Pytorch总结八之深度学习计算(1)模型构造,参数访问、初始化和共享
0.层和块
-
之前首次介绍神经网络时,我们关注的是具有单一输出的线性模型。 在这里,整个模型只有一个输出。 注意,单个神经网络
(1)接受一些输入;
(2)生成相应的标量输出;
(3)具有一组相关 参数(parameters),更新这些参数可以优化某目标函数。 -
然后,当考虑具有多个输出的网络时, 我们利用矢量化算法来描述整层神经元。 像单个神经元一样,层(1)接受一组输入, (2)生成相应的输出, (3)由一组可调整参数描述。 当我们使用softmax回归时,一个单层本身就是模型。 然而,即使我们随后引入了多层感知机,我们仍然可以认为该模型保留了上面所说的基本架构。
-
对于多层感知机而言,整个模型及其组成层都是这种架构。 整个模型接受原始输入(特征),生成输出(预测), 并包含一些参数(所有组成层的参数集合)。 同样,每个单独的层接收输入(由前一层提供), 生成输出(到下一层的输入),并且具有一组可调参数, 这些参数根据从下一层反向传播的信号进行更新。
-
事实证明,研究讨论“比单个层大”但“比整个模型小”的组件更有价值。 例如,在计算机视觉中广泛流行的
ResNet-152架构就有数百层, 这些层是由层组(groups of layers)的重复模式组成。 这个ResNet架构赢得了2015年ImageNet和COCO计算机视觉比赛 的识别和检测任务 [He et al., 2016a]。 目前ResNet架构仍然是许多视觉任务的首选架构。 在其他的领域,如自然语言处理和语音, 层组以各种重复模式排列的类似架构现在也是普遍存在。 -
为了实现这些复杂的网络,我们引入了神经网络块的概念。 块(block)可以描述单个层、由多个层组成的组件或整个模型本身。 使用块进行抽象的一个好处是可以将一些块组合成更大的组件, 这一过程通常是递归的,如 图5.1.1所示。 通过定义代码来按需生成任意复杂度的块, 我们可以通过简洁的代码实现复杂的神经网络。
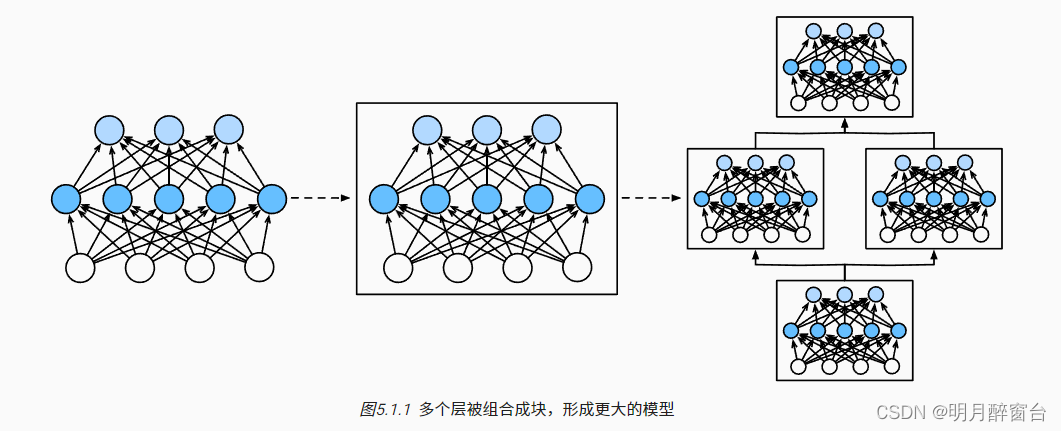
-
从编程的角度来看,块由类(class)表示。 它的任何子类都必须定义一个将其输入转换为输出的前向传播函数, 并且必须存储任何必需的参数。 注意,有些块不需要任何参数。 最后,为了计算梯度,块必须具有反向传播函数。 在定义我们自己的块时,由于自动微分提供了一些后端实现,我们只需要考虑前向传播函数和必需的参数。
在构造自定义块之前,我们先回顾一下多层感知机的代码。 下面的代码生成一个网络,其中包含一个具有256个单元和ReLU激活函数的全连接隐藏层, 然后是一个具有10个隐藏单元且不带激活函数的全连接输出层。
import torch
from torch import nn
from torch.nn import functional as F
net = nn.Sequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))
X = torch.rand(2, 20)
net(X)

简而言之,nn.Sequential定义了一种特殊的Module, 即在PyTorch中表示一个块的类, 它维护了一个由Module组成的有序列表。 注意,两
个全连接层都是Linear类的实例, Linear类本身就是Module的子类。 另外,到目前为止,我们一直在通过net(X)调用我们的模型来获得模型
的输出。 这实际上是net.__call__(X)的简写。 这个前向传播函数非常简单: 它将列表中的每个块连接在一起,将每个块的输出作为下一个
块的输入。
1.模型构造
回顾⼀下 多层感知机的简洁实现 中含单隐藏层的多层感知机的实现⽅法。我们⾸先构造
Sequential实例,然后依次添加两个全连接层。其中第⼀层的输出⼤⼩为256,即隐藏层单元个数是256;第⼆层的输出⼤⼩为10,即输出层单元个数是10。这⾥我们介绍另外⼀种基于 Module 类的模型构造⽅法:它让模型构造更加灵活。
1.1 继承 MODULE 类来构造模型
Module 类是 nn 模块⾥提供的⼀个模型构造类,是所有神经⽹络模块的基类,我们可以继承它来定义我们想要的模型。下⾯继承 Module 类构造本节开头提到的多层感知机。这⾥定义的 MLP 类重载了Module 类的 __init__ 函数和 forward 函数。它们分别⽤于创建模型参数和定义前向计算。前向计算也即正向传播。
import torch
from torch import nn
class MLP:
# 声明带有模型参数的层,这⾥声明了两个全连接层
def __init__(self, **kwargs):
