写在前面:博主是一只经过实战开发历练后投身培训事业的“小山猪”,昵称取自动画片《狮子王》中的“彭彭”,总是以乐观、积极的心态对待周边的事物。本人的技术路线从Java全栈工程师一路奔向大数据开发、数据挖掘领域,如今终有小成,愿将昔日所获与大家交流一二,希望对学习路上的你有所助益。同时,博主也想通过此次尝试打造一个完善的技术图书馆,任何与文章技术点有关的异常、错误、注意事项均会在末尾列出,欢迎大家通过各种方式提供素材。
- 对于文章中出现的任何错误请大家批评指出,一定及时修改。
- 有任何想要讨论和学习的问题可联系我:[email protected]。
- 发布文章的风格因专栏而异,均自成体系,不足之处请大家指正。
Sqoop的安装及使用
本文关键字:Sqoop、大数据、组件、数据导入、数据导出
文章目录
一、Sqoop简介
Sqoop 是一款用于在 Hadoop 和关系型数据库之间传输数据的工具,提供了一种快速、简便的方法来将大量数据从关系型数据库导入到 Hadoop 分布式文件系统(HDFS),或者从 Hadoop 导出到关系型数据库。
1. 软件作用
Sqoop 的全称是 SQL-to-Hadoop,是一个开源项目,主要用于大数据处理领域。它可以在 Hadoop 和关系型数据库之间实现数据的双向传输,例如从MySQL、Oracle 等关系型数据库中将数据导入HDFS,或从HDFS 中导出数据到关系型数据库。Sqoop 支持多种数据源,同时提供了丰富的数据导入导出选项,同时还对Hive、HBase等常用大数据组件提供支持。
2. 软件特点
- 支持多种数据源,例如 MySQL、Oracle、SQL Server、PostgreSQL 等;
- 通过命令行进行数据导入导出,无需编写复杂的代码;
- 支持增量导入,只需要导入更新的数据;
- 支持数据压缩,节省存储空间;
- 支持导入导出过程中的数据转换。
3. 生命周期
虽然Sqoop已经在2021年6月退休进入Attic,但是目前的使用程度还是比较高。支持同类型功能的软件有NiFi、Flink、Spark、Talend、StreamSets等,如果有需要会再给大家介绍。

二、Sqoop安装
1. 版本选择
Sqoop提供两个主要版本:
- 1.4.x:可以用于生产环境,最后的版本是1.4.7
- 1.9.77:Sqoop2并不与1.4.x版本兼容,不适用于生产环境
2. 软件下载
3. 安装配置
- 前置环境
Sqoop基于Java编写,运行需要JDK环境。
