目录
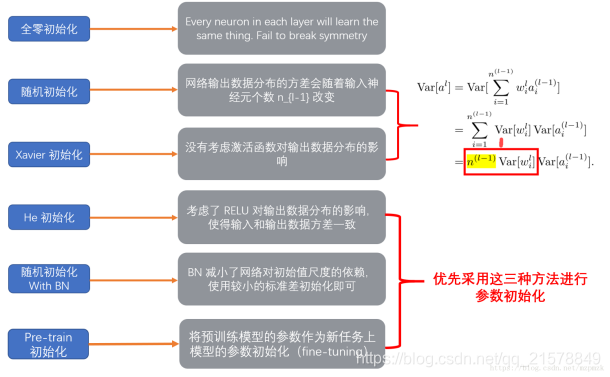
1 随机初始化
2 Xavier初始化
每层的权重初始化公式如下: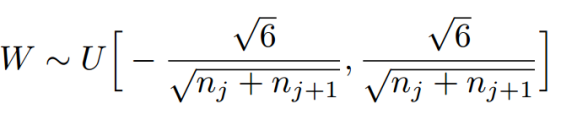
上式为一个均匀分布,n_j为输入层的参数,n_(j+1)为输出层的参数
Xavier的推导过程是基于几个假设的,
其中一个是激活函数是线性的,这并不适用于ReLU,sigmoid等非线性激活函数;
另一个是激活值关于0对称,这个不适用于sigmoid函数和ReLU函数它们不是关于0对称的。
3 He初始化
Xavier初始化没有考虑激活函数,在某些非线性激活函数上表现不好(大部分激活函数都是有效的),如Relu。因此针对Relu推导了一次,与上面过程类似,只是方差要除以2。
每层的权重初始化公式如下: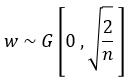
为一个均值为0方差为2/n的高斯分布。
4 高斯随机初始化 with Batch Norm
5 Pre-train
在实际训练中,我们可以选择一个backbone网络,在其基础上做改动。该网络如果有一个已经训练好的在任务A上的模型(称为pre-trained model),可以直接将其放在任务B上做模型调整(称为fine-tuning)。
