leecode 5 最长回文子串
给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为 1000。
示例 1:
输入: "babad"
输出: "bab"
注意: "aba" 也是一个有效答案。
示例 2:输入: "cbbd"
输出: "bb"来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/longest-palindromic-substring
解法
- 暴力求解法,,直接嵌套3层循环,这个算法由于太过暴力,这里不讲,需要知道的是其时间复杂度到了O(n^3)
- 中心扩展法
- 从左右到右,以每一个下标为中点进行查找,判断是否能构成最长回文串,
- 算法注意:奇偶需要区分,例如bb其中心为下标0,1之间
- 其时间复杂度为O(n^2)
- manacher(马拉车)算法,其时间复杂度可达到仅为O(n)
manacher 算法是本文的重点,其可在O(n)的时间内找到以所有下标为中点的回文串长度。
马拉车算法
mx:最长回文串的右边界
mid:最长回文串的中心
len[i]:以下标i为中心的回文串长度
j:i以mid为中点的对称下标

算法思想:
- 从左到右计算以i为中心的最长回文串长度
- 首先判断mx-i是否小于len[j],是的话,le[i]=len[j],否则说明mid被包含在len[j]的半径之中,无法直接通过mid映射求出len[i]的长度,需要以i为中心一步一步进行中心扩展求出len[i],具体分析见后文
- 如果i+len[i]>mx(上一个最长回文串长度),说明现在的最长回文串长度右边界值已经发生了更改,需要更改回文串中心mid以及右边界right
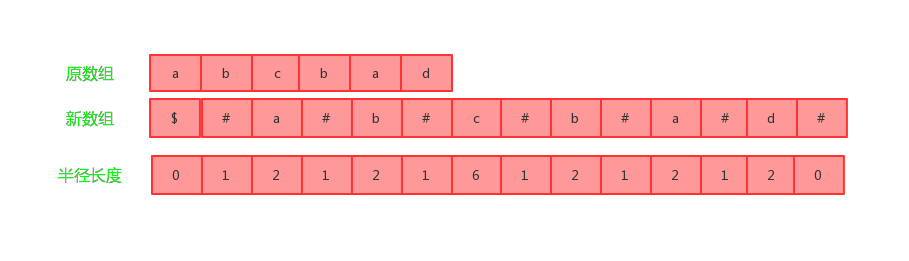
这是一个经典、充满趣味的算法,从前文我们知道了,奇回文串跟偶回文串需要区分对待,马拉车算法会构造一个新的字符串,该字符串在原字符串的每个元素之间加入了 '#',并且将下标为0的元素(即第一个字符)设置成'$',设置边界。现在假设Len[i]为以第i个元素为轴心的回文串半径长度(注意是半径)。那么原数组"abcbad"就变成"$#a#b#c#b#a#d#",通过计算其每个元素最长回文串的半径长度,可以得出Len数组,可以知道最大的Len[i]-1就是原数组的最大长度。
![]()
知道最大长度就是max(Len[i])-1后,那么问题就转换成求Len数组的值。马拉车算法用到了一个非常巧妙的方法去求解Len数组的值。
首先从左往右依次计算Len[i],j为i关于mid的对称点,当计算Len[i]时,Lenj已经计算完毕。设right为之前计算中最长回文子串的右端点的最大值,并且设取得这个最大值的中心位置为mid,分两种情况考虑:
第一种情况:i<=mx
-
如果出现Len[j]<mx-i,那么i的半径长度就为Len[j]:
由回文串的对称性可知,Len[i]>=Len[j]。Len[i]>Len[i]的情况当且仅当i的右边回文串长度超过了mx,此时由对程序可知以i为中心的回文串左边的长度应该往左伸展,越过mid。
因为Len[j]<mx-i,说明Len[j]完全包含于mid的左半径中,即存在x于y不对称,其中x字符串的长度为 mx-i-len[j] 。对于i来说,只有存在y与x对称,并且存在超过mx的部分与i左边字串对称才有Len[i]>Len[i],其余情况都是Len[i]=Len[j],所以在这种情况下,Len[i]=Len[j].

