微服务架构下的问题
在大型系统的微服务化构建中,一个系统会被拆分成许多模块。这些模块负责不同的功能,组合成系
统,最终可以提供丰富的功能。在这种架构中,一次请求往往需要涉及到多个服务。互联网应用构建在
不同的软件模块集上,这些软件模块,有可能是由不同的团队开发、可能使用不同的编程语言来实现、
有可能布在了几千台服务器,横跨多个不同的数据中心,也就意味着这种架构形式也会存在一些问题:
- 如何快速发现问题?
- 如何判断故障影响范围?
- 如何梳理服务依赖以及依赖的合理性?
- 如何分析链路性能问题以及实时容量规划?
分布式链路追踪(Distributed Tracing),就是将一次分布式请求还原成调用链路,进行日志记录,性
能监控并将 一次分布式请求的调用情况集中展示。比如各个服务节点上的耗时、请求具体到达哪台机器
上、每个服务节点的请求状态等等。
目前业界比较流行的链路追踪系统如:Twitter的Zipkin,阿里的鹰眼,美团的Mtrace,大众点评的
cat等,大部分都是基于google发表的 Dapper。Dapper阐述了分布式系统,特别是微服务架构中链路
追踪的概念、数据表示、埋点、传递、收集、存储与展示等技术细节。
Sleuth概述
简介
Spring Cloud Sleuth 主要功能就是在分布式系统中提供追踪解决方案,并且兼容支持了 zipkin,你只
需要在pom文件中引入相应的依赖即可。
相关概念
Spring Cloud Sleuth 为Spring Cloud提供了分布式根据的解决方案。它大量借用了Google Dapper的
设计。先来了解一下Sleuth中的术语和相关概念。
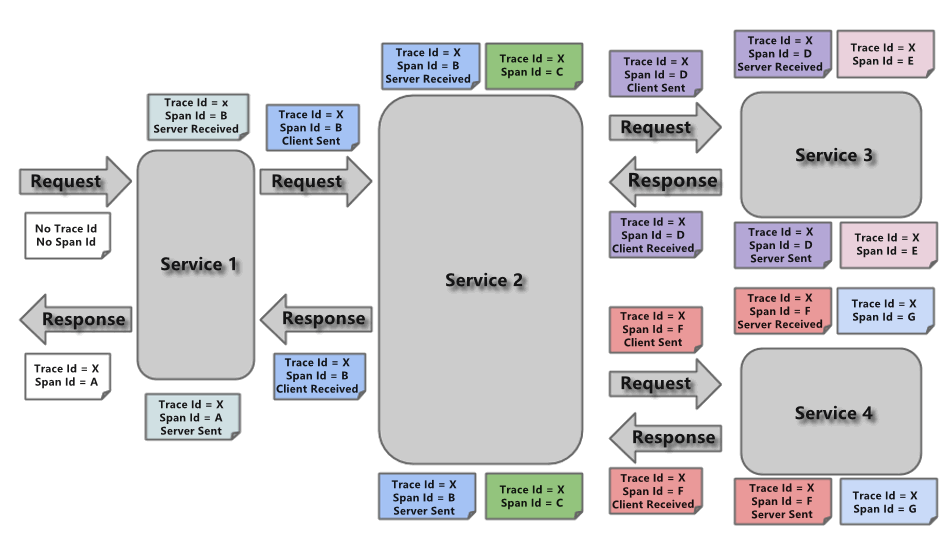
Spring Cloud Sleuth采用的是Google的开源项目Dapper的专业术语。
Span :基本工作单元,例如,在一个新建的span中发送一个RPC等同于发送一个回应请求给
RPC,span通过一个64位ID唯一标识,trace以另一个64位ID表示,span还有其他数据信息,比
如摘要、时间戳事件、关键值注释(tags)、span的ID、以及进度ID(通常是IP地址)
span在不断的启动和停止,同时记录了时间信息,当你创建了一个span,你必须在未来的某个时刻停止它。
Trace :一系列spans组成的一个树状结构,例如,如果你正在跑一个分布式大数据工程,你可能
需要创建一个trace。
Annotation :用来及时记录一个事件的存在,一些核心annotations用来定义一个请求的开始和结束
cs - Client Sent - 客户端发起一个请求,这个annotion描述了这个span的开始
sr - Server Received - 服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳便可得到
网络延迟
ss - Server Sent - 注解表明请求处理的完成(当请求返回客户端),如果ss减去sr时间戳便可得
到服务端需要的处理请求时间
cr - Client Received - 表明span的结束,客户端成功接收到服务端的回复,如果cr减去cs时间
戳便可得到客户端从服务端获取回复的所有所需时间。
链路追踪Sleuth入门
接下来通过之前的项目案例整合Sleuth,完成入门案例的编写
(1) 配置依赖
修改微服务工程引入Sleuth依赖
<!--sleuth链路追踪--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency>
2) 修改配置文件
修改application.yml添加日志级别
logging:
level:
root: info
org.springframework.web.servlet.DispatcherServlet: DEBUG
org.springframework.cloud.sleuth: DEBUG
然后开始调用
网关服务日志
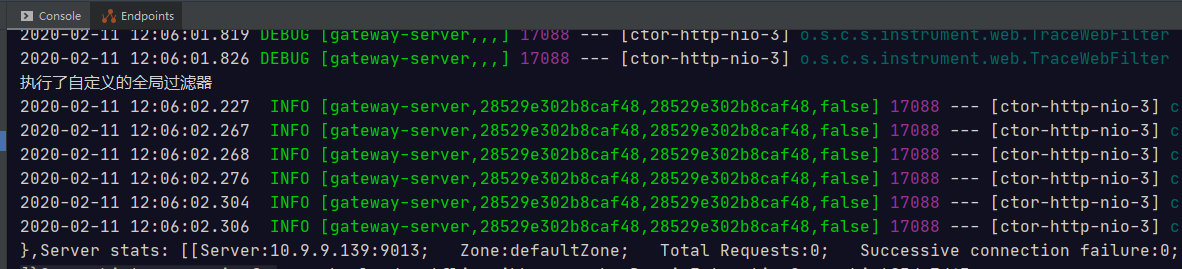
订单服务日志
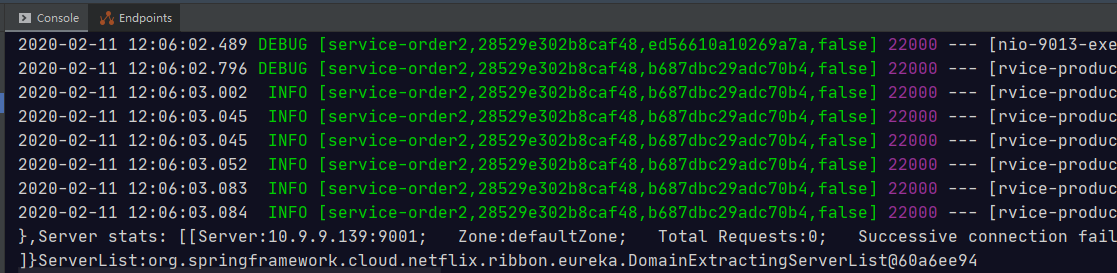
商品服务日志
