streamsets的下载流程:(我建议下载full版本的)
https://blog.csdn.net/yao09605/article/details/104098797
streamsets的同步过程全程是无代码的
下面我介绍整个流程,以及我遇到的坑和排坑方法
下载完之后我们照例直接解压,放到srv目录下,然后更改权限,编辑.bashrc 增加一个STREAMSETS_HOME
这里简单写一下
$ tar -xvf streamsets-datacollector-all-3.13.0.tgz
$ sudo cp streamsets-datacollector-3.13.0 /srv/
$ sudo chown -R hadoop:hadoop /srv/streamsets-datacollector-3.13.0
$ sudo ln -s /srv/streamsets-datacollector-3.13.0 /srv/streamsets
$ vim ~/.bashrc
# .bashrc 增加
export STREAMSETS_HOME=/srv/streamsets
export PATH=$PATH:$STREAMSETS_HOME/bin
$ source ~/.bashrc
启动streamsets
$ streamsets dc
此时可能遇到的报错:
Java 1.8 detected; adding $SDC_JAVA8_OPTS of “-XX:+UseConcMarkSweepGC -XX:+UseParNewGC -Djdk.nio.maxCachedBufferSize=262144” to $SDC_JAVA_OPTS
Configuration of maximum open file limit is too low: 1024 (expected at least 32768). Please consult https://goo.gl/6dmjXd
这个是因为系统默认同时打开文件数1024过小,我们需要设置
网上查了几个方法,好像都没有用
我使用的方式是进入root
$ su
root@yaochenli-VirtualBox:/etc# ulimit -n 63553
root@yaochenli-VirtualBox:/etc# su hadoop
切换回原来的用户就能顺利开启streamsets dc 服务了
在浏览器中输入:http://localhost:18630/
这个是streamsets的管理页面
进入后密码和用户名都是admin
进入之后可以新建一个pipeline,我这里已经新建好一个了
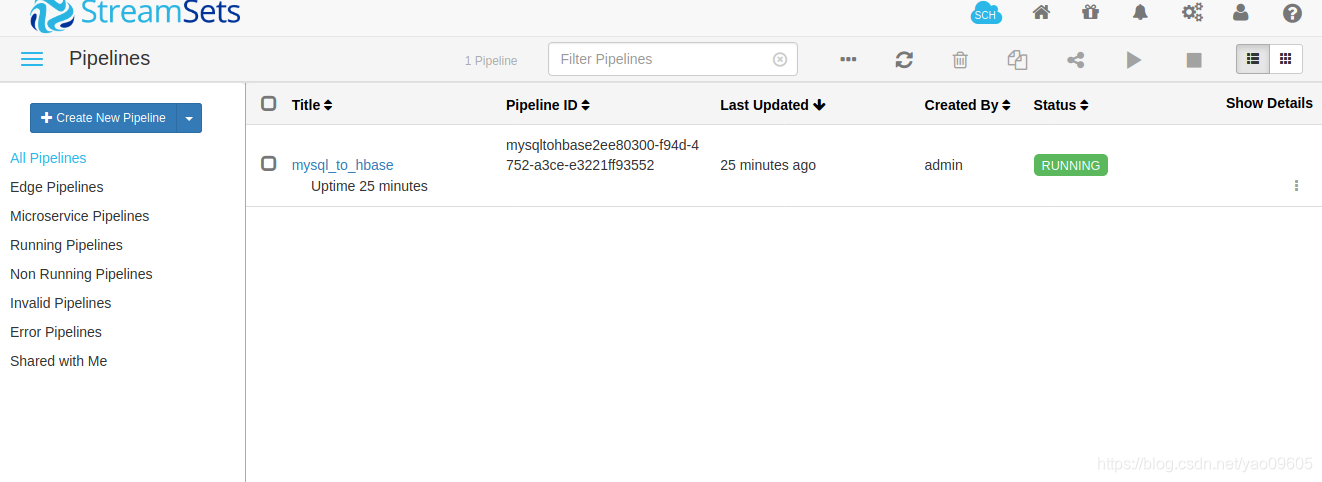 这里新建一个tutorial演示
这里新建一个tutorial演示
 选择origin就是你的原系统
选择origin就是你的原系统
我们选择mysql的binlog
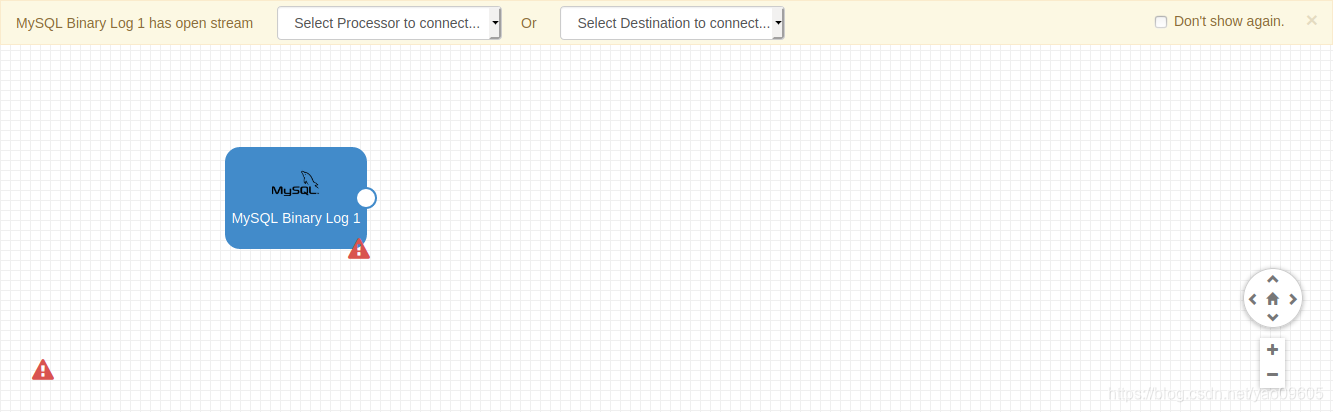 然后会出现两个选项,一个是选择中间处理件或者选择目标系统,中间件可以做一些筛选工作,然后目标系统就是你要把数据导到哪里。
然后会出现两个选项,一个是选择中间处理件或者选择目标系统,中间件可以做一些筛选工作,然后目标系统就是你要把数据导到哪里。