# 调⽤MLP⽗类Block的构造函数来进⾏必要的初始化。这样在构造实例时还可以指定其他函数
# 参数,如“模型参数的访问、初始化和共享”⼀节将介绍的模型参数params
super(MLP, self).__init__(**kwargs)
self.hidden = nn.Linear(784, 256) # 隐藏层
self.act = nn.ReLU()
self.output = nn.Linear(256, 10) # 输出层
# 定义模型的前向计算,即如何根据输⼊x计算返回所需要的模型输出
def forward(self, x):
a = self.act(self.hidden(x))
return self.output(a)
以上的 MLP 类中⽆须定义反向传播函数。系统将通过⾃动求梯度⽽⾃动⽣成反向传播所需的backward 函数。
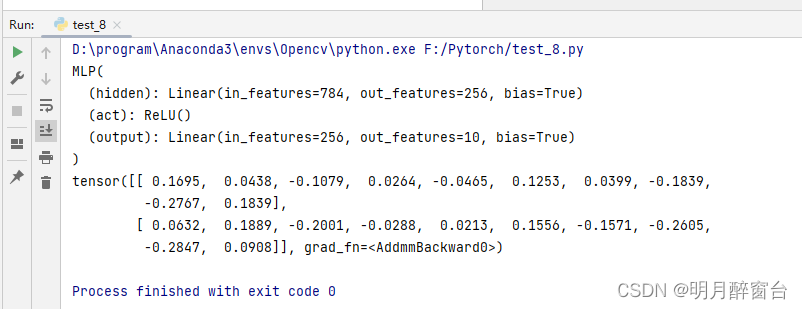
我们可以实例化 MLP 类得到模型变量 net 。下⾯的代码初始化 net 并传⼊输⼊数据 X 做⼀次前向计
算。其中, net(X) 会调⽤ MLP 继承⾃ Module 类的 __call__ 函数,这个函数将调⽤ MLP 类定义的forward 函数来完成前向计算。
X = torch.rand(2, 784)
net = MLP()
print(net)
print(net(X))
1.2 MODULE的子类
Module 类是⼀个通⽤的部件。事实上,PyTorch还实现了继承⾃ Module 的可以⽅便构建模型的类: 如 Sequential 、 ModuleList 和 ModuleDict 等等。
- 1.Sequential类
它可以接收⼀个⼦模块的有序字典(OrderedDict)或者⼀系列⼦模块作为参数来逐⼀添加Module的实例,⽽模型的前向计算就是将这些实例按添加的顺序逐⼀计算。
from collections import OrderedDict
class MySequential(nn.Module):
def __init__(self, *args):
super(MySequential, self).__init__()
if len(args) == 1 and isinstance(args[0], OrderedDict): # 如果传⼊的是⼀个OrderedDict
for key, module in args[0].items():
self.add_module(key, module) # add_module⽅法会将module添加进self._modules(⼀个OrderedDict)
else: # 传⼊的是⼀些Module
for idx, module in enumerate(args):
self.add_module(str(idx), module)
def forward(self, input):
# self._modules返回⼀个 OrderedDict,保证会按照成员添加时的顺序遍历成
for module in self._modules.values():
input = module(input)
return input
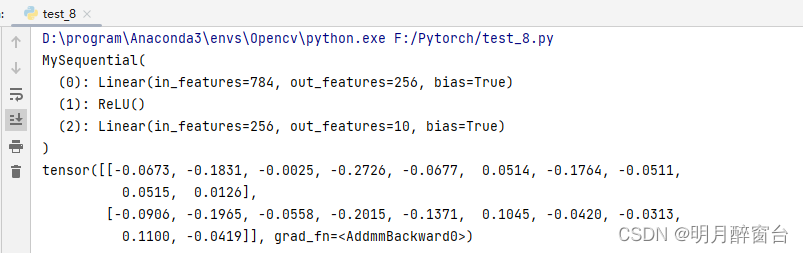
net = MySequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10),
)
print(net)
X = torch.rand(2, 784)
print(net(X))
- 2.ModuleLise类
ModuleList接收⼀个⼦模块的列表作为输⼊,然后也可以类似List那样进⾏append和extend操作:
net = nn.ModuleList([nn.Linear(784, 256), nn.ReLU()])
net.append(nn.Linear(256, 10)) # # 类似List的append操作
print(net[-1]) # 类似List的索引访问
print(net)

- 3.ModuleDict类
ModuleDict接收⼀个⼦模块的字典作为输⼊, 然后也可以类似字典那样进⾏添加访问操作:
net = nn.ModuleDict({
'linear': nn.Linear(784, 256),
'act': nn.ReLU(),
})
net['output'] = nn.Linear(256, 10) # 添加
print(net['linear']) # 访问
print(net.output)
print(net)