- 其它组件
Sqoop支持多种数据源导入导出操作,本文以MySQL、HDFS、Hive为例,需要先部署好相关的环境,如果需要可以参考:
Ubuntu安装MySQL 8.0 - APT(结尾附视频)
Hadoop 3.x各模式部署 - Ubuntu
Hive 3.x的安装部署 - Ubuntu
- 解压安装
tar -zvxf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
- 环境变量配置
编辑用户环境变量文件 .bashrc【以Ubuntu系统为例】。
export SQOOP_HOME=/home/hadoop/sqoop-1.4.7.bin__hadoop-2.6.0
export PATH=$PATH:$SQOOP_HOME/bin
export HIVE_CONF_DIR=$HIVE_HOME/conf
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HIVE_HOME/lib/*
在涉及到和Hive相关的操作时,需要让Sqoop可以读取到Hive的配置文件所在位置。需要让HIVE_CONF_DIR指向Hive的配置文件所在路径,并且在HADOOP_CLASSPATH中追加Hive的lib目录,配置完成后刷新环境变量。
- 软件配置
重命名 $SQOOP_HOME/conf/sqoop-env-template.sh为sqoop-env.sh:
mv sqoop-env-template.sh sqoop-env.sh
在其中补全环境配置信息以支持HDFS和Hive,还可以添加对HBase和Zookeper的配置【去掉最前面的#】:
export HADOOP_COMMON_HOME=/path/to/hadoop_home
export HADOOP_MAPRED_HOME=/path/to/hadoop_home
export HIVE_HOME=/path/to/hive_home
可选:注释$SQOOP_HOME/bin/configure-sqoop的135-147行,可以减少一些输出信息

三、数据导入与导出
数据导入一般指的是将数据导入到大数据环境,这里以关系型数据库作为数据源进行演示。在导入过程中,由于底层使用JDBC实现,所以在使用之前需要将连接数据库所需的驱动jar包放在Sqoop的lib目录下。