我们看我做好的这个例子:
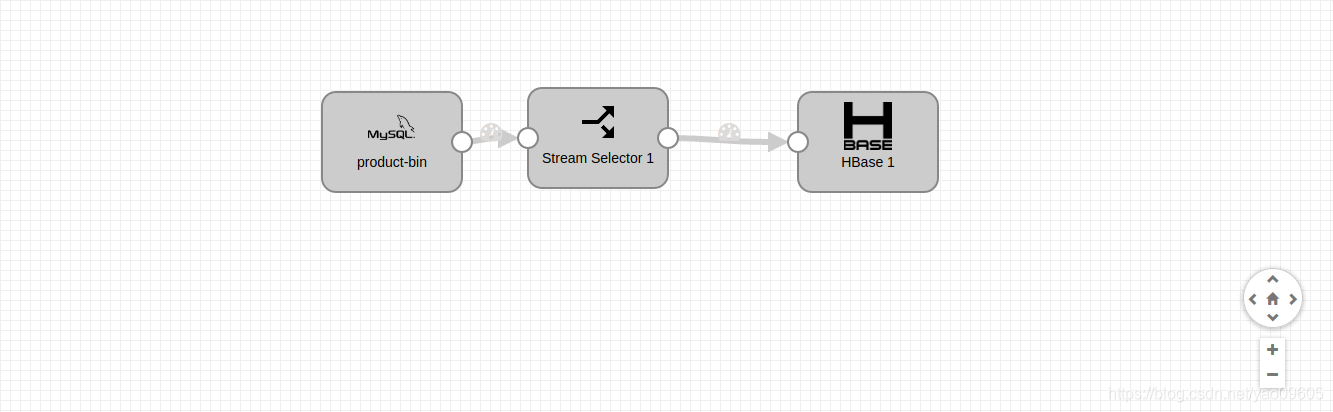 然后重点就是这三个组件的配置
然后重点就是这三个组件的配置
首先是mysql
这一页没什么重点,随便填
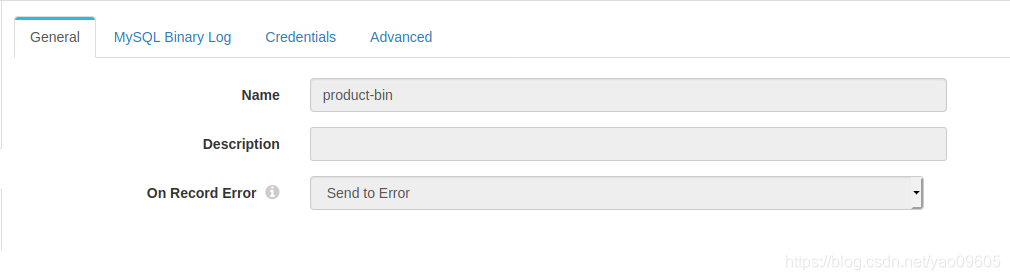 这里注意serverID不能和你mysql里面my.cnf文件里的server_id重复,不然运行时候会报错
这里注意serverID不能和你mysql里面my.cnf文件里的server_id重复,不然运行时候会报错
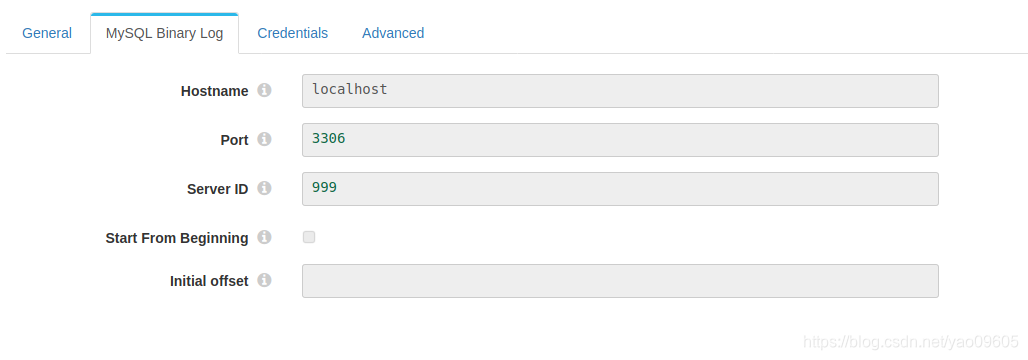 这里注意必须是root用户,mysql的root用户初始是没有密码的,如果不知道怎么给root用户设置密码请看这个链接https://blog.csdn.net/yao09605/article/details/104101433
这里注意必须是root用户,mysql的root用户初始是没有密码的,如果不知道怎么给root用户设置密码请看这个链接https://blog.csdn.net/yao09605/article/details/104101433
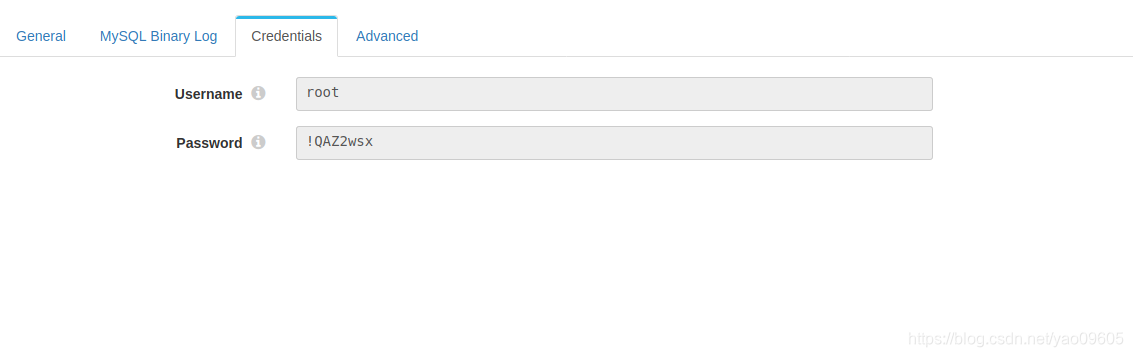 这里可以设置你要监控的表明,格式是[DATABASE].[TABLE],其余参数根据需要设置。
这里可以设置你要监控的表明,格式是[DATABASE].[TABLE],其余参数根据需要设置。
