首先我们先看看数据吧
数据是最近按周期爬取的, 有效数据18000
 目的: 我们的目的是要知道关于Python就业有哪些需要用到的技术, 比如说后端是Flask用的多还是Django或者Tornado用的比较多, 深度学习框架是TensorFlow用的多还是caffe或是Mxnet等等…
目的: 我们的目的是要知道关于Python就业有哪些需要用到的技术, 比如说后端是Flask用的多还是Django或者Tornado用的比较多, 深度学习框架是TensorFlow用的多还是caffe或是Mxnet等等…
首先我们要构造分词字典
ls_add = ['SQL', 'C++', 'HADOOP', 'JAVA', 'R', 'SAS', 'SPARK', 'HIVE', 'ABTEST',
'MYSQL', 'MATLAB', 'FLASK', 'REDIS', 'MONGODB', 'DJANGO', 'TENSORFLOW', 'CAFFE',
'MXNET', 'KERAS', 'SELENIUM', 'APPIUM', 'NUMPY', 'REQUEST', 'HTML',
'CSS', 'SCRAPY', 'JAVASCRIPT', 'NGINX', 'SOCKETNODEJS', 'APACHE',
'PANDAS', 'MATPLOTLIB', 'VUE', 'WEBMAGIC', 'NUTCH', 'HERITRIX', 'LINUX',
'CENTOS', 'UBUNTU', '机器学习', '深度学习', 'MEMCACHE', 'GIT', 'SVN', 'TORNADO', 'UNIX',
'ORACLE', 'DOCKER', 'CODEREVIEW', 'ABACONDA', '后端', '测试', 'SQLALCHEMY', 'RABBITMQ',
'DB2', 'TOMCAT', 'SCRUM', 'POSTGRESQL', 'SWARM', 'KUBERNETES', '推荐系统', '用户画像',
'人工智能', 'CELERY', 'JSON', 'SHELL', 'HBASE', 'KAFKA', 'XPATH', 'REQUESTS',
'BOOTSTRAP', 'HTTP', 'TCP', 'UDP', 'HTTPS', '数据分析', '数据挖掘', 'UNITTEST',
"JWT", "GO", "OCTAVE", "爬虫"]
然后进行分词处理(这里我直接上封装好的代码了)
import re
import jieba
import pandas as pd
class DataAnalyze(object):
