LSTM-Attention模型:Effective Approaches to Attention-based Neural Machine Translation
编程语言
2020-02-13 18:04:31
阅读次数: 0
参考链接
模型(model):
【1】Neural Machine Translation(NMT):
- 神经机器翻译(NMT)是直接用神经网络去模拟条件概率:
p(x∣y)
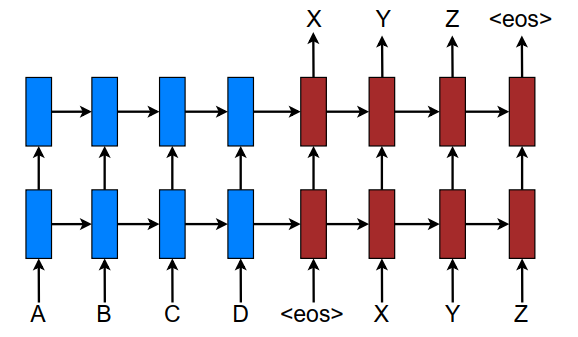
- NMT一般由两个部分组成:
encoder+decoder,
encoder部分读入源句子输出该句子的表示 (representation
S),
decoder部分接受
encoder部分的输出+
decoder已经输出的目标词作为输入并输出一个目标词。因此条件概率可以分解为:
logp(y∣x)=x=1∑mlogp(yj∣y<j,s)
- 用
decoder去模拟该条件概率,因此可以进一步写作:
logp(y∣x)=softmax(g(hj))
g函数的输出向量的维数=词汇表的大小;
hj是RNN隐藏状态向量,其公式如下:
hj=f(hj−1,s)
f是RNN的单元可以是:标准的RNN单元、GRU单元和LSTM单元。
- 模型图:
- 这篇论文使用的模型是多层的LSTM+Attention机制;损失函数(目标函数):
Jt=(x,y)∈D∑−logp(y∣x)
D是语料库
【2】Attention-based Models
-
论文中讲了两种模型:
global 和
local;两个模型图如下:
-
Global Attention:
- 模型图正如上图所示现在解释一下里面的变量:
-
ct:上下文向量;生成它是需要考虑
encoder的所有隐藏层状态向量
ht
-
at:对其向量(alignment vector);它的长度是可变的,其长度等于源句子的长度,计算公式如下:
at(s)=align(ht,hs)=∑s′exp(score(ht,hs′))exp(socre(ht,hs))
score函数有三种形式:
socre(ht,hs))=⎩⎪⎨⎪⎧htThshtTWahshaTtanh(Wa[ht;hs])dotgeneralconcat
-
对于每个输入词
ws经过
encoder都会产一个隐藏状态向量
hs,当
decoder在翻译第
t个词
wt时,
decoder先产生当前的隐藏状态向量
ht,然后根据
at(s)公式,为每个输入词
ws计算出一个权值
as(实数),所有输入词的权值拼接成一个向量
a;即对齐向量(alignment vector);这也是为啥对齐向量长度为什么等于源句子长度的原因。对其向量的本质就是每个输入词的权重,这样我们根据该权重向量将输入词的隐藏状态向量
hs进行加权平均得到上下文向量
Ct
-
注意: 模型是使用多层的LSTM网络,上面所用的隐藏状态向量都是最顶层的LSTM的隐藏状态向量。
-
Local Attention:
-
LocalAttention:选择性地关注输入句子中的一小窗口;这样可以减少计算量。
- 第一步:在原句子中找到一个关注中心点
pt,
- 第二步:确定关注区间
[pt−D,pt+D];D是事先被设置的常数。
- 第三步:按照
GlobalAttention同样方法计算对其向量
a和上下文向量
ct,区别在于在
LocalAttention中只对窗口
[pt−D,pt+D]中的输入进行计算,而
GlobalAttention对整个输入句子进行计算。由此可知
LocalAttention对其向量
a长度是固定的,其长度为窗口长度
D+1.
- 确定中心点
pt有两种方法:
- Monotonic alignment (local-m) :假设输入句子与输入句子单调对齐,直接令
pt=t。
- Predictive alignment (local-p):先按照下面公式预测
pt点:
pt=S∗sigmoid(vpTtanh(Wpht))其中
Wp和
vp是可学习的参数;
S是源句子的长度;则
pt∈[0,S]是个实数; 这种情况下我们对齐向量
a的计算方式也有所不同:
at(s)=align(ht,hs)exp(−2σ2(s−pt)2)其中
σ=2D;
s是窗口
[pt−S,pt+S]内的整数。
-
Input-feeding Approach:
- 模型图:
- Input-feeding Approach 将上一步注意力向量(attentional vectors)
ht~与当前步的输入进行拼接
[tildeht;x]作为当前时刻
decoder的输入以产生当前位置的目标词
y。
- 这种做法的效果:
- 使得当前模型充分考虑以前的对齐选择(alignment choices)。
- 这使得我们可以创建了一个非常深的网络,并且横跨水平和垂直方向。
-
global 和
local两个模型的公共部分
-
GlobalAttention和
LocalAttention不同之处在于:上下文向量
ct的生成;其余部分都是相同的。
- 注意力向量
h~t的生成:
h~t=tanh(Wc[ct;ht])相对先将向量
ct和
ht进行拼接,再将其输入到一个全连接的前馈神经网络中产生了注意力向量
h~t.
- 目标词
yt的生成:将
h~t输入到softmax层产生当前目标词
yt的条件概率分布:
p(yt∣y<t,x)=softmax(Wsh~t)
发布了105 篇原创文章 ·
获赞 60 ·
访问量 3万+
转载自blog.csdn.net/ACM_hades/article/details/104284606