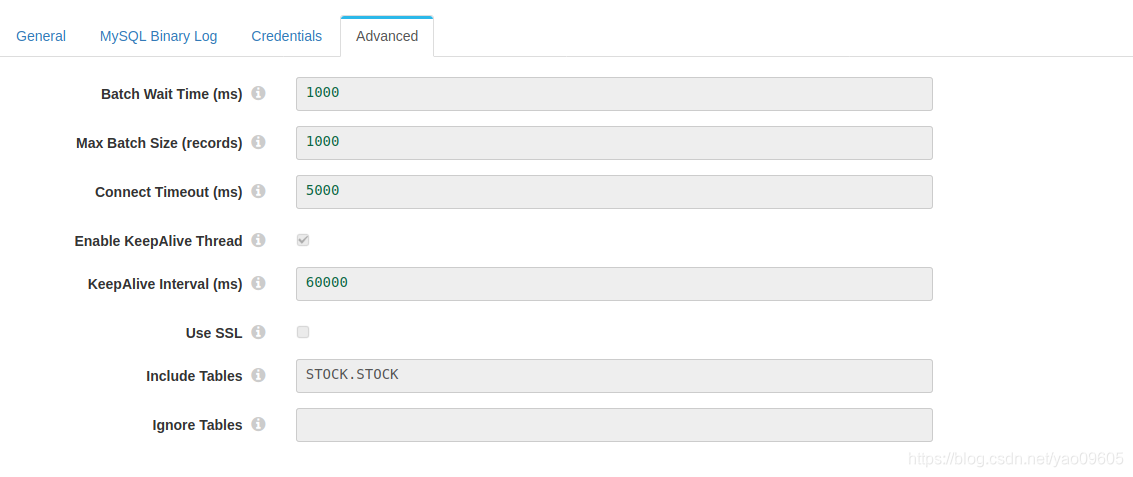 中间件我们不做任何处理,这里不展示配置了。
中间件我们不做任何处理,这里不展示配置了。
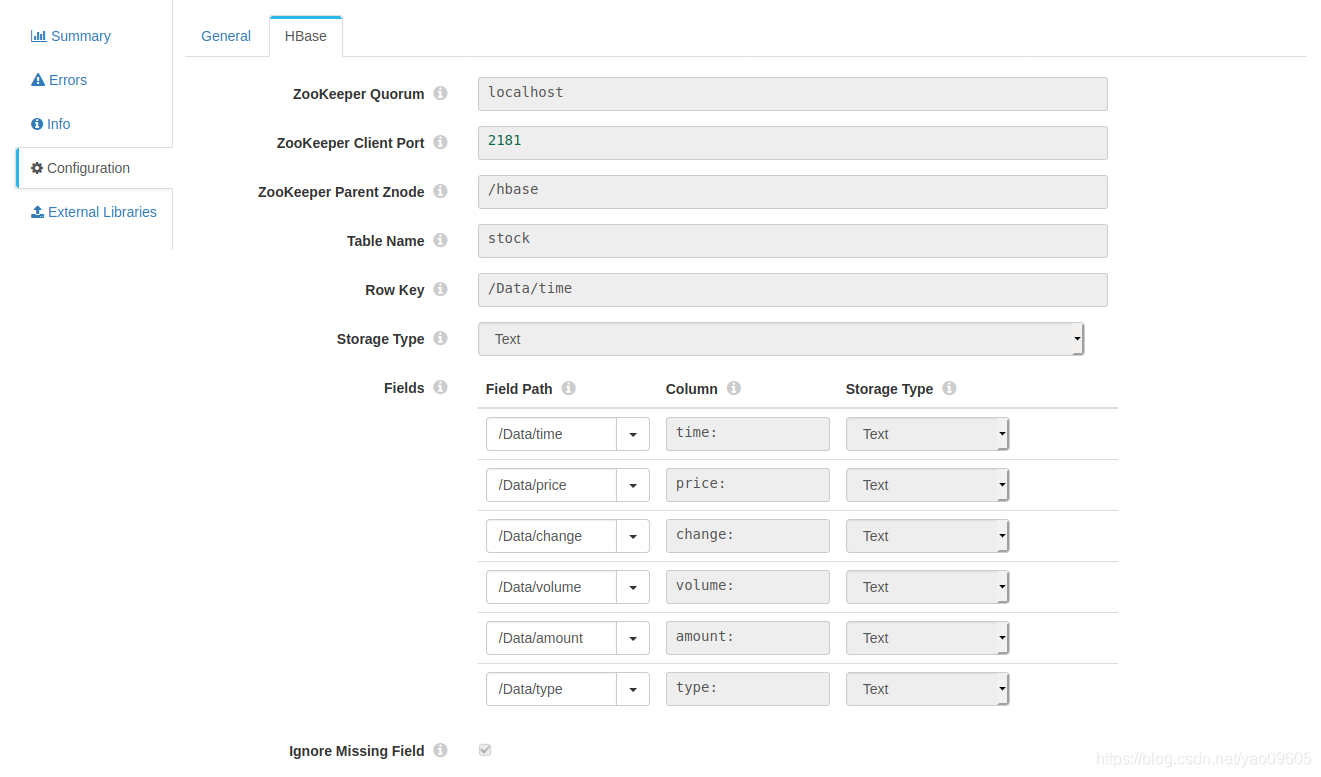
下面是hbase的配置:
这里要注意的是CDH的版本也就是hbase client的版本要和你hbase服务的版本一致,不一致会报错的,这也是我为什么推荐下载full版本,这样你很简单的试验几个选项而不用重复去下载。
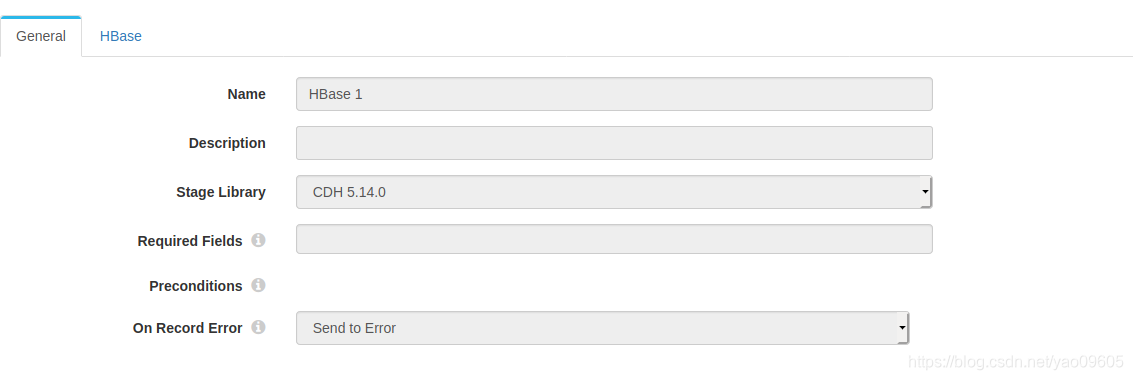 这里要注意的点是源系统数据格式要写成/Data/XXX的形式,目标的column格式是【列族:列名】如果没有列名,列族之后也要加冒号。
这里要注意的点是源系统数据格式要写成/Data/XXX的形式,目标的column格式是【列族:列名】如果没有列名,列族之后也要加冒号。
其他大家看那个问好里的提示吧。
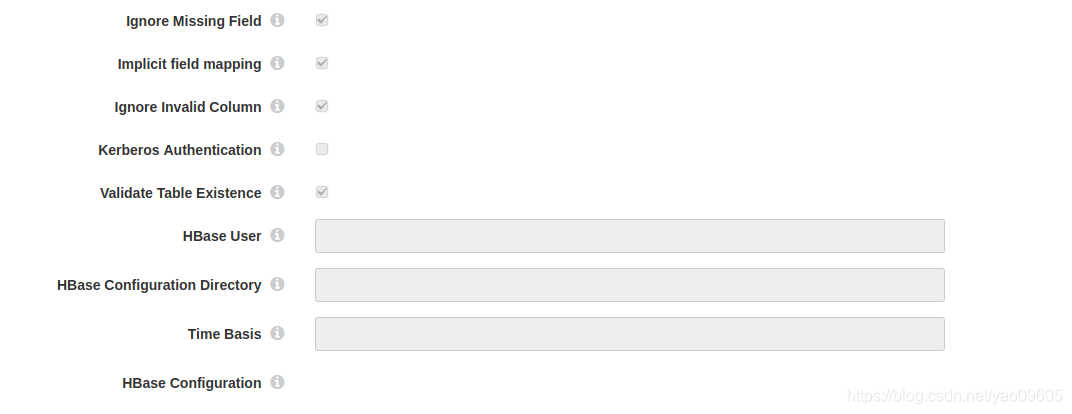 这边配置准备完成之后,我们需要在两边系统里建好表。
这边配置准备完成之后,我们需要在两边系统里建好表。
CREATE TABLE `STOCK` (
`time` text,
`price` double DEFAULT NULL,
`change` double DEFAULT NULL,
`volume` bigint(20) DEFAULT NULL,
`amount` bigint(20) DEFAULT NULL,
`type` text
)
首先把hadoop和hbase启动起来