数据导出一般指将统计结果或计算任务结果导出至业务系统,用以展示或支撑其它业务逻辑。在导出过程中,目标一般为关系型数据库,同样需要准备好驱动jar包。
0. 环境准备
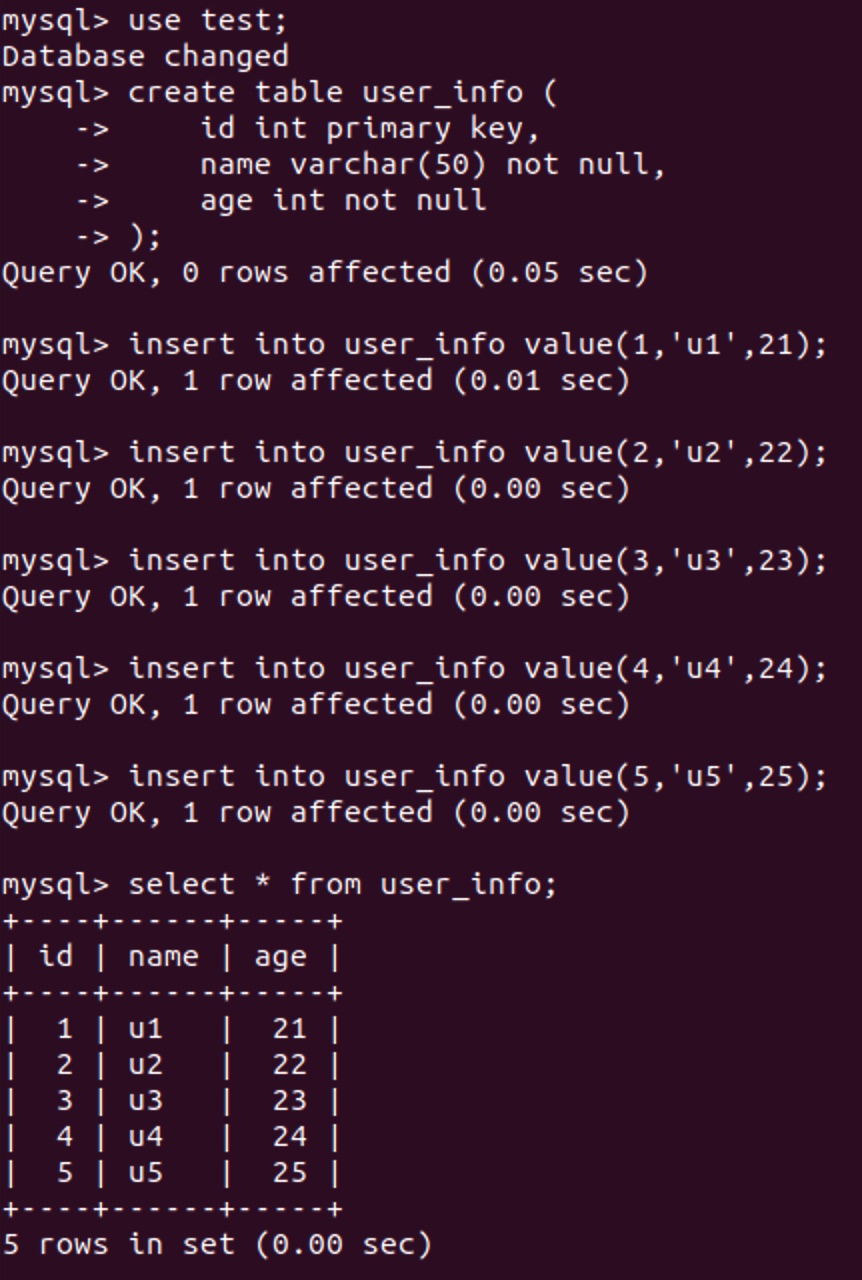
以MySQL数据库为例,先准备一个测试数据表,放在test数据库中,插入一些样例数据。
use test;
create table user_info (
id int primary key,
name varchar(50) not null,
age int not null
);
insert into user_info value(1,'u1',21);
insert into user_info value(2,'u2',22);
insert into user_info value(3,'u3',23);
insert into user_info value(4,'u4',24);
insert into user_info value(5,'u5',25);
1. 导入至HDFS
将数据以文件形式存储在HDFS中,主要会使用到连接数据源的相关参数【即连接字符串、用户名、密码】,以及数据读取目标【数据表名称】,数据输出存储位置。
sqoop import \
--connect jdbc:mysql://localhost:3306/test \
--username root \
--password root \
--table user_info \
--columns "id,name,age" \
--target-dir /user/hadoop/user_info \
--m 1
- 使用斜杠换行:通常sqoop的指令会比较长,可以使用空格将各参数隔开,也可以使用斜杠进行换行
- 整表导入:如果希望将数据全部导入至HDFS【不进行任何筛选】则只需要指定表名称即可
- 固定列导入:如果只希望导入某些列,则可以使用columns参数进行指定
- 输出路径:输出目录的最后一级目录不应该存在,执行时会自动创建
- 任务数量:Sqoop执行任务时会进行分布式处理,如果不特意指定,并发执行Map任务数量为4


2. 导入至Hive
如果希望将数据导入至Hive并继续进行HQL操作,可以方便的通过添加一些参数实现:
sqoop import \
--connect jdbc:mysql://localhost:3306/test \
--username root \
--password root \
