利用scrapy框架实现股票信息爬取
文章开始把我喜欢的这句话送个大家:这个世界上还有什么比自己写的代码运行在十万人的电脑上更酷的事情吗,如果有那就是让这个数字再扩大十倍。通过一周的课余时间终于基本搞懂了python爬虫,本文就是利用scrapy实现的第一个爬虫,欢迎指正。
目标:获取上交所和深交所所有股票的名称和交易信息共四千条股票信息(大概跑了八小时,灰常的慢)
输出:保存到文件BaiduStockInfo.text中去
技术路线:scrapy框架&&requests库&& BeautifulSoup库
获取股票列表:
东方财富网:http://quote.eastmoney.com/stock/
获取个股信息:
百度股票: https://gupiao.baidu.com/stock/
https://gupiap.baidu.com/stock/sz002439.html
另外多说一句本人查看了这三大网站的robots协议(毕竟老师的教诲不敢忘!!!)发现确实存在不允许爬取的,但是小编也确实记得老师说过爬虫规模不大,不用做商业用途时是可以爬取的,so..........
下面上代码:
import requests
from bs4 import BeautifulSoup
import tracebackimport re
def getHTMLText(url, code="utf-8"):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = code #手工查看code为utf-8 避免访问全网页,提高速度
return r.text
except:
return ""
def getStockList(lst, stockURL):
html = getHTMLText(stockURL, "GB2312")
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('a')
for i in a:
try:
href = i.attrs['href']
lst.append(re.findall(r"[s][hz]\d{6}", href)[0]) #[0]!!!!!!!!
except:
continue
def getStockInfo(lst, stockURL, fpath):
count = 0
for stock in lst:
url = stockURL + stock + ".html"
html = getHTMLText(url)
try:
if html=="":
continue
infoDict = {}
soup = BeautifulSoup(html, 'html.parser')
stockInfo = soup.find('div',attrs={'class':'stock-bets'}) #具体看页面元素
name = stockInfo.find_all(attrs={'class':'bets-name'})[0] #
infoDict.update({'股票名称': name.text.split()[0]})
keyList = stockInfo.find_all('dt')
valueList = stockInfo.find_all('dd')
for i in range(len(keyList)):
key = keyList[i].text
val = valueList[i].text
infoDict[key] = val
with open(fpath, 'a', encoding='utf-8') as f:
f.write( str(infoDict) + '\n' )
count = count + 1
print("\r当前进度: {:.2f}%".format(count*100/len(lst)),end="") #进度条
except:
count = count + 1
print("\r当前进度: {:.2f}%".format(count*100/len(lst)),end="")
continue
def main():
stock_list_url = 'http://quote.eastmoney.com/stocklist.html'
stock_info_url = 'http://gupiao.baidu.com/stock/'
output_file = 'E:/BaiduStockInfo.txt'
slist=[]
getStockList(slist, stock_list_url)
getStockInfo(slist, stock_info_url, output_file)
main()
以上便是全部代码,技术路线也很清晰明了,毕竟scrapy为程序员提供了非常方便的框架如下图所示:毕竟scrapy还是比较好上手的
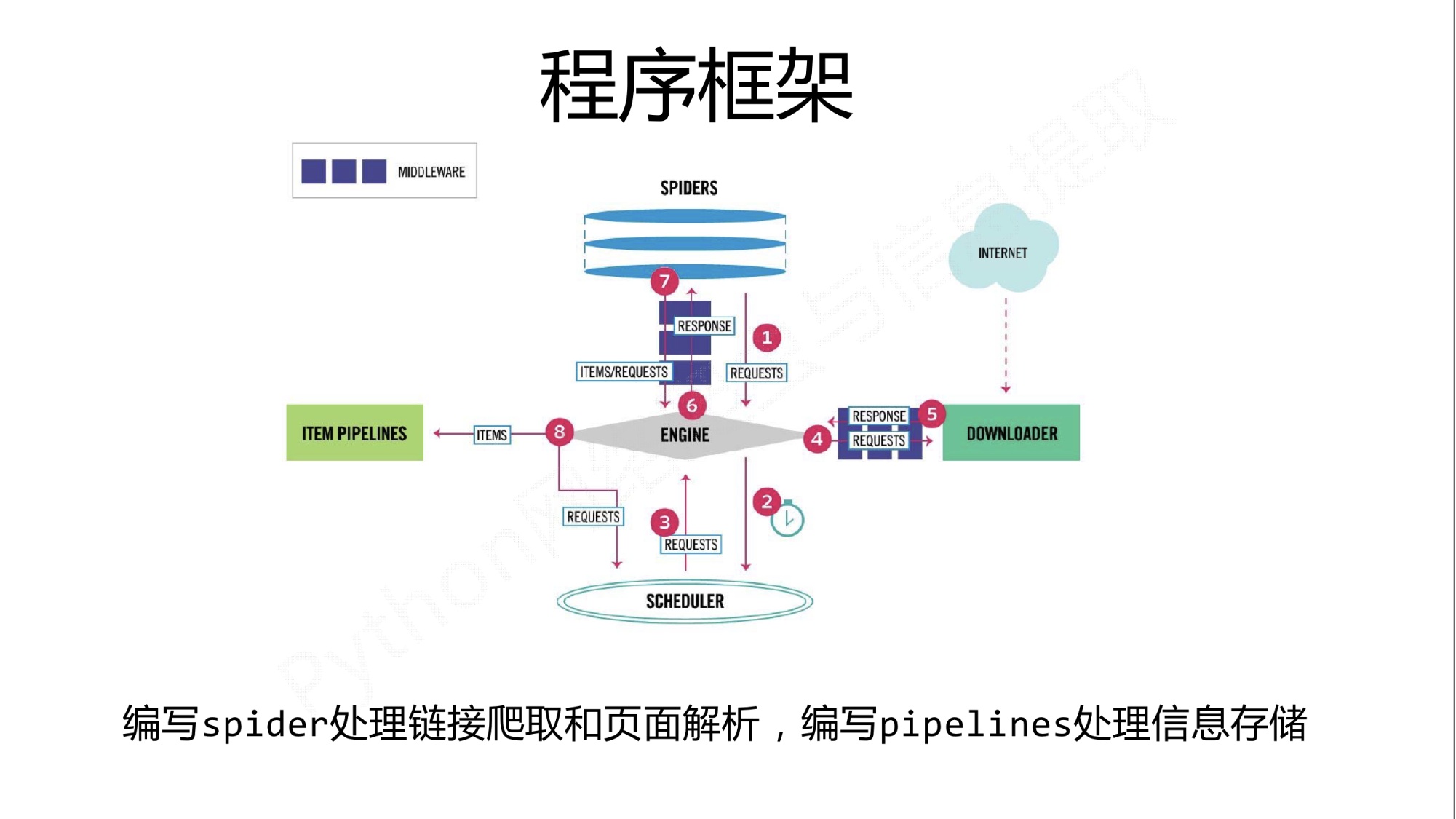
另附上输出文本的截图

第一篇博客,第一个爬虫,要努力的还有很多很多,不喜勿喷,加油吧自己!
加油吧,程序员!