$ start-dfs.sh
$ start-yarn.sh
$ start-hbase.sh
$ jps
如果你看到下面这些服务在运行,那么就没有问题了
10400 Jps
9600 HRegionServer
3812 SecondaryNameNode
3557 DataNode
4007 ResourceManager
4168 NodeManager
4618 BootstrapMain
9468 HMaster
9405 HQuorumPeer
3390 NameNode
在hbase那边也建表:
# 有可能不对,仅供参考
create 'stock','time','amount','change','price','type','volume'
两边建表好了之后就可以测试一下通路了
点击右上角的小眼睛
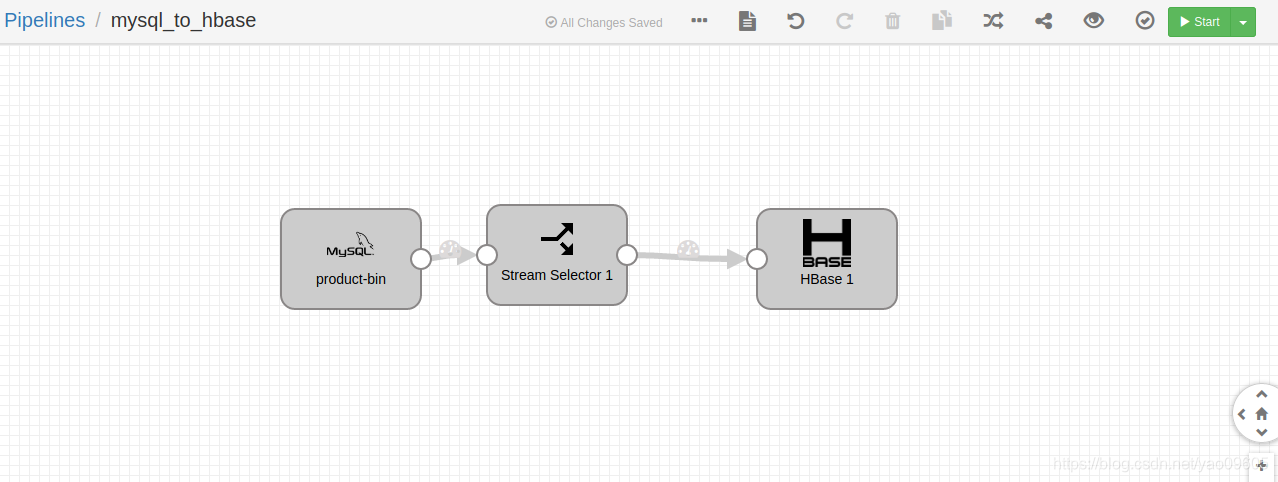 可能遇到的问题呢除了刚刚说的用户必须是root之外,你有可能没有打开binlog,如何查看呢
可能遇到的问题呢除了刚刚说的用户必须是root之外,你有可能没有打开binlog,如何查看呢
进入mysql的shell
mysql> show variables like 'log_bin%';
+---------------------------------+-----------------------------+
| Variable_name | Value |
+---------------------------------+-----------------------------+