1.3 构建复杂的模型
下⾯构造⼀个稍微复杂点的⽹络 FancyMLP 。在这个⽹络中,我们通过 get_constant 函数创建训练中不被迭代的参数,即常数参数。在前向计算中,除了使⽤创建的常数参数外,我们还使⽤ Tensor 的函数和Python的控制流,并多次调⽤相同的层。
class FancyMLP(nn.Module):
def __init__(self, **kwargs):
super(FancyMLP, self).__init__(**kwargs)
self.rand_weight = torch.rand((20, 20),requires_grad=False) # 不可训练参数(常数参数)
self.linear = nn.Linear(20, 20)
def forward(self, x):
x = self.linear(x)
# 使⽤创建的常数参数,以及nn.functional中的relu函数和mm函数
x = nn.functional.relu(torch.mm(x, self.rand_weight.data) + 1)
# 复⽤全连接层。等价于两个全连接层共享参数
x = self.linear(x)
# 控制流,这⾥我们需要调⽤item函数来返回标量进⾏⽐较
while x.norm().item() > 1:
x /= 2
if x.norm().item() < 0.8:
x *= 10
return x.sum()
在这个 FancyMLP 模型中,我们使⽤了常数权重 rand_weight (注意它不是可训练模型参数)、做了矩阵乘法操作( torch.mm )并᯿复使⽤了相同的 Linear 层。下⾯我们来测试该模型的前向计算。

因为 FancyMLP 和 Sequential 类都是 Module 类的⼦类,所以我们可以嵌套调⽤它们。
class NestMLP(nn.Module):
def __init__(self, **kwargs):
super(NestMLP, self).__init__(**kwargs)
self.net = nn.Sequential(nn.Linear(40, 30), nn.ReLU())
def forward(self, x):
return self.net(x)
net = nn.Sequential(NestMLP(), nn.Linear(30, 20), FancyMLP())
X = torch.rand(2, 40)
print(net)
print(net(X))

2.模型参数的访问、初始化和共享
通过 init 模块来初始化模型的参数。从 nn 中导⼊了 init 模块,它包含了多种模型初始化⽅法。
import torch
from torch import nn
from torch.nn import init
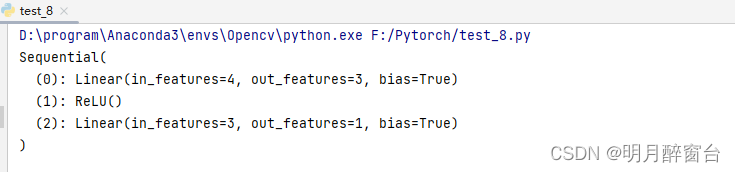
net = nn.Sequential(nn.Linear(4, 3), nn.ReLU(), nn.Linear(3, 1)) #pytorch已进⾏默认初始化
print(net)
X = torch.rand(2, 4)
Y = net(X).sum()
2.1 访问模型参数
访问多层感知机 net的所有参数:
print(type(net.named_parameters()))
for name, param in net.named_parameters():
print(name, param.size())
for name, param in net[0].named_parameters():
print(name, param.size(), type(param))

因为这⾥是单层的所以没有了层数索引的前缀。另外返回的 param 的 类 型为torch.nn.parameter.Parameter ,其实这是 Tensor 的⼦类,和 Tensor 不同的是如果⼀个 Tensor 是 Parameter ,那么它会⾃动被添加到模型的参数列表⾥,来看下⾯这个例⼦。
class MyModel(nn.Module):
def __init__(self, **kwargs):
super(MyModel, self).__init__(**kwargs)
self.weight1 = nn.Parameter(torch.rand(20, 20))
self.weight2 = torch.rand(20, 20)
def forward(self, x):
pass
n = MyModel()
