
前言
在我们越来越庞大的微服务群中,随着业务的不断扩展,微服务的个数也越来越多, 微服务的架构体系,服务拆分导致系统调用链路也在不断的复杂化,一个稍微复杂的前端请求可能最终需要调用很多次后端服务才能完成,一个后端的服务,可能通过多次的Feign调用才能实现;当我们的请求出现故障或者是性能降低时,我们分析到最后的根本致错的微服务也带来了很大的困难,分布式系统的链路追踪便是用来挑战这个困难的,今天我们介绍的Sleuth+Zipkin,就是用来对SpringCloude的微服务云体系里的服务定位和追踪的解决方案。

Http跟踪
为了实现请求链路跟踪,当请求发送到分布式系统的入口时,只需要在服务跟踪框架为该请求创建唯一的跟踪标识,并保证该标识在在分布式系统内部流转,直到返回请求为止。该标识即为 traceId,通过该标识,就能将不同服务调用的日志串联起来。简而言之,在整个Http的调用中(FeignClient或者RestTemplate)中,我们可以标识一个TraceId的记录,在Http的Request过程中,将TraceID传递到提供服务的服务端,提供服务的服务端在Reuqest中获取TraceId,同样的方式,将整个TraceId传递到他的服务提供方,这样在整个至上而下的调用链路中,都具有相同的TraceId,通过TraceId把各个链路中的服务的日志归组合并,这样就得到了一条条不同TraceId的调用链路, 这也就是链路追踪的主要原理, 链路追踪还有另一个国内的产品Skywalking, 也已经成为了Apache里的顶级开源项目,虽然在具体的实现上和Sleuth有差异,但是使用的原理是一样的。
MDC(Mapped Diagnostic Contexts)
通过上面的方式,我们就有了实现链路追踪的实现方式了, MDC((Mapped Diagnostic Contexts))翻译过来就是映射的诊断上下文 。意思是:在日志中 (映射的) 请求ID(requestId),可以作为我们定位 (诊断) 问题的关键字 (上下文)。这并不是一个新鲜的产物,MDC类基本原理其实非常简单,其内部持有一个ThreadLocal实例,用于保存context数据,MDC提供了put/get/clear等几个核心接口,用于操作ThreadLocal中的数据;ThreadLocal中的K-V,可以在logback.xml中声明,即在layout中通过声明 %X{Key} 来打印MDC中保存的此key对应的value在日志中。