转载请注明出处:https://blog.csdn.net/l1028386804/article/details/80173778
一. Hive概述
1、为什么使用Hive
Hadoop生态系统的诞生为高效快速地处理大数据带来曙光,但是需要写MapReduce或者Spark任务,入门门槛较高,需要掌握一门编程语言例如Java或者Scala。
我们长久以来习惯于传统的关系型数据库,并且结构化查询语言(SQL)相对来说也比较容易学习,所以能否将类似于关系型数据库的架构应用到Hadoop文件系统,从而可以使用类SQL语言查询和操作数据呢?Hive应运而生。
Hive提供了一个被称为Hive查询语言(HQL)的SQL方言,来查询存储在Hadoop集群中的数据。Hive就相当于是Mysql,Mysql的底层存储引擎是InnoDB,而Hive的引擎就是Hadoop的MapReduce,或者Spark,Hive会将大多数的查询转换成MapReduce任务或者Spark任务,这样就巧妙地将传统SQL语言和Hadoop生态系统结合起来,使仅会SQL的人员就可以轻松编写数据分析任务。
2、Hive应用场景
首先了解一下Hive的特点,然后就能判断其应用场景了。
第一,Hive不是一个完整的数据库,它依托并受到HDFS的限制。其中最大的限制就是Hive不支持记录级别的更新、插入或者删除操作。
第二,Hadoop是一个面向批处理的系统,任务的启动需要消耗较长的时间,所以Hive查询延时比较严重。传统数据库秒级查询的任务在Hive中也需要执行较长的时间。
第三,Hive不支持事务。
综上所述,Hive不支持OLTP(On-Line Transaction Processing),而更接近成为一个OLAP(On-Line Analytical Processing)工具。而且仅仅是接近于OLAP,因为Hive的延时性,还没有满足OLAP中的“联机”部分。因此,Hive是最适合数据仓库应用程序的,不需要快速响应给出结果,可以对海量数据进行相关的静态数据分析,数据挖掘,然后形成决策意见或者报表等。
那么,如果用户需要对大规模数据使用OLTP功能又该如何处理呢?此时我们应该选择一个NoSQL数据库如HBase,这种数据库的特点就是随机查询速度快,可以满足实时查询的要求。
二、数据类型和文件格式
1、基本数据类型
Hive中的基本数据类型与Java中对应的类型一一对应,例如STRING就是对应Java中的String,BIGINT对应Java中的Long等。
2、集合数据类型
1.STRUCT
| 数据类型 | 长度 | 示例 |
|---|---|---|
| TINYINT | 1byte有符号整数 | 20 |
| SMALLINT | 2byte有符号整数 | 20 |
| INT | 4byte有符号整数 | 20 |
| BIGINT | 8byte有符号整数 | 20 |
| BOOLEAN | 布尔类型,true或false | TRUE |
| FLOAT | 单精度浮点数 | 3.1415926 |
| DOUBLE | 双精度浮点数 | 3.1415926 |
| STRING | 字符序列。可以指定字符集。可以使用单引号或双引号 | ‘hello world’,”你好世界” |
| TIMESTAMP | 整数,浮点数或字符串 | 1327882394(Unix新纪元秒) 1327882394.123456789(Unix新纪元秒并跟随有纳秒数) ’2012-02-03 12:34:56’(JDBC所兼容的 java.sql.Timestamp时间格式) |
| BINARY | 字节数组 | 可以包含任意字节 |
struct('John', 'Doe')
STRUCT数据类型和Java中的“对象”类似,可以通过“点”符号访问元素内容。例如,如果某个列name的数据类型是STRUCT {first STRING; last STRING} ,那么第一个元素可以通过 name.first 来引用
2.MAP
map('first', 'John', 'last', 'Doe')
MAP是一对键值对元组集合,使用数组表示法(例如[‘key’])可以访问元素。例如,如果某个列name的数据类型是MAP,其中键值对是’first’->’John’和’last’->’Doe’,那么可以通过 name[‘last’] 获取最后一个元素
3.ARRAY
array('John', 'Doe')
3、Hive文件的格式
传统关系型文件的格式是对外部隐藏的,而Hive文件存储的格式却是我们自定义的。
