一.Sqoop概述
Apache Sqoop(SQL-to-Hadoop)项目旨在协助RDBMS与Hadoop之间进行高效的大数据交流。用户可以在 Sqoop 的帮助下,轻松地把关系型数据库的数据导入到 Hadoop 与其相关的系统 (如HBase和Hive)中;同时也可以把数据从 Hadoop 系统里抽取并导出到关系型数据库里。
Sqoop是一个在结构化数据和Hadoop之间进行批量数据迁移的工具,结构化数据可以是MySQL、Oracle等RDBMS。Sqoop底层用MapReduce程序实现抽取、转换、加载,MapReduce天生的特性保证了并行化和高容错率,而且相比Kettle等传统ETL工具,任务跑在Hadoop集群上,减少了ETL服务器资源的使用情况。在特定场景下,抽取过程会有很大的性能提升。
如果要用Sqoop,必须正确安装并配置Hadoop,因依赖于本地的Hadoop环境启动MR程序;MySQL、Oracle等数据库的JDBC驱动也要放到Sqoop的lib目录下。
Sqoop架构图:
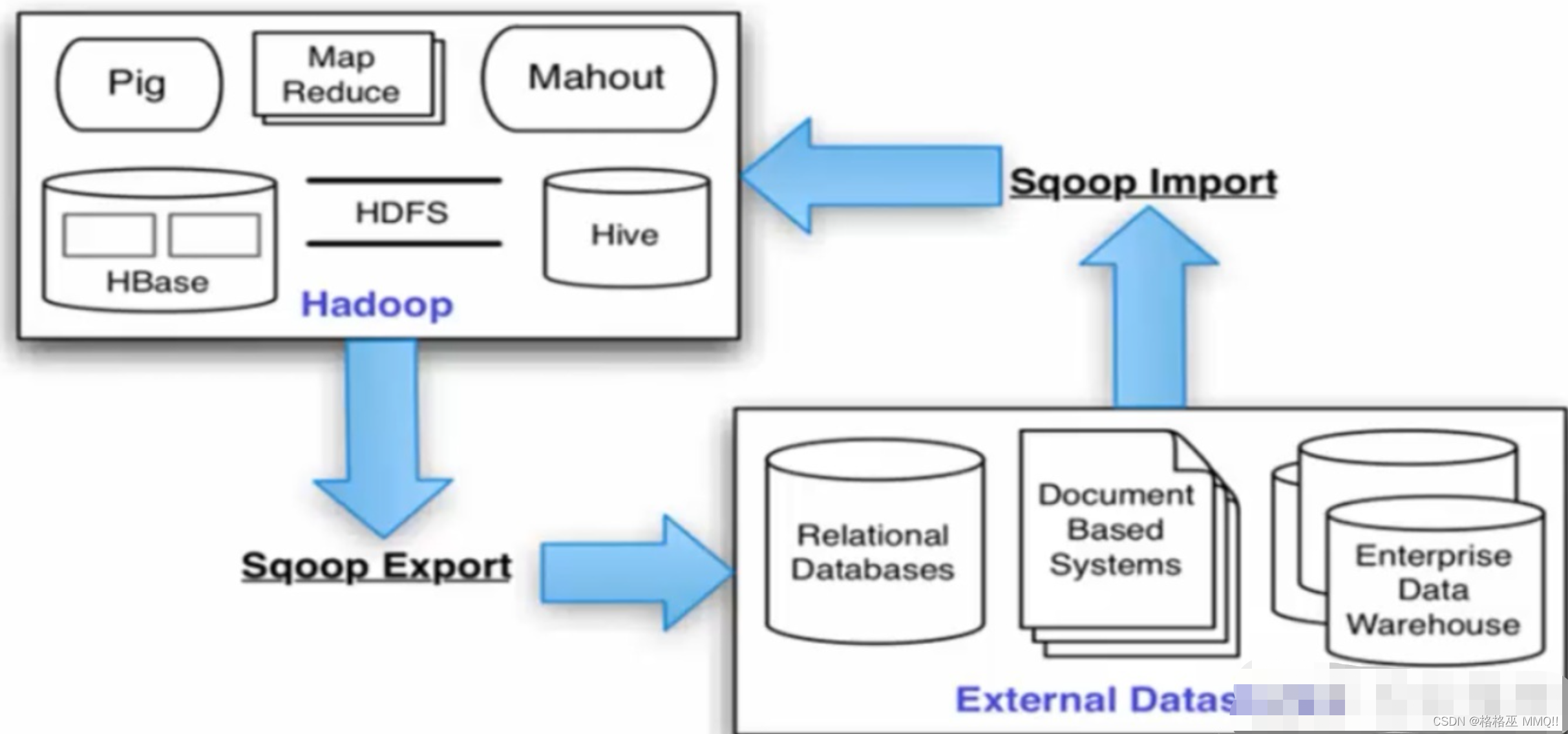
二.Sqoop 工具概述
通过Sqoop的help命令可以看到sqoop有哪些工具
[root@hp2 ~]# sqoop help
Warning: /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/bin/…/lib/sqoop/…/accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to