大数据技术之Sqoop
第1章 Sqoop简介
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql…)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Sqoop项目开始于2009年,最早是作为Hadoop的一个第三方模块存在,后来为了让使用者能够快速部署,也为了让开发人员能够更快速的迭代开发,Sqoop独立成为一个Apache项目。
Sqoop2的最新版本是1.99.7。请注意,2与1不兼容,且特征不完整,它并不打算用于生产部署。
第2章 Sqoop原理
将导入或导出命令翻译成mapreduce程序来实现。
在翻译出的mapreduce中主要是对inputformat和outputformat进行定制。
第3章 Sqoop安装(搭建)
安装Sqoop的前提是已经具备Java和Hadoop的环境。
3.1 下载并解压Sqoop架包
mkdir /usr/local/sqoop
cd /usr/local/sqoop
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
rm -rf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
3.2修改配置文件(在conf下)
- 重命名配置文件
cd /usr/local/sqoop/sqoop-1.4.7.bin__hadoop-2.6.0/conf/
cp sqoop-env-template.sh sqoop-env.sh
- 修改配置文件
sqoop-env.sh
vim sqoop-env.sh
export HADOOP_COMMON_HOME=/usr/local/hadoop/hadoop-2.9.2
export HADOOP_MAPRED_HOME=/usr/local/hadoop/hadoop-2.9.2
export HIVE_HOME=/usr/local/hive
export ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.4.10
export ZOOCFGDIR=/usr/local/zookeeper/zookeeper-3.4.10
export HBASE_HOME=/usr/local/hbase
3.3 上传架包
上传一个mysql的驱动jar包到sqoop的安装目录的lib中
mysql-connector-java-5.1.39.jar
cd ../lib/
3.4 验证启动(在bin目录下)
cd ../bin/
./sqoop-version
./sqoop-list-databases --connect jdbc:mysql://localhost:3306 --username root --password 123456
./sqoop-list-tables --connect jdbc:mysql://localhost:3306 --username root --password 123456
第4章 Sqoop的简单使用案例
4.1 导入数据
在Sqoop中,“导入”概念指:从非大数据集群(RDBMS)向大数据集群(HDFS,HIVE,HBASE)中传输数据,叫做:导入,即使用import关键字。
4.1.1 RDBMS到HDFS
- 确定Mysql服务开启正常
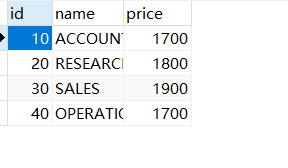
- 在Mysql中新建一张表并插入一些数据
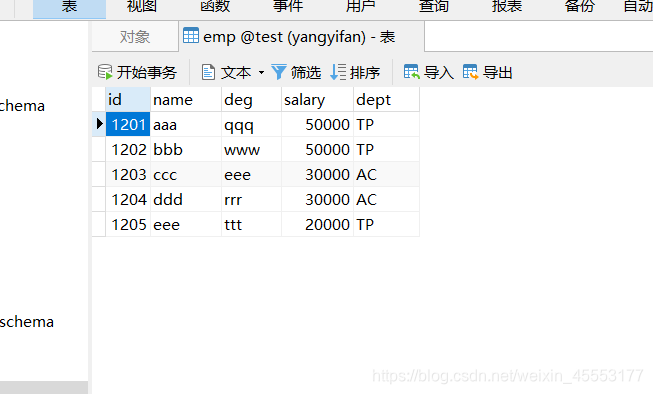 3) 导入数据
3) 导入数据
(1)全部导入(将MySql中emp表导入到HDFS)
./sqoop import \
> --connect jdbc:mysql://localhost:3306/test \
> --username root \
> --password 123456 \
> --table emp \
> --m 1
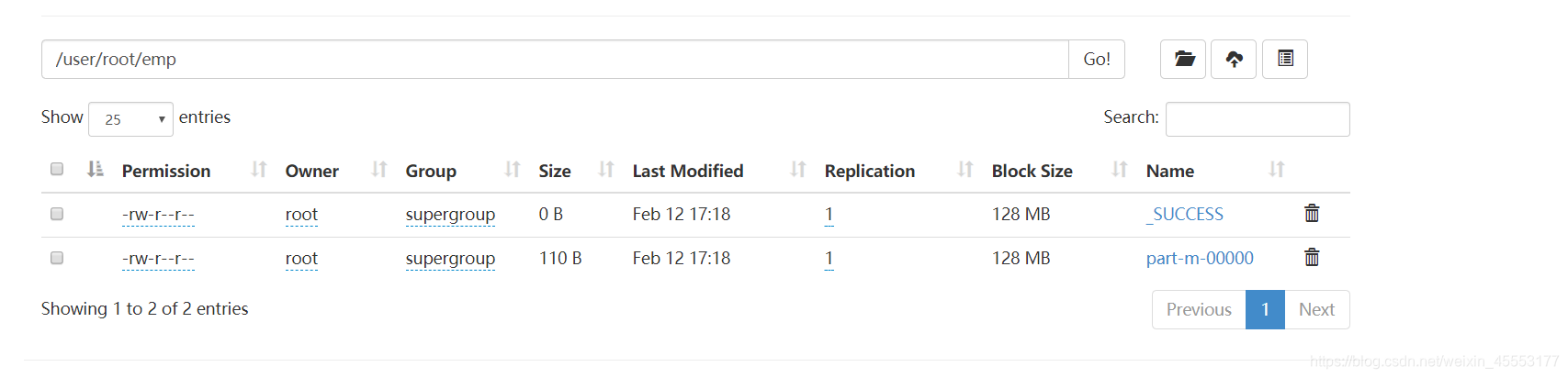 查询