for name, param in n.named_parameters():
print(name)
#⽤ grad 来访问参数梯度。
weight_0 = list(net[0].parameters())[0]
print(weight_0.data)
print(weight_0.grad) # 反向传播前梯度为None
Y.backward()
print(weight_0.grad)

2.2 初始化模型参数
经常需要使⽤其他⽅法来初始化权重。PyTorch的 init 模块⾥提供了多种预设的初始化⽅法。在下⾯的例⼦中,将权重参数初始化成均值为0、标准差为0.01的正态分布随机数,并依然将偏差参数清零。
#正态分布随机数初始化
for name, param in net.named_parameters():
if 'weight' in name:
init.normal_(param, mean=0, std=0.01)
print(name, param.data)
#常数初始化
for name, param in net.named_parameters():
if 'bias' in name:
init.constant_(param, val=0)
print(name, param.data)
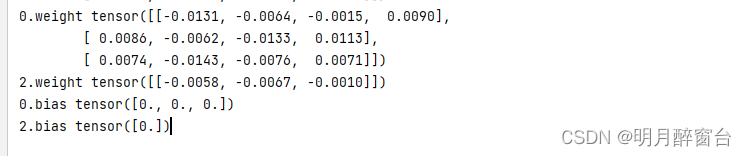
如果只想对某个特定参数进⾏初始化,我们可以调⽤
Parameter类的initialize函数,它与Block类提供的initialize函数的使⽤⽅法⼀致。下例中我们对隐藏层的权重使⽤Xavier随机初始化⽅法。
2.3 自定义初始化方法
def normal_(tensor, mean=0, std=1):
with torch.no_grad():
return tensor.normal_(mean, std)
#令权重有⼀半概率初始化为0,有另⼀半概率初始化为[-10,-5]和[5,10]两个区间⾥均匀分布的随机数。
def init_weight_(tensor):
with torch.no_grad():
tensor.uniform_(-10, 10)
tensor *= (tensor.abs() >= 5).float()
for name, param in net.named_parameters():
if 'weight' in name:
init_weight_(param)
print(name, param.data)
for name, param in net.named_parameters():
if 'bias' in name:
param.data += 1
print(name, param.data)

2.4 共享模型参数
在有些情况下,我们希望在多个层之间共享模型参数。 Module 类的forward 函数⾥多次调⽤同⼀个层。此外,如果我们传⼊ Sequential 的模块是同⼀个 Module 实例的话参数也是共享的,下⾯来看⼀个例⼦:
linear=nn.Linear(1,1,bias=False)
net=nn.Sequential(linear,linear)
print(net)
for name,para in net.named_parameters():
init.constant_(para,val=3)
print(name,param.data)
output:
Sequential(
(0): Linear(in_features=1, out_features=1, bias=False)
(1): Linear(in_features=1, out_features=1, bias=False)
)
0.weight tensor([[5.5303e-01, 7.0191e-01, 1.9245e-01, 3.7774e-01, 8.0472e-01, 2.7682e-01,
4.5107e-01, 2.9235e-01, 7.6745e-01, 2.2634e-01, 7.6558e-01, 6.1818e-01,
4.3465e-01, 1.8283e-01, 4.0362e-01, 4.5455e-01, 8.0183e-01, 4.8837e-01,
9.4789e-01, 2.5151e-01],
[9.8505e-01, 4.2311e-01, 8.4915e-01, 9.1297e-01, 9.0732e-01, 9.2116e-01,
2.8427e-01, 5.6820e-01, 7.3468e-01, 8.6759e-01, 7.4663e-01, 2.8881e-01,
