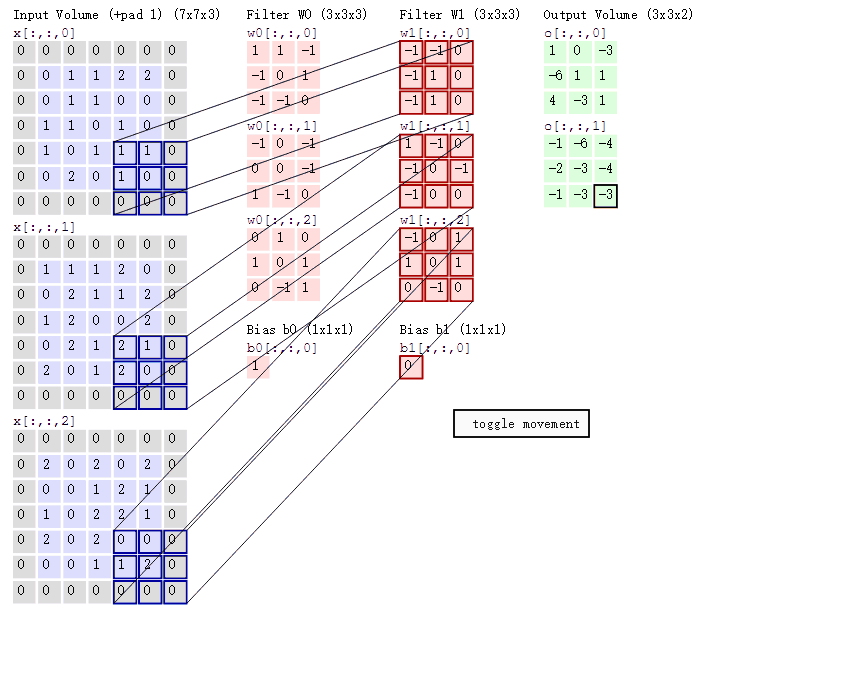
如下图所示,展示了一个3*3的卷积核在5*5的图像上做卷积的过程。每个卷积都是一种特征提取方式,就像一个筛子,将图像中符合条件(激活值越大越符合条件)的部分筛选出来。

多卷积核:
上面所述只有100个参数时,表明只有1个100*100的卷积核,显然,特征提取是不充分的,我们可以添加多个卷积核,比如32个卷积核,可以学习32种特征。在有多个卷积核时,如下图所示
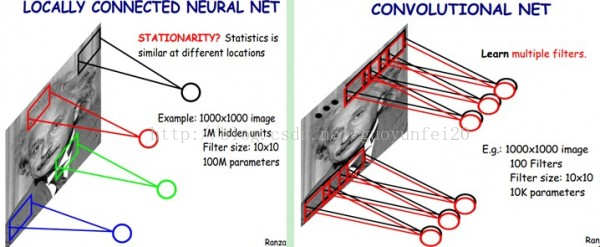
上图右,不同颜色表明不同的卷积核。每个卷积核都会将图像生成为另一幅图像。比如两个卷积核就可以将生成两幅图像,这两幅图像可以看做是一张图像的不同的通道。如下图所示:

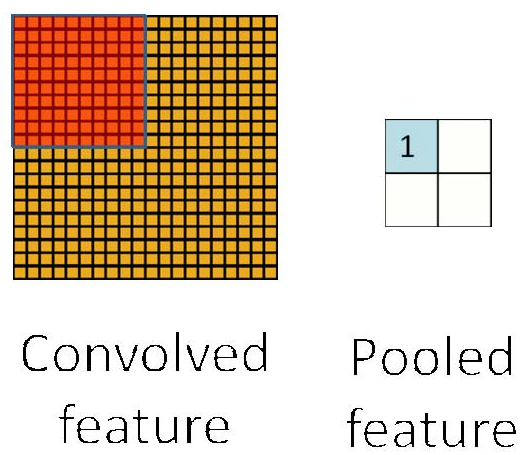
池化层(对输入的特征图进行压缩,1.使特征图变小,简化网络计算复杂度;2.进行特征压缩,提取主要特征;3.降低过拟合,减小输出大小的结果,它同样也减少了后续层中的参数的数量。)
也叫下采样层,其具体操作与卷基层的操作基本相同,只不过下采样的卷积核为只取对应位置的最大值、平均值等(最大池化、平均池化),并且不经过反向传播的修改。
全连接层
全连接层(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。在实际使用中,全连接层可由卷积操作实现:对前层是全连接的全连接层可以转化为卷积核为1x1的卷积;而前层是卷积层的全连接层可以转化为卷积核为h*w的全局卷积,h和w分别为前层卷积结果的高和宽。
目前由于全连接层参数冗余(仅全连接层参数就可占整个网络参数80%左右),近期一些性能优异的网络模型如ResNet和GoogLeNet等均用全局平均池化(global average pooling,GAP)取代FC来融合学到的深度特征,最后仍用softmax等损失函数作为网络目标函数来指导学习过程。需要指出的是,用GAP替代FC的网络通常有较好的预测性能。具体案例可参见我们在ECCV’16(视频)表象性格分析竞赛中获得冠军的做法:「冠军之道」Apparent Personality Analysis竞赛经验分享 - 知乎专栏 ,project:Deep Bimodal Regression for Apparent Personality Analysis
在FC越来越不被看好的当下,我们近期的研究发现,FC可在模型表示能力迁移过程中充当“防火墙”的作用。具体来讲,假设在ImageNet上预训练得到的模型 ,则ImageNet可视为源域(迁移学习中的source domain)。微调(fine tuning)是深度学习领域最常用的迁移学习技术。针对微调,若目标域(target domain)中的图像与源域中图像差异巨大(如相比ImageNet,目标域图像不是物体为中心的图像,而是风景照),不含FC的网络微调后的结果要差于含FC的网络。因此FC可视作模型表示能力的“防火墙”,特别是在源域与目标域差异较大的情况下,FC可保持较大的模型capacity从而保证模型表示能力的迁移。(冗余的参数并不一无是处)(冗余的参数并不一无是处) 注1: 有关卷积操作“实现”全连接层,有必要多啰嗦几句。以VGG-16为例,对224x224x3的输入,最后一层卷积可得输出为7x7x512,如后层是一层含4096个神经元的FC,则可用卷积核为7x7x512x4096的全局卷积来实现这一全连接运算过程,其中该卷积核参数如下:“filter size = 7, padding = 0, stride = 1, D_in = 512, D_out = 4096”经过此卷积操作后可得输出为1x1x4096。如需再次叠加一个2048的FC,则可设定参数为“filter size = 1, padding = 0, stride = 1, D_in = 4096, D_out = 2048”的卷积层操作。
注1: 有关卷积操作“实现”全连接层,有必要多啰嗦几句。以VGG-16为例,对224x224x3的输入,最后一层卷积可得输出为7x7x512,如后层是一层含4096个神经元的FC,则可用卷积核为7x7x512x4096的全局卷积来实现这一全连接运算过程,其中该卷积核参数如下:“filter size = 7, padding = 0, stride = 1, D_in = 512, D_out = 4096”经过此卷积操作后可得输出为1x1x4096。如需再次叠加一个2048的FC,则可设定参数为“filter size = 1, padding = 0, stride = 1, D_in = 4096, D_out = 2048”的卷积层操作。