--table user_info \
--columns "id,name,age" \
--hive-import \
--hive-database test \
--hive-table user_info \
--hive-overwrite \
--delete-target-dir \
--m 1
- 导入到Hive:使用hive-import声明这是一个导入Hive的操作
- 指定目标数据库:可以合并到hive-table中,如test.user_info
- 指定目标数据表:导入时会根据数据源结构自动建表
- 覆盖导入:如果指定则会覆盖之前的数据,不指定默认为追加导入
- 清空目标路径:执行过程中会在HDFS当前用户文件夹下写入临时文件,添加该参数可以先清空该目录,避免任务失败时需要手动清空
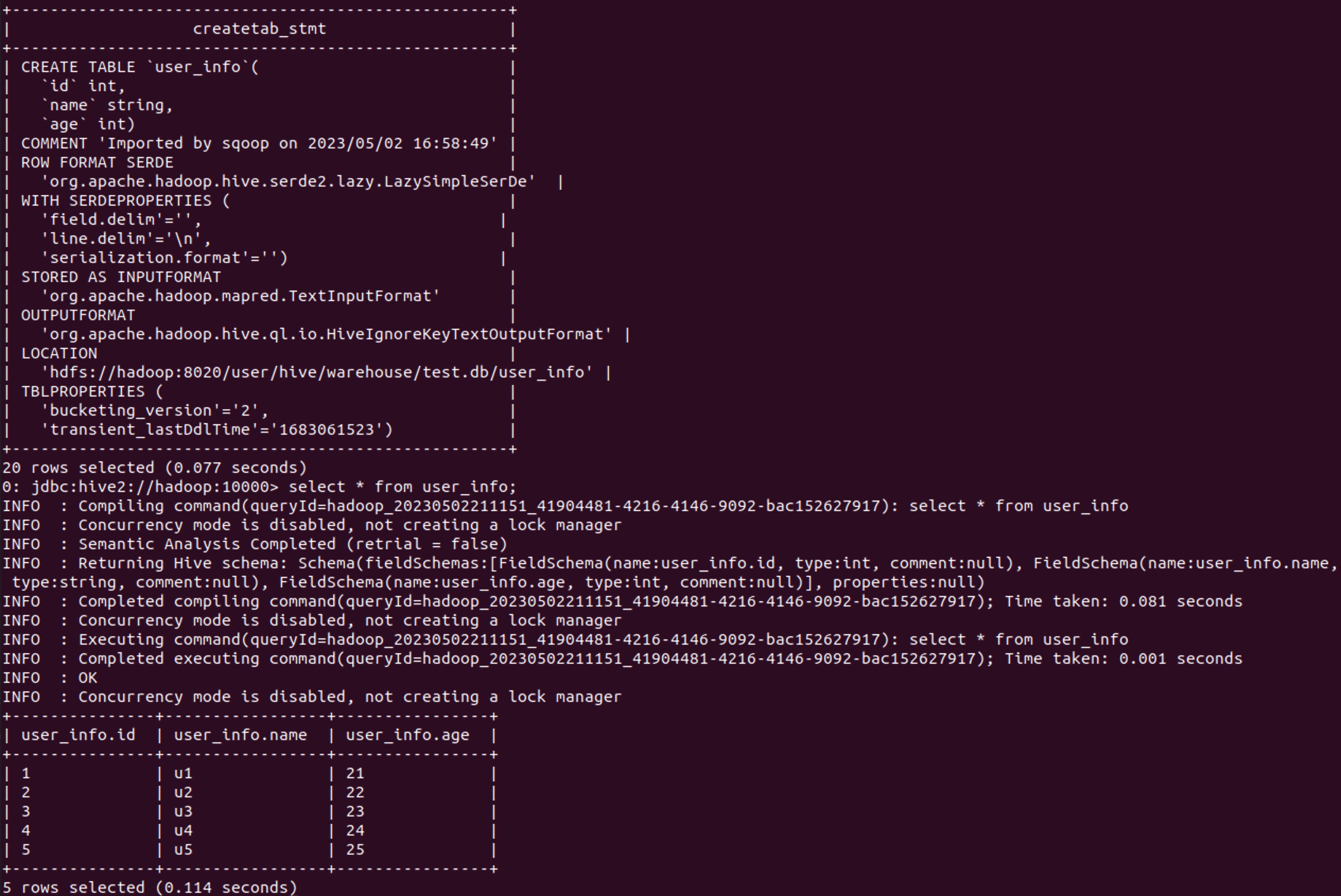
从建表语句中可以看到,该表是在Sqoop导入过程中自动创建的,会自动使用匹配的数据结构,也可以先手动在Hive中建表再进行时数据导入。
3. 从HDFS导出
如果需要将数据导出到关系型数据库,则需要先准备好一张表,如下:
create table user_info_hdfs (
id int primary key,
name varchar(50) not null,
age int not null
);
确保数据能够满足数据表的约束条件,使用如下命令:
sqoop export \
--connect jdbc:mysql://localhost/test \
--username root \
--password root \
--table user_info_hdfs \
--export-dir /user/hadoop/user_info \
--input-fields-terminated-by ',' \
--m 1
- 数据导出:使用export表示这是一个导出任务
- 导出目标:此时的table指的是目标关系型数据库的表名称
- 数据源目录:使用export-dir指定HDFS上数据文件所在位置【会导入文件夹下的所有数据】
- 数据分隔符:需要正确指定列与列之间的分隔符,才能把数据正确的安放在对应位置上

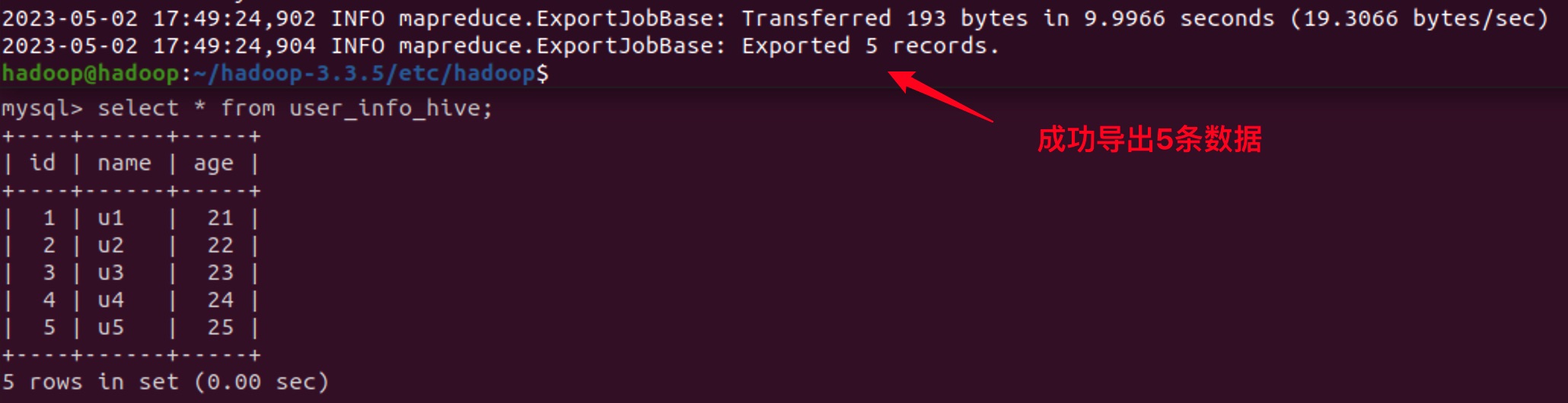
4. 从Hive导出
在数据库中创建一个用于接收Hive导出数据的表:
create table user_info_hive (