| log_bin | ON |
| log_bin_basename | /var/log/mysql/binlog |
| log_bin_index | /var/log/mysql/binlog.index |
| log_bin_trust_function_creators | OFF |
| log_bin_use_v1_row_events | OFF |
+---------------------------------+-----------------------------+
5 rows in set (0.01 sec)
看下自己的log_bin是否打开了
如果没有打开,那么打开他的方法如下:
$ sudo vim /etc/mysql/my.cnf
my.cnf
!includedir /etc/mysql/conf.d/
!includedir /etc/mysql/mysql.conf.d/
#bin log
[mysqld]
log_bin=mysql_bin
binlog_format=ROW
server_id=100
log-bin=/var/log/mysql/binlog
增加上面的配置后,重启服务,或者你的电脑。
再检查一下应该就打开了
你的这个binlog文件就在/var/log/mysql目录下。
root@yaochenli-VirtualBox:/var/log/mysql# ls
binlog binlog.000002 binlog.index error.log.1.gz error.log.3.gz error.log.5.gz error.log.7.gz
binlog.000001 binlog.000003 error.log error.log.2.gz error.log.4.gz error.log.6.gz product-bin.index
如果还是提示没有binlog的话,就往mysql里面插点东西,生成个文件。
应该没有别的坑了,我们点击run启动服务。然后,我们写个小程序往mysql里面插入数据:
#股票分笔数据
import tushare as ts
import pymysql
from sqlalchemy import create_engine
df = ts.get_tick_data('600848',date='2018-12-12',src='tt')
engine = create_engine('mysql+pymysql://hive:[email protected]:3306/STOCK?charset=utf8mb4')
con = engine.connect()
# 这里ubuntu下面给mysql输入中文有点问题,最后就放弃中文了。
df = df.replace('买盘',0)
df = df.replace('卖盘',1)
df = df.replace('中性盘',2)
df.to_sql(name='STOCK', con=con, if_exists='append', index=False)
运行之后我们可以看到仪表盘有数据了,
然后去hbase检查
hbase(main):001:0> scan ‘stock’
可以看到数据就可以了。