8.3152e-01, 5.6294e-01, 7.3268e-01, 8.4266e-02, 6.3633e-01, 6.1282e-01,
8.9950e-02, 6.7095e-01],
[9.3425e-01, 9.4323e-03, 7.4351e-01, 9.0603e-01, 5.6923e-01, 2.7223e-01,
7.5024e-01, 5.2797e-01, 8.9410e-01, 5.1987e-01, 8.6359e-01, 5.6568e-01,
2.1681e-01, 7.9124e-01, 9.3494e-01, 5.7668e-01, 2.4367e-01, 8.1391e-01,
6.8308e-01, 3.3805e-01],
[1.9705e-01, 7.1832e-02, 5.8697e-01, 2.5607e-01, 7.1367e-01, 3.7178e-01,
4.0495e-01, 8.1241e-05, 2.2806e-01, 9.1694e-01, 5.0363e-01, 1.9479e-01,
5.6658e-01, 3.0949e-01, 4.8288e-01, 7.3495e-01, 3.6118e-01, 4.7504e-01,
1.8672e-01, 9.9713e-01],
[1.3815e-01, 9.7469e-01, 2.7226e-01, 5.6999e-01, 6.9001e-01, 6.5725e-01,
9.1013e-01, 4.4881e-01, 8.5847e-01, 9.3742e-01, 2.9996e-01, 1.4086e-01,
9.6874e-01, 7.7811e-01, 5.8916e-01, 2.5447e-01, 1.7417e-01, 1.7399e-01,
4.5080e-01, 3.6706e-01],
[9.8182e-01, 1.8151e-01, 2.5530e-01, 8.5143e-01, 7.4743e-01, 4.4052e-02,
8.2197e-01, 4.5387e-01, 1.4732e-01, 3.5138e-01, 8.2475e-01, 3.7510e-01,
7.5866e-01, 7.0283e-01, 8.1535e-01, 1.1192e-01, 5.1464e-01, 2.7579e-01,
9.0549e-02, 2.8739e-02],
[7.5375e-01, 6.9455e-01, 7.1689e-01, 2.3077e-01, 7.0419e-01, 5.0617e-01,
7.4758e-01, 6.0428e-01, 7.4255e-02, 8.0747e-01, 7.0709e-01, 5.6128e-01,
6.0851e-01, 6.6408e-01, 3.4243e-01, 7.0581e-01, 3.1188e-01, 2.9577e-01,
9.0396e-01, 8.6007e-01],
[5.9613e-01, 9.9631e-01, 4.8880e-01, 2.8524e-01, 2.4216e-01, 1.5289e-02,
3.5943e-02, 7.6430e-01, 3.4297e-01, 4.8015e-01, 7.2521e-02, 8.3275e-01,
2.5611e-01, 4.3427e-01, 1.9307e-01, 3.2186e-02, 2.8802e-01, 9.3776e-01,
7.0968e-01, 1.9674e-01],
[3.4048e-01, 3.8660e-01, 5.0662e-01, 8.8157e-01, 9.2499e-01, 3.2909e-01,
1.1336e-03, 9.5637e-01, 6.6204e-01, 8.3722e-01, 2.4536e-01, 1.0628e-01,
9.7823e-02, 1.8686e-01, 1.1717e-01, 9.8579e-01, 6.1623e-01, 1.6925e-01,
4.6191e-01, 3.9800e-01],
[5.0451e-01, 5.4327e-01, 3.8235e-02, 4.6853e-01, 4.7947e-02, 5.0615e-01,
3.0354e-02, 3.8598e-01, 8.3647e-01, 6.0252e-01, 3.0790e-01, 9.3672e-01,
7.8393e-01, 6.8209e-01, 2.0146e-01, 8.3221e-01, 2.5835e-01, 7.6942e-01,
8.2981e-02, 4.9463e-01],