id int primary key,
name varchar(50) not null,
age int not null
);
确保数据能够满足数据表的约束条件,使用如下命令:
sqoop export \
--connect jdbc:mysql://localhost/test \
--username root \
--password root \
--table user_info_hive \
--export-dir /user/hive/warehouse/test.db/user_info \
--input-fields-terminated-by "$(echo -e '\u0001')" \
--m 1
- 数据文件目录:从Hive导出数据时,同样需要指定数据文件所在路径。默认情况下Hive的家目录为 /user/hive/warehouse,即Hive的default数据库所在路径。其余所有的数据库将以数据库名称.db的文件夹存在,数据表将以表名称命名的文件夹存放在对应数据库下。也可以通过在Hive中使用 show create table {tableName} 查看到路径信息。
- 数据分隔符:在进行数据导入导出时,应该尤为注意的就是数据分隔符问题,这将直接影响到数据是否能够正常解析或任务能够成功执行。默认情况下,如果使用Hive或者Sqoop自动建表并且不手动指定分隔符,则列分隔符为 \u0001,行分隔符为 \n。通常情况下建议自己指定列分隔符【Hive建表或数据导入时】,否则需要使用如上命令才能正确指定ASCII码值为1的字符。
5. 安全策略问题
在执行与Hive相关的任务时会出现以下错误【AccessControlException】:

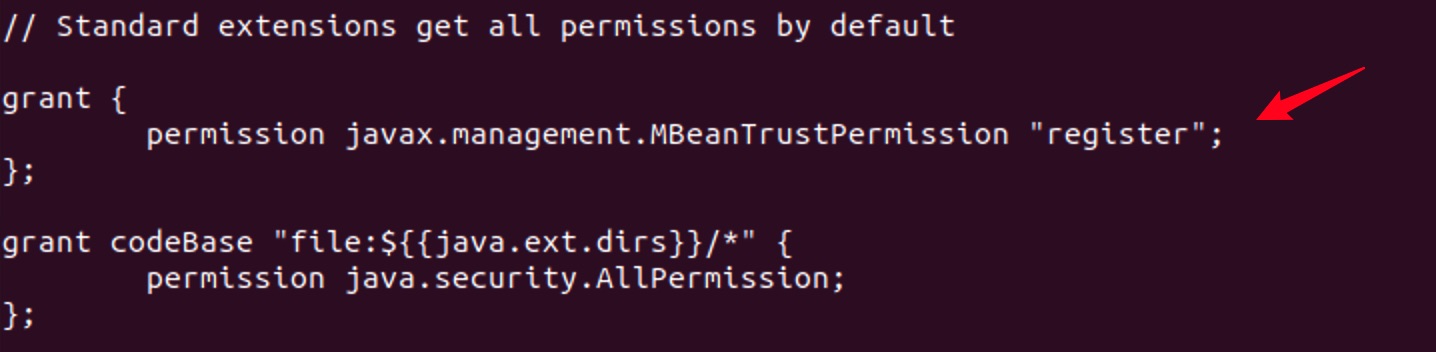
这一错误不会影响程序的运行,如果需要处理则在Java的安全策略中增加一条规则即可。
# 进入到jre的安全策略文件夹
cd /usr/lib/jvm/java-8-openjdk-arm64/jre/lib/security
# 编辑安全策略文件
sudo vi java.policy
在文件中添加以下内容后保存退出:
grant {
permission javax.management.MBeanTrustPermission "register";
};
扫描下方二维码,加入CSDN官方粉丝微信群,可以与我直接交流,还有更多福利哦~
