为了解决公司数据统计,数据分析等各种问题,我们可以有很多手段,最常用的手段就是通过构建数据仓库的手段来实现我们的数据分析,数据挖掘等,其中,数据仓库基本上都是统计前一天的数据,或者最近一段时间的数据,这就决定了数据仓库一般都是使用离线的技术来实现,通过离线的技术手段,来实现前一天或者近一段时间的数据统计功能,为了解决数据统计的时效性问题,我们也可以通过实时的手段来构建数据仓库,通过流式API,结合flink的TableAPI或者SQL功能,即可实现我们实时的数据统计,构建实时的数据仓库
1:实时数仓架构
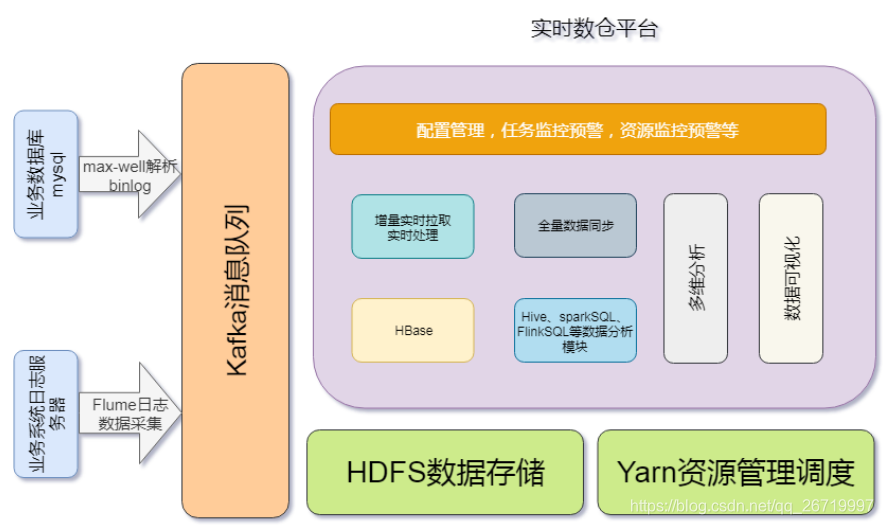
实时数仓主要用于处理各种数据,其中包括点击日志数据,业务库数据,爬虫竞品数据,业务库当中的数据主要可以通过canal来实现数据实时同步处理,日志数据可以通过flume等采集工具,全量导入可以通过sqoop或者maxwell来实现,通过各种数据采集手段,将我们的数据统一接入到kafka消息队列
2:mysql数据实时同步
2.1:mysql的binlog介绍
- binlog是mysql当中的二进制日志,主要用于记录对mysql数据库当中的数据发生或潜在发生更改的SQL语句,并以二进制的形式保存在磁盘中,如果后续我们需要配置主从数据库,如果我们需要从数据库同步主数据库的内容,我们就可以通过binlog来进行同步。说白了binlog可以用于解决实时同步mysql数据库当中的数据
- binlog的格式也有三种:STATEMENT、ROW、MIXED 。
- STATMENT模式:基于SQL语句的复制(statement-based replication, SBR),每一条会修改数据的sql语句会记录到binlog中。
- 优点:不需要记录每一条SQL语句与每行的数据变化,这样子binlog的日志也会比较少,减少了磁盘IO,提高性能。
- 缺点:在某些情况下会导致master-slave中的数据不一致(如sleep()函数, last_insert_id(),以及 user-defined functions(udf)等会出现问题)
- 基于行的复制(row-based replication, RBR):不记录每一条SQL语句的上下文信息,仅需记录哪条数据被修改了,修改成了什么样子了。
- 优点:不会出现某些特定情况下的存储过程或function、或trigger的调用和触发无法被正确复制的问题。
- 缺点:会产生大量的日志,尤其是alter table的时候会让日志暴涨。
- 混合模式复制(mixed-based replication, MBR):以上两种模式的混合使用,一般的复制使 用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog, MySQL会根据执行的SQL语句选择日志保存方式。
- 因为statement只有sql,没有数据,无法获 取原始的变更日志,所以一般建议为ROW模式)
- STATMENT模式:基于SQL语句的复制(statement-based replication, SBR),每一条会修改数据的sql语句会记录到binlog中。
2.2:max-well的基本介绍
Maxwell是一个能实时读取MySQL二进制日志binlog,并生成 JSON 格式的消息,作为生产者发送给 Kafka,Kinesis、RabbitMQ、Redis、Google Cloud Pub/Sub、文件或其它平台的应用程序。它的常见应用场景有ETL、维护缓存、收集表级别的dml指标、增量到搜索引擎、数据分区迁移、切库binlog回滚方案等。
- 官网:http://maxwells-daemon.io
- GitHub:https://github.com/zendesk/maxwell
- Maxwell主要提供了下列功能
- 支持 SELECT * FROM table 的方式进行全量数据初始化
- 支持在主库发生failover后,自动恢复binlog位置(GTID)
- 可以对数据进行分区,解决数据倾斜问题,发送到kafka的数据支持database、table、column等级别的数据分区
- 工作方式是伪装为Slave,接收binlog events,然后根据schemas信息拼装,可以接受ddl、xid、row等各种event
- 除了Maxwell外,目前常用的MySQL Binlog解析工具主要有阿里的canal、mysql_streamer
2.3:开启mysql的binlog功能
-
第一步:添加mysql普通用户maxwell
mysql -uroot -p set global validate_password_policy=LOW; set global validate_password_length=6; CREATE USER 'maxwell'@'%' IDENTIFIED BY '123456'; GRANT ALL ON maxwell.* TO 'maxwell'@'%'; GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE on *.* to 'maxwell'@'%'; flush privileges; -
第二步:开启mysql的binlog机制
# 修改mysql配置文件 sudo vim /etc/my.cnf log-bin=mysql-bin binlog-format=ROW server_id=1 # 重启mysql服务 sudo service mysqld restart
2.4:安装max-well实现实时采集mysql数据
- 第一步:下载max-well并上传解压
- 下载地址:https://github.com/zendesk/maxwell/releases/download/v1.21.1/maxwell-1.21.1.tar.gz
- 第一步:将下载好的安装包上传到服务器的/opt/路径下,并进行解压
cd /opt tar -zxf maxwell-1.21.1.tar.gz -C /opt/install/ - 第二步:修改maxwell配置文件
cd /opt/install/maxwell-1.21.1 cp config.properties.example config.properties vim config.properties producer=kafka kafka.bootstrap.servers=node01:9092,node02:9092,node03:9092 host=node03.kaikeba.com user=maxwell password=123456 producer=kafka host=node03.kaikeba.com port=3306 user=maxwell password=123456 kafka.bootstrap.servers=node01:9092,node02:9092,node03:9092 kafka_topic=maxwell_kafka - 注意:一定要保证我们使用maxwell用户和123456密码能够连接上mysql数据库
2.5:启动服务