def __init__(self):
self.data = pd.read_csv("E:\\数据集\\招聘信息数据\\9月19\\test1.csv")
self.data.dropna()
self.data = self.data.dropna(axis=0)
self.ls_add = ['SQL', 'C++', 'HADOOP', 'JAVA', 'R', 'SAS', 'SPARK', 'HIVE', 'ABTEST',
'MYSQL', 'MATLAB', 'FLASK', 'REDIS', 'MONGODB', 'DJANGO', 'TENSORFLOW', 'CAFFE',
'MXNET', 'KERAS', 'SELENIUM', 'APPIUM', 'NUMPY', 'REQUEST', 'HTML',
'CSS', 'SCRAPY', 'JAVASCRIPT', 'NGINX', 'SOCKETNODEJS', 'APACHE',
'PANDAS', 'MATPLOTLIB', 'VUE', 'WEBMAGIC', 'NUTCH', 'HERITRIX', 'LINUX',
'CENTOS', 'UBUNTU', '机器学习', '深度学习', 'MEMCACHE', 'GIT', 'SVN', 'TORNADO', 'UNIX',
'ORACLE', 'DOCKER', 'CODEREVIEW', 'ABACONDA', '后端', '测试', 'SQLALCHEMY', 'RABBITMQ',
'DB2', 'TOMCAT', 'SCRUM', 'POSTGRESQL', 'SWARM', 'KUBERNETES', '推荐系统', '用户画像',
'人工智能', 'CELERY', 'JSON', 'SHELL', 'HBASE', 'KAFKA', 'XPATH', 'REQUESTS',
'BOOTSTRAP', 'HTTP', 'TCP', 'UDP', 'HTTPS', '数据分析', '数据挖掘', 'UNITTEST',
"JWT", "GO", "OCTAVE", "爬虫"]
@staticmethod
def find_kind(data):
"""
传进来技术点 返回类别
:param data: 技术点
:return: 所属类别
"""
kinds = [{"操作系统": ["LINUX", "CENTOS", "UBUNTU", "UNIX"]},
{"语言相关": ["C++", "JAVA", "GO", "SQL", "R", "JAVASCRIPT", "SHELL"]},