三、HQL常用操作
接下来会讲解Hive中数据库、表、分区等的一些基本知识和常用操作,也是我们最经常用到的内容。
1、数据库操作
1.查看所有数据库
show databases;
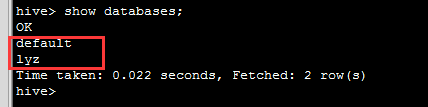
create database if not exists lyz;Hive数据库所在的目录位于属性 hive.metastore.warehouse.dir 所指定的顶层目录之后,这个配置的默认值是/user/hive/warehouse。Hive会为每个数据库创建一个目录,数据库中的表将会以这个数据库目录的子目录的形式存储。当我们创建arrival数据库时,Hive将会对应地创建一个目录/user/hive/warehouse/lyz.db,如图所示:

有一个例外就是default数据库中的表,因为这个数据库本身没有自己的目录。
用户还可以通过如下命令来修改这个默认的位置:
create database if not exists lyz location '/myown/dir';3.查看数据库信息
desc database lyz;

4.删除数据库
drop database if exists lyz;默认情况下,Hive不允许用户删除一个包含表的数据库。用户要么先删除数据库中的表,然后再删除数据库;要么在删除命令的最后加上关键字cascade,这样可以使Hive自行先删除数据库中表
drop database if exists lyz cascade;5.使用数据库
想要直接访问数据库中的表必须先指定数据库,否则需要加前缀,如lyz.table
use lyz;
2、表操作
1.创建表
CREATE TABLE IF NOT EXISTS lyz.employsalary (
name STRING COMMENT 'Employee name',
salary FLOAT COMMENT 'Employee salary',
subordinates ARRAY<STRING> COMMENT 'Names of subordinates',
deductions MAP<STRING, FLOAT>
COMMENT 'Keys are deductions names, values are percentages',
address STRUCT<street:STRING, city:STRING, state:STRING>
COMMENT 'Home address')
COMMENT 'Description of the table'
PARTITIONED BY (year STRING, month STRING)
ROW FORMAT
DELIMITED FIELDS TERMINATED BY '|'
COLLECTION ITEMS TERMINATED BY '\073'
MAP KEYS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE
LOCATION '/user/hive/warehouse/lyz.db/employsalary'
TBLPROPERTIES ('creator'='me', 'created_at'='2018-05-02 00:00:00');
首先,如果当前用户所处数据库并非是目标数据库,那么需要在表名前指定数据库,也就是例子中的lyz。 PARTITIONED BY是分区语句,这个后面详细讲。 ROW FORMAT后面的语句就是前面讲的文件中的内容如何分割。 STORED AS TEXTFILE意味着,所有字段都使用字母、数字、字符编码,包括那些国际字符集,而且每一行是一个单独的记录。 LOCATION '/user/hive/warehouse/lyz.db/employsalary'用来自定义表的位置,也可以不指明,此时就是默认位置/user/hive/warehouse/lyz.db/employsalary。 TBLPROPERTIES可以描述表的一些信息。
注意,我们此时创建的表是管理表,有时也称为内部表。因为这种表,Hive会控制着数据的生命周期,当删除一个管理表时,Hive也会删除表中的数据,而这往往是我们不愿意看到的,所以一般我们会创建外部表,就是在TABLE前面加上EXTERNAL关键字:
CREATE EXTERNAL TABLE IF NOT EXISTS lyz.employsalary ...