- 启动我们的zookeeper服务,kafka服务并创建kafka的topic,然后启动maxwell服务,测试向数据库当中插入数据,并查看kafka当中是否能够同步到mysql数据
- 启动zookeeper服务:省略
- 启动kafka服务:省略
- 创建kafka的topic:
cd /opt/install/kafka_2.11-1.1.0 bin/kafka-topics.sh --create --topic maxwell_kafka --partitions 3 --replication-factor 2 --zookeeper node01:2181 - node01执行以下命令,启动kafka的自带控制台消费者,消费kafka当中的数据,验证kafka当中是否有数据进入
cd /opt/install/kafka_2.11-1.1.0 bin/kafka-console-consumer.sh --topic maxwell_kafka --from-beginning --bootstrap-server node01:9092,node02:9092,node03:9092 - node03执行以下命令,启动maxwell服务
cd /opt/install/maxwell-1.21.1 bin/maxwell
2.6:插入数据并进行测试
DROP TABLE IF EXISTS `myuser`;
CREATE TABLE `myuser` (
`id` int(12) NOT NULL,
`name` varchar(32) DEFAULT NULL,
`age` varchar(32) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*Data for the table `myuser` */
insert into `myuser`(`id`,`name`,`age`) values (1,'zhangsan',NULL),(2,'xxx',NULL),(3,'ggg',NULL),(5,'xxxx',NULL),(8,'skldjlskdf',NULL),(10,'ggggg',NULL),(99,'ttttt',NULL),(114,NULL,NULL),(121,'xxx',NULL);
- 启动kafka的消费者,验证数据是否进入kafka
cd /opt/install/kafka_2.11-1.1.0
bin/kafka-console-consumer.sh --bootstrap-server node01:9092,node02:9092,node03:9092 --topic maxwell_kafka
3:数据建模
USE `product`;
DROP TABLE IF EXISTS `goods`;
CREATE TABLE `goods` (
`goodsId` BIGINT(10) NOT NULL AUTO_INCREMENT,
`goodsName` VARCHAR(256) DEFAULT NULL, -- 商品名称
`sellingPrice` VARCHAR(256) DEFAULT NULL, -- 商品售价
`productPic` VARCHAR(256) DEFAULT NULL, -- 商品图片
`productBrand` VARCHAR(256) DEFAULT NULL, -- 商品品牌
`productfbl` VARCHAR(256) DEFAULT NULL, -- 手机分片率
`productNum` VARCHAR(256) DEFAULT NULL, -- 商品编号
`productUrl` VARCHAR(256) DEFAULT NULL, -- 商品url地址
`productFrom` VARCHAR(256) DEFAULT NULL, -- 商品来源
`goodsStock` INT(11) DEFAULT NULL, -- 商品库存
`appraiseNum` INT(11) DEFAULT NULL, -- 商品评论数
PRIMARY KEY (`goodsId`)
) ENGINE=INNODB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;
CREATE TABLE product.orders (
orderId int(11) NOT NULL AUTO_INCREMENT COMMENT '自增ID',
orderNo varchar(50) NOT NULL COMMENT '订单号',
userId int(11) NOT NULL COMMENT '用户ID',
goodId int(11) NOT NULL COMMENT '商品ID',
goodsMoney decimal(11,2) NOT NULL DEFAULT '0.00' COMMENT '商品总金额',
realTotalMoney decimal(11,2) NOT NULL DEFAULT '0.00' COMMENT '实际订单总金额',
payFrom int(11) NOT NULL DEFAULT '0' COMMENT '支付来源(1:支付宝,2:微信)',
province varchar(50) NOT NULL COMMENT '省份',
createTime timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`orderId`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
4:获取数据模块开发
我们获取数据主要分为两个模块获取,一个是全量拉取所有数据,一个是通过mysql的binlog来实现实时的拉取数据。
- 全量拉取模块我们可以通过flink去获取数据库当中的商品表数据,然后保存到hbase当中去
- 第一步:创建hbase商品表
cd /kkb/install/hbase-1.2.0-cdh5.14.2 bin/hbase shell create_namespace 'flink' create 'flink:data_goods',{NAME=>'f1',BLOCKCACHE=>true,BLOOMFILTER=>'ROW',DATA_BLOCK_ENCODING => 'PREFIX_TREE', BLOCKSIZE => '65536'} - 第二步:代码开发(实现mysql数据全部同步到hbase)