具体有关MDC的东西可以单独去百度有关MDC的文章,Http的链路追踪traceId这个标识,也就是通过MDC的方式来进行实现的。
Sleuth

sleuth在SpringCloud分布式系统中提供追踪解决方案,通过Sleuth可以记录下链路追踪的相关信息,并且将相关的链路调用信息发送给指定的统计端和展示端,比如Zipkin

Spring Cloud Sleuth关键词(基于 Google Dapper)
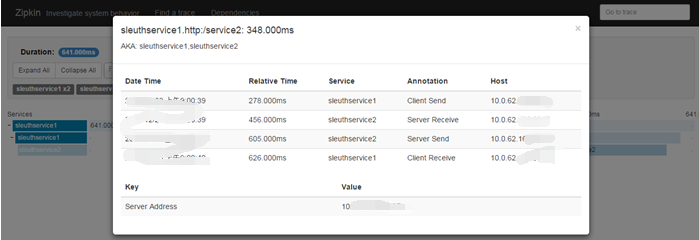
- Span:基本工作单元,发送一个远程调度任务 就会产生一个Span,Span是一个64位ID唯一标识的,Trace是用另一个64位ID唯一标识的,Span还有其他数据信息,比如摘要、时间戳事件、Span的ID、以及进度ID。
- Trace:一系列Span组成的一个树状结构。请求一个微服务系统的API接口,这个API接口,需要调用多个微服务,调用每个微服务都会产生一个新的Span,所有由这个请求产生的Span组成了这个Trace。
- Annotation:用来及时记录一个事件的,一些核心注解用来定义一个请求的开始和结束 。这些注解包括以下:
- cs - Client Sent -客户端发送一个请求,这个注解描述了这个Span的开始
- sr - Server Received -服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳便可得到网络传输的时间。
- ss - Server Sent (服务端发送响应)–该注解表明请求处理的完成(当请求返回客户端),如果ss的时间戳减去sr时间戳,就可以得到服务器请求的时间。
- cr - Client Received (客户端接收响应)-此时Span的结束,如果cr的时间戳减去cs时间戳便可以得到整个请求所消耗的时间。
Zipkin
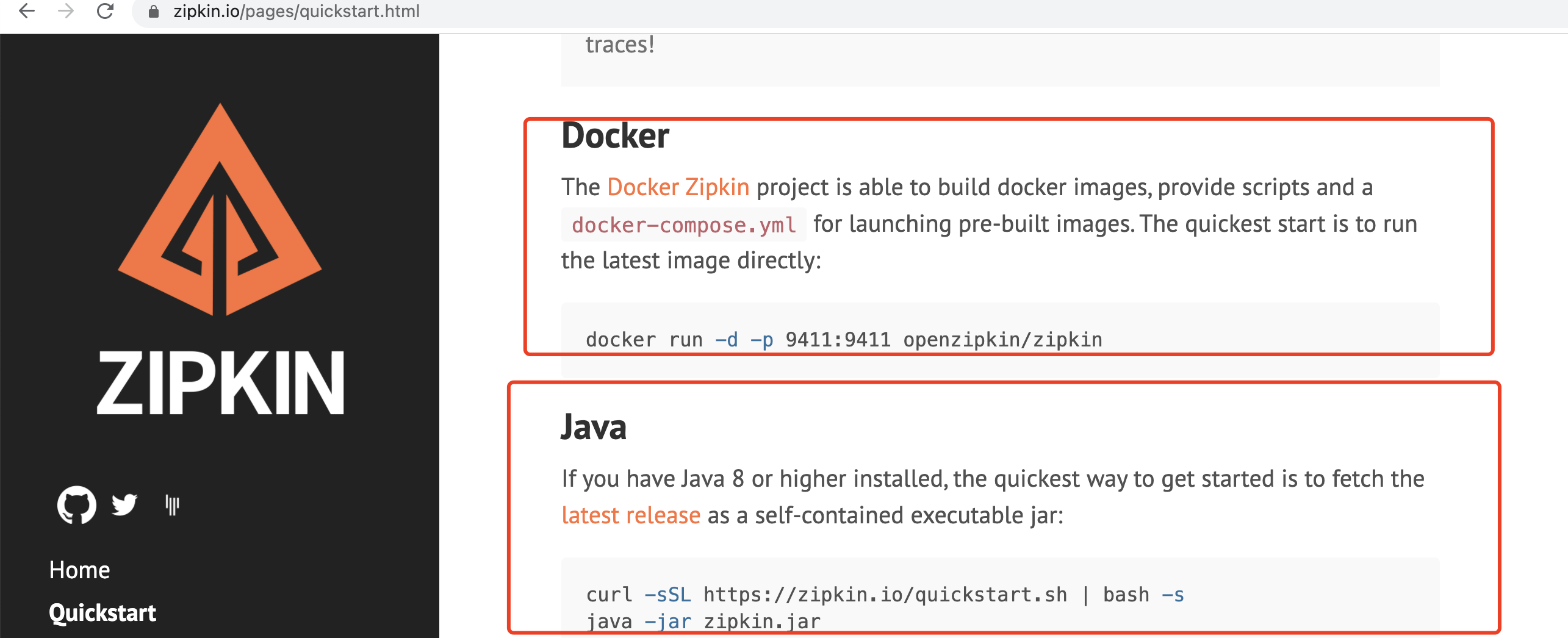
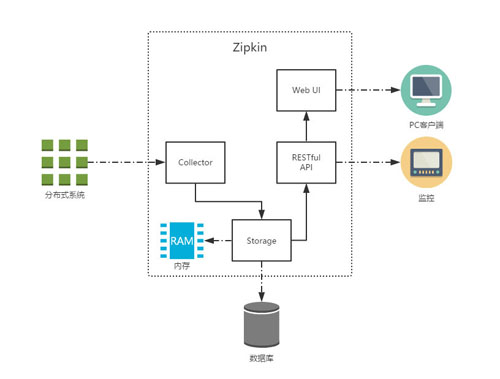