查询
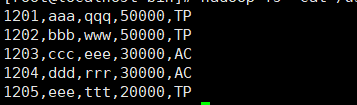
hadoop fs -cat /user/root/emp/part-m-00000
(1)全部导入(将MySql中emp表导入到HDFS的指定目录)
./sqoop import \
--connect jdbc:mysql://localhost:3306/test \
--username root \
--password 123456 \
--target-dir /emp \
--delete-target-dir \
--fields-terminated-by '\001' \
--table emp \
--m 1
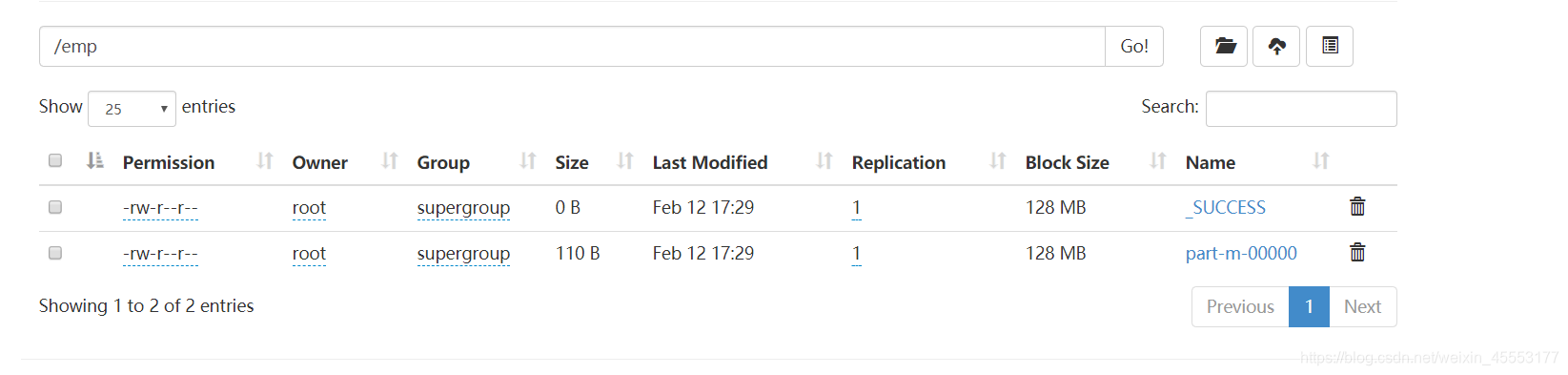 查询
查询
hadoop fs -cat /emp/part-m-00000

(2)查询导入
./sqoop import \
--connect jdbc:mysql://localhost:3306/test \
--username root \
--password 123456 \
--target-dir /emp3 \
--fields-terminated-by '\001' \
--delete-target-dir \
--m 1 \
--query 'select id,name from emp where salary <= 30000 and $CONDITIONS;'
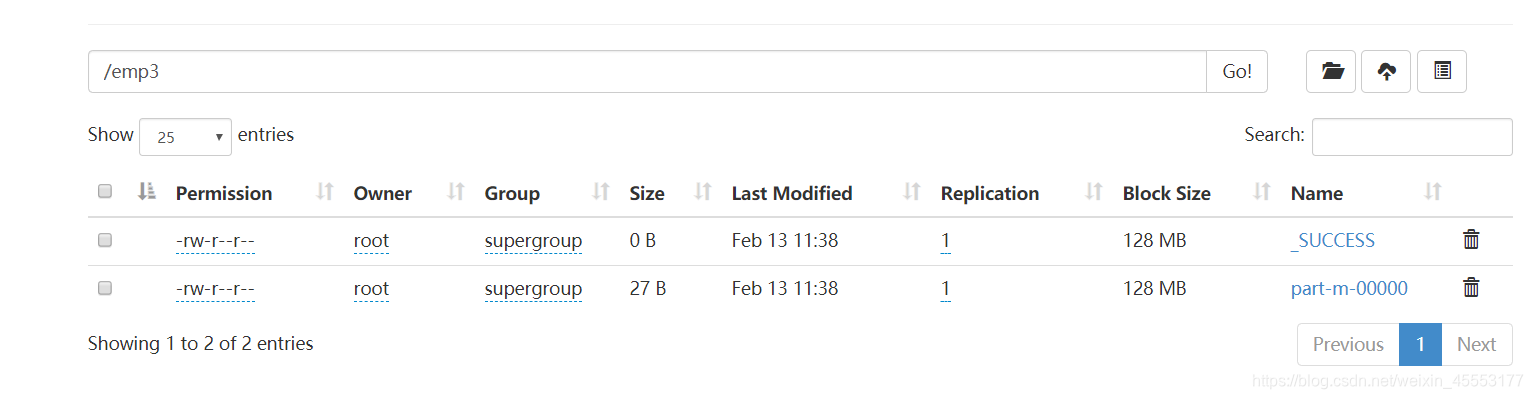
查询
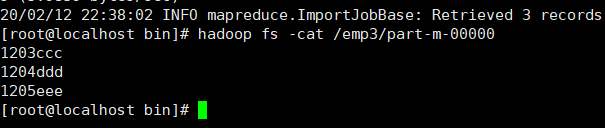
hadoop fs -cat /emp3/part-m-00000
(3)导入指定列
./sqoop import \
--connect jdbc:mysql://localhost:3306/test \
--username root \
--password 123456 \
--target-dir /emp1 \