import org.apache.flink.api.common.typeinfo.BasicTypeInfo import org.apache.flink.api.java.io.jdbc.JDBCInputFormat import org.apache.flink.api.java.typeutils.RowTypeInfo import org.apache.flink.api.scala.hadoop.mapreduce.HadoopOutputFormat import org.apache.flink.api.scala.{ ExecutionEnvironment} import org.apache.flink.types.Row import org.apache.hadoop.conf.Configuration import org.apache.hadoop.hbase.client.{Mutation, Put} import org.apache.hadoop.hbase.mapreduce.TableOutputFormat import org.apache.hadoop.hbase.{HBaseConfiguration, HConstants} import org.apache.hadoop.io.Text import org.apache.hadoop.mapreduce.Job object FullPullerGoods { //全量拉取商品表数据到HBase里面来 def main(args: Array[String]): Unit = { val environment: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment import org.apache.flink.api.scala._ val inputJdbc: JDBCInputFormat = JDBCInputFormat.buildJDBCInputFormat() .setDrivername("com.mysql.jdbc.Driver") .setDBUrl("jdbc:mysql://node03:3306/product?characterEncodint=utf-8") .setPassword("123456") .setUsername("root") .setFetchSize(2) .setQuery("select * from goods") .setRowTypeInfo(new RowTypeInfo(BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.STRING_TYPE_INFO)) .finish() //读取jdbc里面的数据 val goodsSet: DataSet[Row] = environment.createInput(inputJdbc) val result: DataSet[(Text, Mutation)] = goodsSet.map(x => { val goodsId: String = x.getField(0).toString val goodsName: String = x.getField(1).toString val sellingPrice: String = x.getField(2).toString val productPic: String = x.getField(3).toString val proudctBrand: String = x.getField(4).toString val proudctfbl: String = x.getField(5).toString val productNum: String = x.getField(6).toString val productUrl: String = x.getField(7).toString val productFrom: String = x.getField(8).toString val goodsStock: String = x.getField(9).toString val appraiseNum: String = x.getField(10).toString val rowkey = new Text(goodsId) val put = new Put(rowkey.getBytes) put.addColumn("f1".getBytes(), "goodsName".getBytes(), goodsName.getBytes()) put.addColumn("f1".getBytes(), "sellingPrice".getBytes(), sellingPrice.getBytes()) put.addColumn("f1".getBytes(), "productPic".getBytes(), productPic.getBytes()) put.addColumn("f1".getBytes(), "proudctBrand".getBytes(), proudctBrand.getBytes()) put.addColumn("f1".getBytes(), "proudctfbl".getBytes(), proudctfbl.getBytes()) put.addColumn("f1".getBytes(), "productNum".getBytes(), productNum.getBytes()) put.addColumn("f1".getBytes(), "productUrl".getBytes(), productUrl.getBytes()) put.addColumn("f1".getBytes(), "productFrom".getBytes(), productFrom.getBytes()) put.addColumn("f1".getBytes(), "goodsStock".getBytes(), goodsStock.getBytes()) put.addColumn("f1".getBytes(), "appraiseNum".getBytes(), appraiseNum.getBytes()) (rowkey, put.asInstanceOf[Mutation]) }) //将数据写入到hbase val configuration: Configuration = HBaseConfiguration.create() configuration.set(HConstants.ZOOKEEPER_QUORUM, "node01,node02,node03") configuration.set(HConstants.ZOOKEEPER_CLIENT_PORT, "2181") configuration.set(TableOutputFormat.OUTPUT_TABLE,"flink:data_goods") //mapreduce.output.fileoutputformat.outputdir configuration.set("mapred.output.dir","/tmp2") val job: Job = Job.getInstance(configuration) result.output(new HadoopOutputFormat[Text,Mutation](new TableOutputFormat[Text],job)) environment.execute("FullPullerGoods") } } - 增量拉取数据