[1.1802e-01, 3.6234e-01, 6.9322e-02, 8.7252e-02, 6.3055e-01, 5.7227e-01,
3.1692e-01, 6.5900e-01, 3.3459e-01, 1.7138e-01, 2.1619e-01, 5.0878e-01,
4.9716e-01, 8.3073e-01, 8.0581e-01, 2.4556e-01, 3.6375e-01, 2.0785e-01,
2.7205e-03, 5.6275e-01],
[2.7199e-01, 5.2199e-01, 5.2975e-01, 2.4573e-01, 8.7303e-01, 4.6517e-01,
7.4827e-01, 3.6025e-01, 2.3450e-01, 2.0624e-01, 6.9650e-01, 1.4945e-01,
2.1434e-01, 1.0464e-01, 7.2625e-01, 5.1532e-01, 6.6277e-01, 8.5656e-01,
5.3705e-01, 7.9157e-01],
[7.9171e-01, 9.3892e-01, 9.1319e-01, 8.8270e-01, 8.8875e-02, 8.4999e-01,
3.8649e-01, 7.1867e-01, 9.0185e-01, 1.2597e-01, 8.8258e-01, 8.3497e-01,
2.3219e-01, 2.3167e-01, 3.3532e-01, 8.7171e-02, 7.5229e-01, 6.8331e-02,
4.3497e-01, 8.7568e-01],
[3.6040e-01, 6.0734e-01, 7.5852e-01, 4.7620e-01, 3.9695e-01, 3.5119e-01,
9.4932e-01, 2.0985e-01, 2.5509e-02, 7.0270e-01, 7.8877e-01, 7.4630e-01,
4.7739e-01, 4.7588e-01, 7.3373e-01, 9.6523e-01, 9.6442e-01, 2.9483e-01,
2.6605e-01, 2.8249e-01],
[8.0272e-01, 9.5639e-01, 1.5139e-01, 9.0017e-01, 4.7849e-01, 6.7524e-01,
5.6150e-01, 3.3627e-01, 4.3344e-01, 5.6122e-01, 5.3893e-01, 9.7596e-01,
7.8377e-02, 4.8279e-01, 3.9381e-01, 7.6723e-01, 5.2364e-01, 5.3827e-01,
5.7597e-01, 3.7710e-01],
[4.8978e-01, 4.3592e-01, 3.6772e-01, 2.0139e-01, 6.8215e-01, 3.4520e-01,
5.3991e-01, 8.0897e-01, 3.4824e-01, 6.0208e-01, 6.0715e-01, 5.5593e-01,
1.3036e-01, 8.7818e-01, 7.2645e-01, 2.5022e-01, 8.4373e-01, 1.9682e-01,
6.8626e-02, 9.6470e-01],
[5.7388e-01, 4.7398e-01, 7.7536e-01, 4.5095e-01, 9.7024e-01, 6.2415e-01,
9.8084e-01, 4.8234e-01, 9.7246e-01, 3.6736e-01, 5.5821e-01, 9.3364e-01,
7.2241e-01, 1.6637e-01, 6.9244e-01, 1.0545e-01, 6.0283e-02, 8.4529e-01,
2.5742e-01, 1.4184e-01],
[6.8516e-01, 1.1498e-01, 4.0362e-01, 2.9137e-01, 6.3416e-01, 7.0197e-01,
3.6142e-01, 9.3125e-01, 8.2188e-01, 9.6484e-01, 1.5606e-01, 6.1644e-02,
3.1163e-01, 2.1861e-01, 8.1823e-01, 9.9826e-01, 5.6127e-02, 6.1779e-01,
1.3358e-01, 9.4694e-01],
[5.7551e-01, 4.3031e-02, 6.6707e-01, 9.4477e-01, 1.8009e-01, 1.4106e-01,