--fields-terminated-by '\001' \
--delete-target-dir \
--table emp \
--m 1 \
--columns id,name
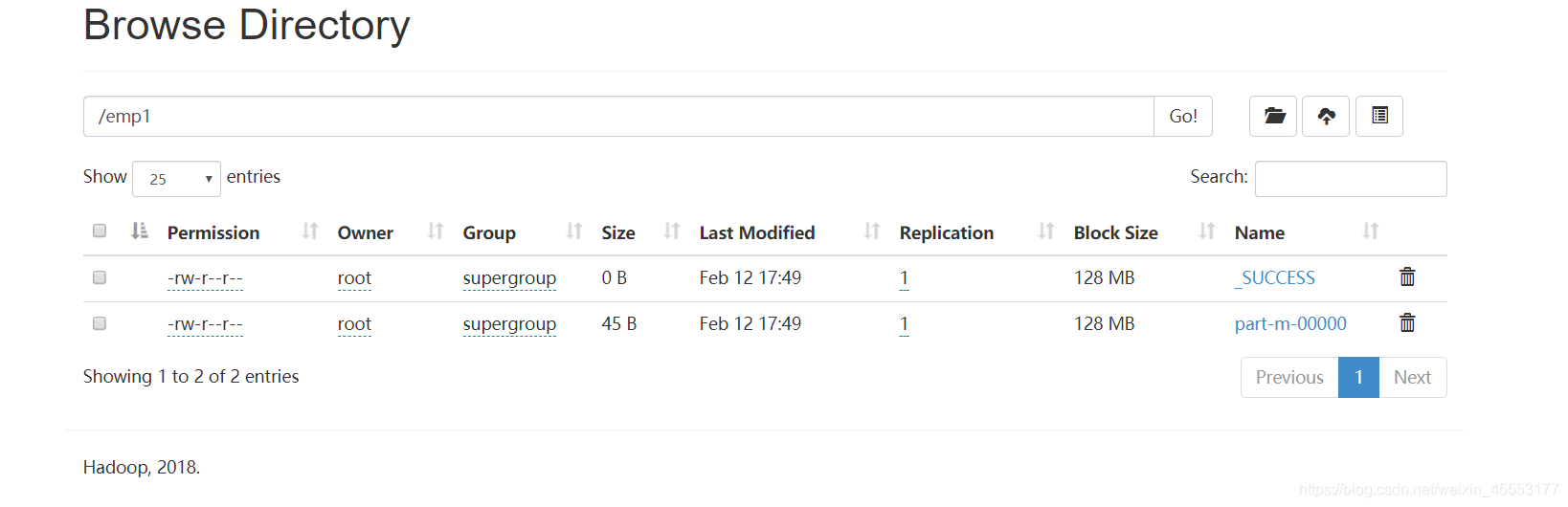
查询
hadoop fs -cat /emp1/part-m-00000
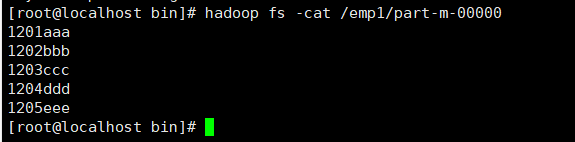 提示:columns中如果涉及到多列,用逗号分隔,分隔时不要添加空格
提示:columns中如果涉及到多列,用逗号分隔,分隔时不要添加空格
(4)使用sqoop关键字筛选查询导入数据
./sqoop import \
--connect jdbc:mysql://localhost:3306/test \
--username root \
--password 123456 \
--target-dir /emp2 \
--fields-terminated-by '\001' \
--delete-target-dir \
--table emp \
--m 1 \
--where "id = 1203"
 查询
查询
hadoop fs -cat /emp2/part-m-00000
 4.2、导出数据
4.2、导出数据
在Sqoop中,“导出”概念指:从大数据集群(HDFS,HIVE,HBASE)向非大数据集群(RDBMS)中传输数据,叫做:导出,即使用export关键字。
4.2.1 HIVE/HDFS到RDBMS
./sqoop export \
--connect jdbc:mysql://localhost:3306/test \
--username root \
--password 123456 \
--table dept \
--export-dir /user/hive/warehouse/dept/dept.txt \
--m 1 \
--input-fields-terminated-by "\t"
提示:Mysql中如果表不存在,不会自动创建