Zipkin是 Twitter 的一个开源项目,基于 Google Dapper实现。可以使用它来收集各个服务器上请求链路的跟踪数据,并通过它提供的 REST API 接口来辅助我们查询跟踪数据以实现对分布式系统的监控程序,从而及时地发现系统中出现的延迟升高问题并找出系统性能瓶颈的根源。除了面向开发的API接口之外,它也提供了方便的 UI 组件帮助我们直观的搜索跟踪信息和分析请求链路明细,比如:可以查询某段时间内各用户请求的处理时间等。
简而言之Zipkin采集 sleuth 在客户端的数据,并提供可视化界面做查询展示。
Docker启动Zipkin
docker run -d -p 9411:9411 openzipkin/zipkin
访问Zipkin的图形页面
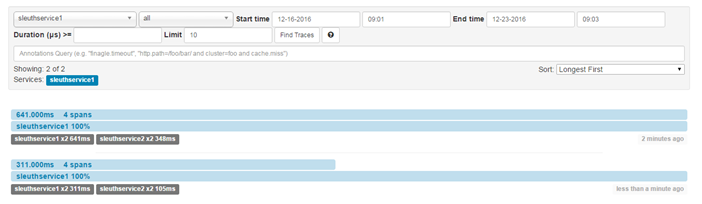
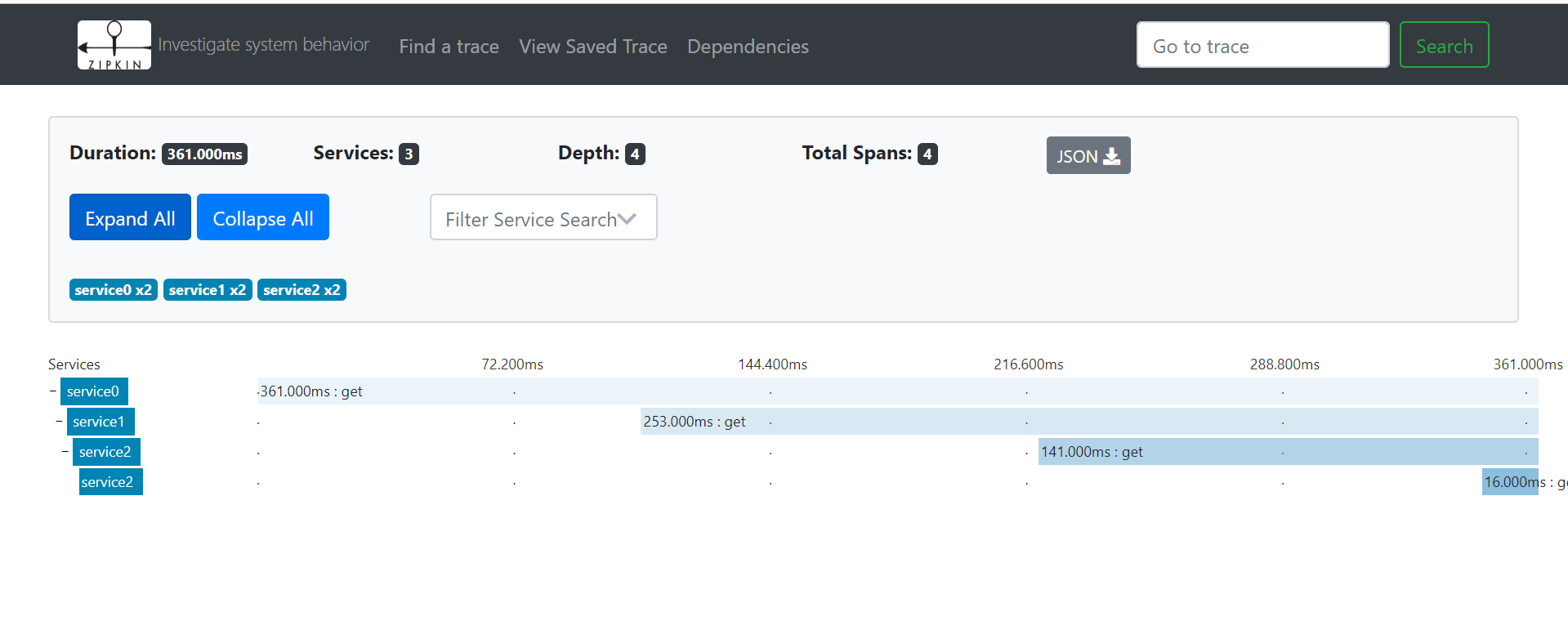
点开某一个请求后,会看到详细的调用链请求信息:

SpringCloud使用Sleuth
在SpringCloud项目中使用Sleuth进行链路追踪非常的方便,只需要在项目中映入Sleuth的Starter,如果Sleuth的采集链路追踪的信息需要Push到Zipkin的话,再引入Zipkin的Starter,并且配置上Zipkin Server的服务地址即可。
引入相关的依赖包和Start
<!-- 配置服务链路追踪 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
如上的pom.xml文件,加入了Sleuth的starter以及Zipkin的支持, 在SpringCloud的微服务的Restful的调用中FeignClient以及RestTemplate将会被Sleuth进行记录,并发送到Zipkin的服务地址。
配置Zipkin的服务地址
spring:
zipkin:
base-url: http://localhost:9411/
sender:
type: web
sleuth:
sampler:
#抽样百分比,默认10%的数据发到zipkin,1为100%