- 我们可以通过maxwell来解析mysql的binlog实现数据增量的同步到kafka集群,但是还存在一个问题,就是同一条数据,如果先添加,后修改,再修改等操作,如何保证数据处理的顺序性?因为kafka当中的数据,在每个分区内部是有序的,但是全局处理无序,所以我们需要保证同一条数据一定要进入到同一个分区里面去。为了解决数据处理的顺序性问题,我们可以通过修改maxwell数据分区的规则来实现
-
第一步:创建kafka的topic以及Hbase表
# 创建topic cd /opt/install/kafka_2.11-1.1.0 bin/kafka-topics.sh --create --topic flink_house --replication-factor 1 --partitions 3 --zookeeper node01:2181 cd /kkb/install/hbase-1.2.0-cdh5.14.2 # 创建hbase表 bin/hbase shell create 'flink:data_orders',{NAME=>'f1',BLOCKCACHE=>true,BLOOMFILTER=>'ROW',DATA_BLOCK_ENCODING => 'PREFIX_TREE', BLOCKSIZE => '65536'} -
第二步:修改maxwell配置文件
cd /kkb/install/maxwell-1.21.1 vim config.properties producer_partition_by=primary_key kafka_partition_hash=murmur3 kafka_topic=flink_house -
第三步:启动maxwell
cd /opt/install/maxwell-1.21.1 bin/maxwell -
第四步:开发我们的数据解析程序(解析kafka当中的json格式的数据,然后入库hbase即可)
-
增量数据处理程序
import java.util.Properties import com.alibaba.fastjson.{JSON, JSONObject} import org.apache.flink.api.common.serialization.SimpleStringSchema import org.apache.flink.contrib.streaming.state.RocksDBStateBackend import org.apache.flink.streaming.api.CheckpointingMode import org.apache.flink.streaming.api.environment.CheckpointConfig import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011 object IncrementOrder { def main(args: Array[String]): Unit = { val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment //隐式转换 import org.apache.flink.api.scala._ //checkpoint配置 environment.enableCheckpointing(100); environment.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); environment.getCheckpointConfig.setMinPauseBetweenCheckpoints(500); environment.getCheckpointConfig.setCheckpointTimeout(60000); environment.getCheckpointConfig.setMaxConcurrentCheckpoints(1); environment.getCheckpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); environment.setStateBackend(new RocksDBStateBackend("hdfs://node01:8020/flink_kafka/checkpoints",true)); val props = new Properties props.put("bootstrap.servers", "node01:9092") props.put("zookeeper.connect", "node01:2181") props.put("group.id", "flinkHouseGroup") props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer") props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer") props.put("auto.offset.reset", "latest") props.put("flink.partition-discovery.interval-millis", "30000") val kafkaSource = new FlinkKafkaConsumer011[String]("flink_house",new SimpleStringSchema(),props) kafkaSource.setCommitOffsetsOnCheckpoints(true) //设置statebackend val result: DataStream[String] = environment.addSource(kafkaSource) val orderResult: DataStream[OrderObj] = result.map(x => { val jsonObj: JSONObject = JSON.parseObject(x) val database: AnyRef = jsonObj.get("database") val table: AnyRef = jsonObj.get("table") val `type`: AnyRef = jsonObj.get("type") val string: String = jsonObj.get("data").toString OrderObj(database.toString,table.toString,`type`.toString,string) }) orderResult.addSink(new HBaseSinkFunction) environment.execute() } } case class OrderObj(database:String,table:String,`type`:String,data:String) extends Serializable -
插入数据到hbase的程序