![]()
第二种情况 :i>mx
此时不在回文串内,无法利用镜像减少步长,必须从半径1开始扩展。
-
如果出现len[j]>mx-i
如果Len[j]>=P-i,由对称性,说明以i为中心的回文串可能会延伸到P之外,而大于P的部分我们还没有进行匹配,所以要从P+1位置开始一个一个进行匹配,直到发生失配,从而更新P和对应的po以及Len[i]。


最大长度的推理
假设现在Len数组中,最大的值为Len[i],那么,新数组中,回文串总长度为2Len[i]-1(因为加上'#'后都变成奇数回文串),其中,2Len[i]-1中,有一半是'#',所以'#'的长度为Len[i],所以剩下的回文串长度为Len[i]-1。
精妙之处
-
通过添加字符'#'来规避处理奇偶回文串的麻烦,同时通过'$'作为边界,可以轻松检测边界。
-
通过镜像对称,减少步长。
string longestPalindrome(string s) { string str(s.size() * 2 + 2,'#'); for (int i = 0, j = 2; i < s.size(); ++i, j += 2) str[j] = s[i]; str[0] = '$'; cout << str<<endl; int strLen = str.size(), right = 0, maxIndex = 0; vector<int> palindromeLen(strLen, 0); for (int i = 1, mid = 0; i < strLen; ++i) { //如果不超过当前最长字符串的右边界 //则需要判断其对称位置的长度是否大于right-i,是的话说明会超过边界,有更长的回文串 if (i < right) palindromeLen[i] = min(right - i, palindromeLen[mid * 2 - i]); else palindromeLen[i] = 1; //再做一次线性查找 while (str[i + palindromeLen[i]] == str[i - palindromeLen[i]]) { palindromeLen[i]++; } //说明现在的最长字符串已经更替,需要重新更新有边界 if (i + palindromeLen[i] > right) { mid = i; right = i + palindromeLen[i]; } if(palindromeLen[i] > palindromeLen[maxIndex]) maxIndex = i; //cout << " i: " << i << " palindromeLen[i]: " << palindromeLen[i] <<" mid: "<<mid<< " right: " << right<<endl; } return s.substr((maxIndex- palindromeLen[maxIndex]) /2, palindromeLen[maxIndex] - 1); }
647 给定一个字符串,你的任务是计算这个字符串中有多少个回文子串。
具有不同开始位置或结束位置的子串,即使是由相同的字符组成,也会被计为是不同的子串。
示例 1:
输入: "abc"
输出: 3
解释: 三个回文子串: "a", "b", "c".
示例 2:输入: "aaa"
输出: 6
说明: 6个回文子串: "a", "a", "a", "aa", "aa", "aaa".来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/palindromic-substrings
解法:
与前文求最长回文串类似,只要熟悉马拉车算法,然后通过马拉车算法求出所有下标的最长回文串长度,除以2再相加就得到我们要的结果
这里有俩个容易出错的点
1.返回的时候应该选择哪些下标的回文串长度进行相加
例如:"aba",变成马拉车之后,字符串变为"$#a#b#a#",其回文串长度数组为 [0,1,2,1,3,1,2,1],如果你像我一样天真地以为把原本aba对应的下标的回文串长度-1燃火相加就ok,那你就大错特错啦,”aba“确实可以这样子做,只相加(2-1)+(3-1)+(2-1),但是这只是个例,如果出现"ccc"这样子的字符串,结果应该是6个回文子串({"c","c","c","cc","cc","ccc"}),其回文字符串为"$#c#c#c#",对应的数组长度为[0,1,2,3,4,3,2,1],如果按照上文的计算方法吗,则为(2-1)+(4-1)+(2-1)=5,少计算了一个,看到没,这就是问题的所在,以3个字符的字符串为例,直接算对应下标半径长度的话,存在重复的回文串与不存在重复字符的回文串的计算方法不同,因此应该要把所有的回文串半径长度先除以2再相加,就可得到正确的回文串长度。
2.设置好起始位置符号$与终止符号#
有个这俩个符号,在比较的时候不用做下标越界处理,方便很多
vector<int> manacher(const string& s) { string str(s.size() * 2 + 2, '#'); for (int i = 0, j = 2; i < s.size(); ++i, j += 2) str[j] = s[i]; str[0] = '$'; cout << str << endl; int right = 0; vector<int> len(str.size()); for (int i = 1, mid = 0; i < str.size(); ++i) { if (i < right) len[i] = min(right - i, len[mid * 2 - i]); else len[i] = 1; while (str[i + len[i]] == str[i - len[i]]) len[i]++; if (i >= right) { mid = i; right = i + len[i]; } } return len; } int countSubstrings(string s) { int sum = 0; if (s.size() <= 0) return sum; vector<int> len(manacher(s)); for (int i = 1; i < len.size(); ++i) { //cout << (len[i]) << endl; sum += (len[i])/2; } return sum; } void countSubstringsTest() { int a=countSubstrings("aaccc"); cout << "结果是: " << a << endl; }