Hive删除外部表的时候不会删除表中的数据,只会删除表的元数据信息。
2.查看表信息
desc formatted employsalary_copy;
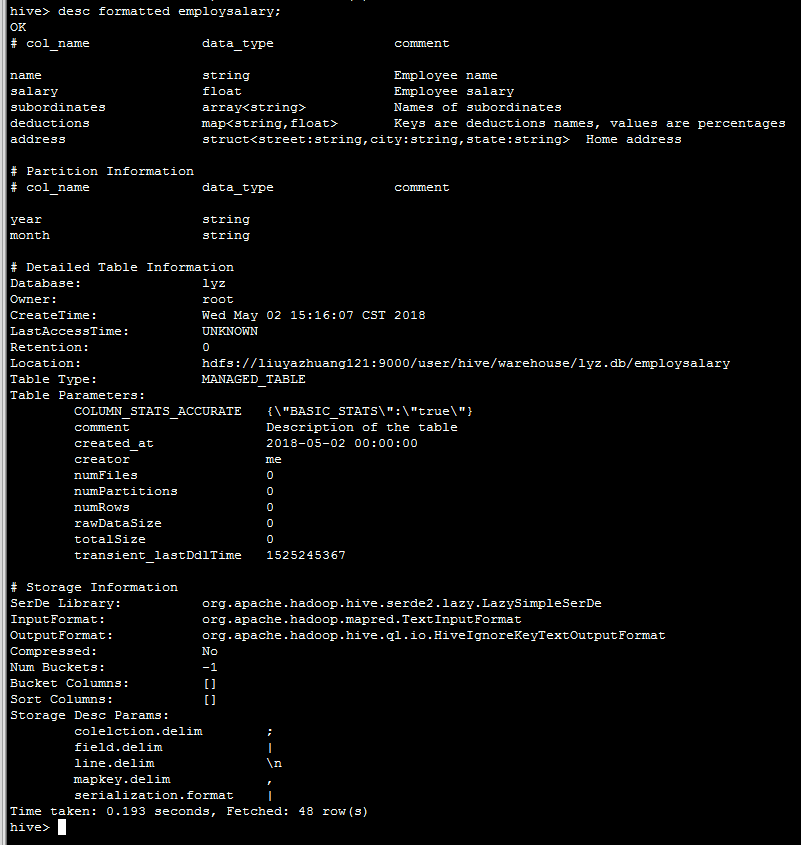
3.复制表
CREATE EXTERNAL TABLE IF NOT EXISTS lyz.employsalary_copy LIKE lyz.employsalary LOCATION '/user/hive/warehouse/lyz.db/employsalary_copy';4.删除表
drop table if exists employsalary;
5.通过查询语句向表中插入数据
前面说过Hive没有行级别的数据插入、更新和删除,那么如何往表中装载数据呢?一种方法是直接把文件放在表目录下面,另一种方式是查询一个已有表,将得到的结果数据插入一个新表,相当于从原有表提取数据到新表。
INSERT OVERWRITE TABLE employ PARTITION(year='2018', month='04') SELECT es.name, es.salary FROM employsalary es WHERE es.year='2018' and es.month='04';这里使用了OVERWRITE关键字,之前分区的内容将会被覆盖掉,如果不想被覆盖可以去掉该关键字或者使用INTO关键字。
还有一个问题,如果表很大分区很多,那每一次执行这个语句都要对表employsalary扫描一次,带来的消耗很大。Hive提供了另一种INSERT语法,可以只扫描一次输入数据,然后按多种方式进行划分。如下例子显示如何向表employ导入三个月的数据并且只扫描一次原表employsalary:
FROM employsalary es
INSERT OVERWRITE TABLE employ
PARTITION(year='2018', month='01')
SELECT es.name, es.salary WHERE es.year='2018' and es.month='01'
INSERT OVERWRITE TABLE employ
PARTITION(year='2018', month='02')
SELECT es.name, es.salary WHERE es.year='2018' and es.month='02'
INSERT OVERWRITE TABLE employ
PARTITION(year='2018', month='03')
SELECT es.name, es.salary WHERE es.year='2018' and es.month='03';
3、分区操作
分区的好处不言而喻,当查询的where字句加上分区过滤信息后,查询性能会极大提升,虽然可以没有分区,但由于Hadoop要处理的数据量都很大,所以尽量给表加上分区。而且分区的字段同时也是表中的字段,可以使用select语句查询出来
1.添加分区ALTER TABLE employsalary_copy ADD PARTITION(year='2018', month='05') LOCATION '/user/hive/warehouse/lyz.db/employsalary_copy/2018/05';2.查看分区
show partitions employsalary_copy;

3.修改分区
ALTER TABLE employsalary_copy PARTITION(year='2018', month='05') SET LOCATION '/user/hive/warehouse/lyz.db/employsalary_copy/2018/05';4.删除分区
ALTER TABLE employsalary_copy DROP IF EXISTS PARTITION(year='2018', month='05');对于管理表,即使是使用 ALTER TABLE … ADD PARTITION 语句增加的分区,分区内的数据也是会同时和元数据信息一起被删除的。对于外部表,分区内数据不会被删除。