import com.alibaba.fastjson.{JSON, JSONObject} import org.apache.flink.configuration.Configuration import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction} import org.apache.hadoop.conf import org.apache.hadoop.hbase.{HBaseConfiguration, TableName} import org.apache.hadoop.hbase.client._ class HBaseSinkFunction extends RichSinkFunction[OrderObj]{ var connection:Connection = _ var hbTable:Table = _ override def open(parameters: Configuration): Unit = { val configuration: conf.Configuration = HBaseConfiguration.create() configuration.set("hbase.zookeeper.quorum", "node01,node02,node03") configuration.set("hbase.zookeeper.property.clientPort", "2181") connection = ConnectionFactory.createConnection(configuration) hbTable = connection.getTable(TableName.valueOf("flink:data_orders")) } override def close(): Unit = { if(null != hbTable){ hbTable.close() } if(null != connection){ connection.close() } } def insertHBase(hbTable: Table, orderObj: OrderObj) = { val database: String = orderObj.database val table: String = orderObj.table val value: String = orderObj.`type` val orderJson: JSONObject = JSON.parseObject(orderObj.data) val orderId: String = orderJson.get("orderId").toString val orderNo: String = orderJson.get("orderNo").toString val userId: String = orderJson.get("userId").toString val goodId: String = orderJson.get("goodId").toString val goodsMoney: String = orderJson.get("goodsMoney").toString val realTotalMoney: String = orderJson.get("realTotalMoney").toString val payFrom: String = orderJson.get("payFrom").toString val province: String = orderJson.get("province").toString val createTime: String = orderJson.get("createTime").toString val put = new Put(orderId.getBytes()) put.addColumn("f1".getBytes(),"orderNo".getBytes(),orderNo.getBytes()) put.addColumn("f1".getBytes(),"userId".getBytes(),userId.getBytes()) put.addColumn("f1".getBytes(),"goodId".getBytes(),goodId.getBytes()) put.addColumn("f1".getBytes(),"goodsMoney".getBytes(),goodsMoney.getBytes()) put.addColumn("f1".getBytes(),"realTotalMoney".getBytes(),realTotalMoney.getBytes()) put.addColumn("f1".getBytes(),"payFrom".getBytes(),payFrom.getBytes()) put.addColumn("f1".getBytes(),"province".getBytes(),province.getBytes()) put.addColumn("f1".getBytes(),"createTime".getBytes(),createTime.getBytes()) /* * * */ hbTable.put(put); } def deleteHBaseData(hbTable: Table, orderObj: OrderObj) = { val orderJson: JSONObject = JSON.parseObject(orderObj.data) val orderId: String = orderJson.get("orderId").toString val delete = new Delete(orderId.getBytes()) hbTable.delete(delete) } override def invoke(orderObj: OrderObj, context: SinkFunction.Context[_]): Unit = { val database: String = orderObj.database val table: String = orderObj.table val typeResult: String = orderObj.`type` if(database.equalsIgnoreCase("product") && table.equalsIgnoreCase("kaikeba_orders")){ if(typeResult.equalsIgnoreCase("insert")){ //插入hbase数据 insertHBase(hbTable,orderObj) }else if(typeResult.equalsIgnoreCase("update")){ //更新hbase数据 insertHBase(hbTable,orderObj) }else if(typeResult.equalsIgnoreCase("delete")){ //删除hbase数据 deleteHBaseData(hbTable,orderObj) } } } } -
第五步:启动订单生成程序
-
- 第一步:创建hbase商品表
5:对接bi系统
- 可以通过kylin、spark、flink等对接数据展示层的模块