2.8744e-01, 7.0596e-01, 1.9078e-01, 6.9894e-01, 4.9123e-01, 9.1460e-01,
4.3481e-01, 2.9027e-01, 8.5328e-02, 2.7469e-01, 9.6227e-01, 8.3866e-01,
8.9694e-01, 1.5642e-01],
[5.6068e-01, 6.2449e-01, 8.0295e-01, 9.8608e-01, 5.9384e-01, 8.1683e-01,
9.8685e-01, 6.8946e-01, 3.9386e-01, 4.3990e-01, 5.4052e-01, 4.5170e-01,
5.5431e-01, 6.3456e-01, 3.0106e-03, 8.7789e-01, 2.6254e-01, 2.1360e-01,
4.5750e-01, 7.3091e-01]])
在内存中,这两个线性层其实是一个对象:
print(id(net[0])==id(net[1]))
print(id(net[0].weight)==id(net[1].weight))
***output:
True
True
因为模型参数⾥包含了梯度,所以在反向传播计算时,这些共享的参数的梯度是累加的:
x = torch.ones(1, 1)
y = net(x).sum()
print(y)
y.backward()
print(net[0].weight.grad) # 单次梯度是3,两次所以就是6
***output:
tensor(9., grad_fn=<SumBackward0>)
tensor([[6.]])
3.模型参数的延后初始化
由于使⽤
Gluon创建的全连接层的时候不需要指定输⼊个数。所以当调⽤initialize函数时,由于隐藏层输⼊个数依然未知,系统也⽆法得知该层权᯿参数的形状。只有在当形状已知的输⼊X传进⽹络做前向计算net(X)时,系统才推断出该层的权重参数形状为多少,此时才进⾏真正的初始化操作。但是使⽤PyTorch在定义模型的时候就要指定输⼊的形状,所以也就不存在这个问题了。
——————
下边介绍延后初始化的应用情况:参考:https://zh.d2l.ai/chapter_deep-learning-computation/deferred-init.html
到目前为止,我们忽略了建立网络时需要做的以下这些事情:
- 我们定义了网络架构,但没有指定输入维度。
- 我们添加层时没有指定前一层的输出维度。
- 我们在初始化参数时,甚至没有足够的信息来确定模型应该包含多少参数。
这里的诀窍是框架的延后初始化(defers initialization), 即直到数据第一次通过模型传递时,框架才会动态地推断出每个层的大小。
首先,实例化一个网络:
from mxnet import np, npx
from mxnet.gluon import nn
npx.set_np()
def get_net():
net = nn.Sequential()
net.add(nn.Dense(256, activation='relu'))
net.add(nn.Dense(10))
return net
net = get_net()
此时,因为输入维数是未知的,所以网络不可能知道输入层权重的维数。 因此,框架尚未初始化任何参数,我们通过尝试访问以下参数进行确认。
print(net.collect_params)
print(net.collect_params())

注意,当参数对象存在时,每个层的输入维度为-1。 MXNet使用特殊值-1表示参数维度仍然未知。 此时,尝试访问net[0].weight.data()将触发运行时错误, 提示必须先初始化网络,然后才能访问参数。 现在让我们看看当我们试图通过initialize函数初始化参数时会发生什么。
net.initialize()
net.collect_params()

如我们所见,一切都没有改变。 当输入维度未知时,调用initialize不会真正初始化参数。 而是会在MXNet内部声明希望初始化参数,并且可以选择初始化分布。
接下来让我们将数据通过网络,最终使框架初始化参数。
X = np.random.uniform(size=(2, 20))
net(X)
net.collect_params()

一旦我们知道输入维数是20,框架可以通过代入值20来识别第一层权重矩阵的形状。 识别出第一层的形状后,框架处理第二层,依此类推,直到所有形状都已知为止。 注意,在这种情况下,只有第一层需要延迟初始化,但是框架仍是按顺序初始化的。 等到知道了所有的参数形状,框架就可以初始化参数。