{"大数据": ["HADOOP", "SAS", "SPARK", "HIVE", "ABTEST", "KAFKA"]},
{"数据库": ["ORACLE", "MYSQL", "REDIS", "MONGODB", "DB2", "HBASE", "POSTGRESQL"]},
{"后端相关": ["FLASK", "DJANGO", "TORNADO", "APACHE", "TOMCAT", "SQLALCHEMY"]},
{"数据科学": ["TENSORFLOW", "CAFFE", "MXNET", "KERAS", "NUMPY", "PANDAS", "MATLAB", "MATPLOTLIB"]},
{"自动化测试": ["SELENIUM", "APPIUM", "UNITTEST"]},
{"前端相关": ["REQUEST", "HTML", "CSS", "NODEJS", "VUE", "JSON", "BOOTSTRAP"]},
{"爬虫框架": ["SCRAPY", "XPATH", "REQUESTS", "WEBMAGIC", "NUTCH", "HERITRIX", "JWT"]},
{"分布式相关": ["NGINX", "Celery", "MEMCACHE", "RABBITMQ", "SWARM"]},
{"通信协议": ["TCP", "UDP", "HTTP", "HTTPS"]},
{"版本控制": ["GIT", "SVN", "ABACONDA"]},
{"热门技术": ["后端", "测试", "爬虫", "数据分析", "数据挖掘", "人工智能"]},
{"人工智能": ["机器学习", "深度学习", "推荐系统", "用户画像"]}
]
kind = None
for _dict in kinds:
for x, y in _dict.items():
if data in y:
kind = x
break
if kind is None:
kind = "其他"
return kind
@staticmethod
def data_clear(data):
"""
清洗数据
:param data:
:return: 处理后的数据
"""
t = "".join(data['content'].tolist())
t = t.upper()
# pattern = re.compile(r'\d[.|\.|、]')
pattern1 = re.compile(r'\s')
# t = re.sub(pattern, '', t)
t = re.sub(pattern1, '', t)