probability: 1通过以上的方式,在我们的SpringCloud的微服务云体系中,我们的每个微服务云的服务调用都将进入到调用追踪的trace范围,然后通过Zipkin提供的图形显示的工具,就可以一目了然的了解到我们的每个服务调用的链路跟踪的情况,通过链路追踪的解决方案,当整个请求变慢或不可用时,我们就可以得知该请求是由某个或某些后端服务引起的,快读定位服务故障点,并对症下药。
使用MQ来push信息
通过上面的方式,每个微服务的调用追踪都会向Zipkin Server发出Http请求,当内部网络阻塞时,可能会引起主业务调用的阻塞,从而导致更严重的后果,所以这个时候我们可以考虑通过Stream或者时MQ的方式来异步的处理Sleuth发过来的请求;
我们的SpringCloud的微服务端,只需要引入支持Stream和MQ的starter即可
<!-- 配置服务链路追踪 -->
<!-- <dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency> -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>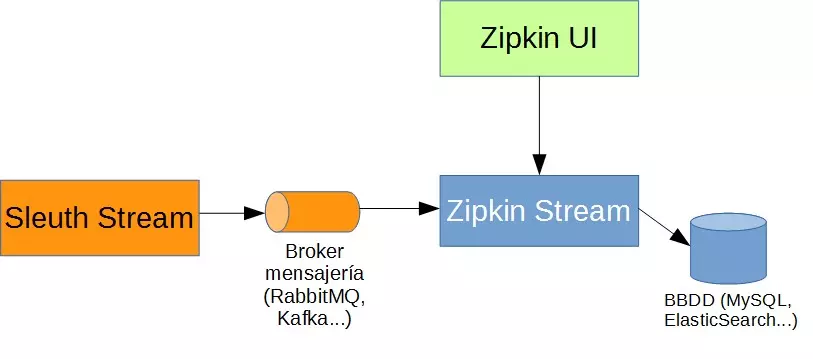
Zipkin Server的配置也相应的调整;
Zipkin高级用法持久化
Zipkin默认把Sleuth的日志信息保存在内存里,这样每次重新启动Zipkin都会丢失以前的日志信息,可以通过修改Zipkin的配置,让Zipkin Server持久化所有的日志到数据库里。关于持久化和Zipkin支持MQ的方式,我们讲在以后的文章中再进行介绍。
结束语
每个服务调用的链路跟踪的情况,通过链路追踪的解决方案,当整个请求变慢或不可用时,我们就可以得知该请求是由某个或某些后端服务引起的,快读定位服务故障点,并对症下药。本文主要介绍的是通过Sleuth+Zipking的方式实现SpringCloud的微服务云链路追踪,在文中我们提到了有关Zipkin的MQ接收sleuth日志信息,和日志信息持久化的用法,我们将在以后的文章中介绍, 有关Skywalking这个同样可以作为微服务体系中的链路追踪的解决方案,我们以后也会在专门的文章里来单独介绍Skywalking。 还望大家持续关注笔者的每个文章,关注笔者,不要错过精彩。
谢谢大家持续关注。