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~【】◆,;、。()':
t = t.replace(ch, "")
t = t.replace('\xa0', '')
words = jieba.lcut(t)
counts = {}
for word in words:
counts[word] = counts.get(word, 0) + 1
return counts
def update_dict(self):
"""
更新词库
:return:
"""
for i in self.ls_add:
jieba.add_word(i)
def extract_run(self):
"""
提取数据
:return: 提取后的数据 pandas.DataFrame类型
"""
temp_data = list()
self.update_dict()
for x, y in self.data_clear(self.data).items():
if x in self.ls_add:
if x == "测试": # 测试工程师简介重复率比较高导致数据不准确直接取一半
y = y / 2
temp_data.append([x.lower().title(), y, self.find_kind(x.upper())])
_data = pd.DataFrame(temp_data, columns=["title", "num", "kind"])
_data.to_csv("9-2_.csv", encoding="utf_8_sig")
return _data
if __name__ == '__main__':
D = DataAnalyze()
data_ = D.extract_run()
程序会自动生成一个文件
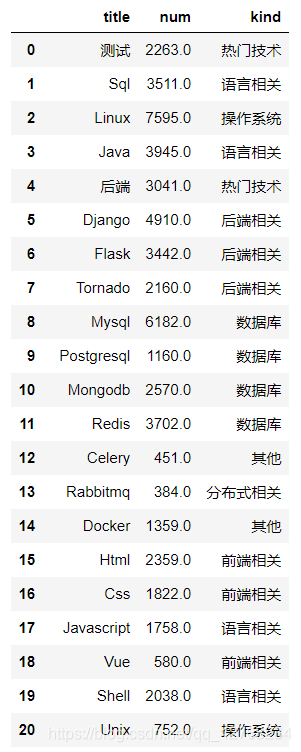
数据已经处理完成接下来就是可视化了(先看看效果)
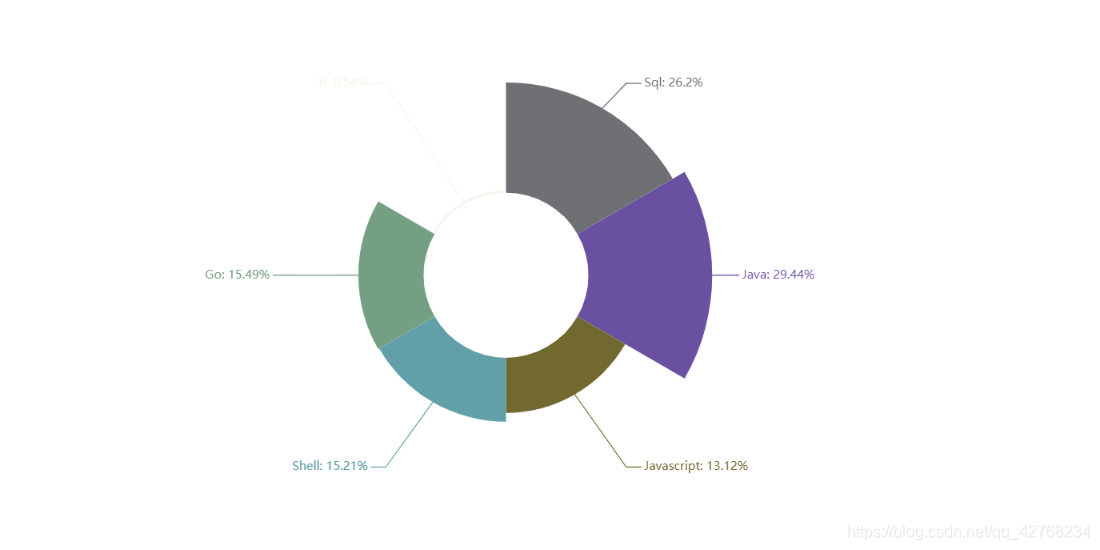
- 我们看到招聘中常常要求我们在熟练使用Python还需要SQL Java等

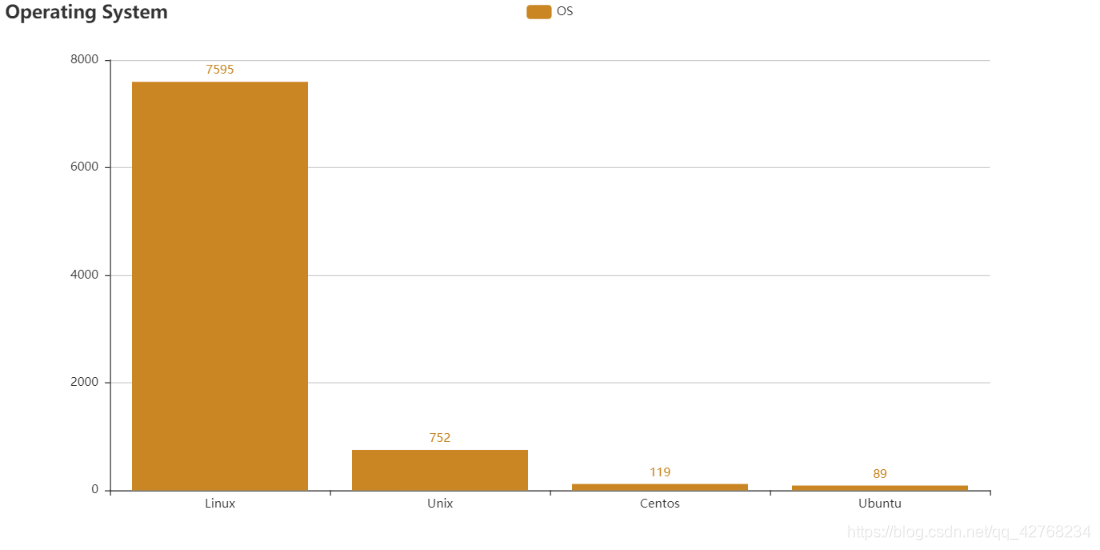
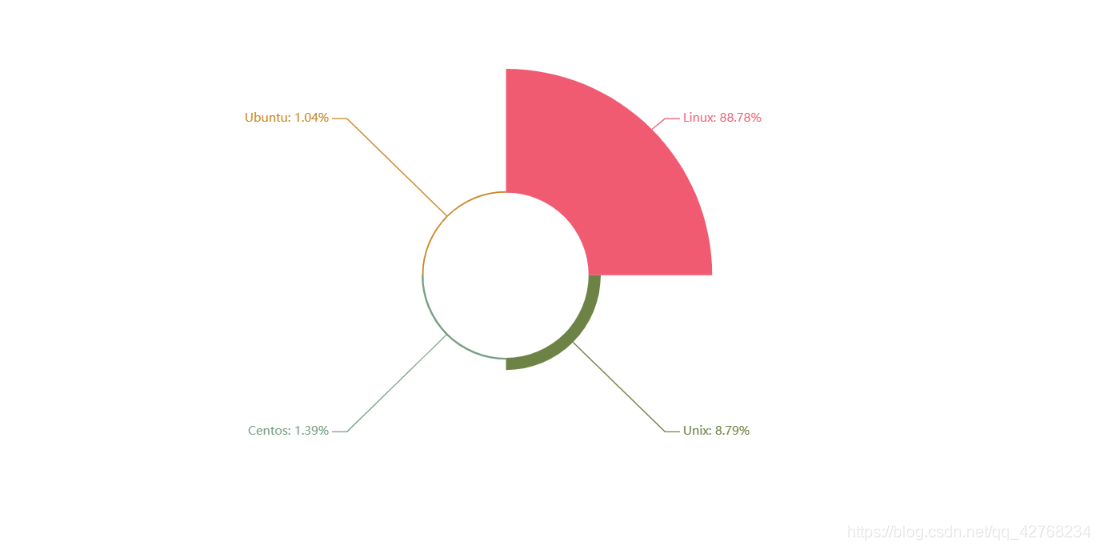
- 操作系统热度, 看来主流还是Linux(ubantu归类错了)
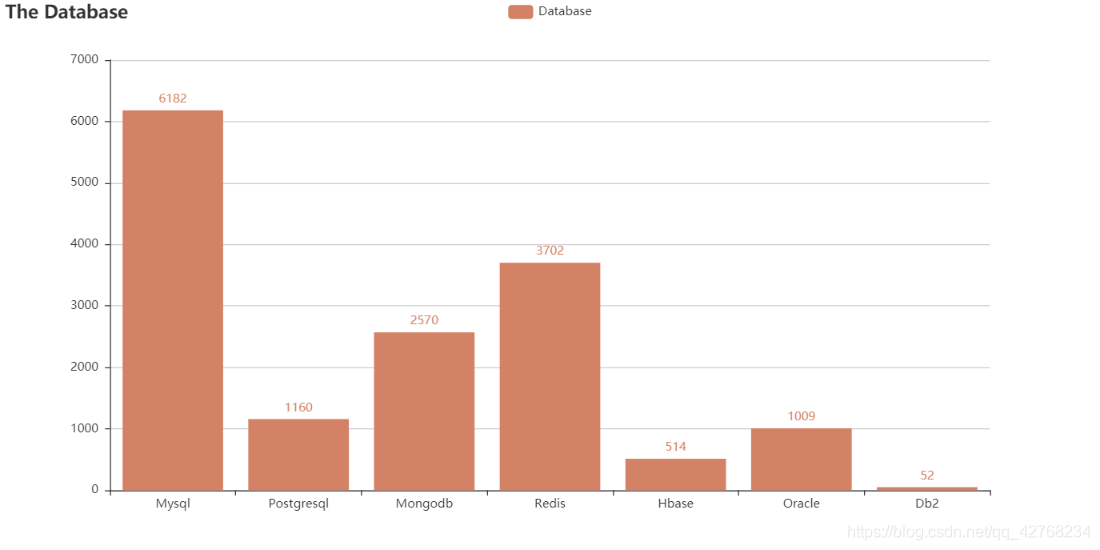
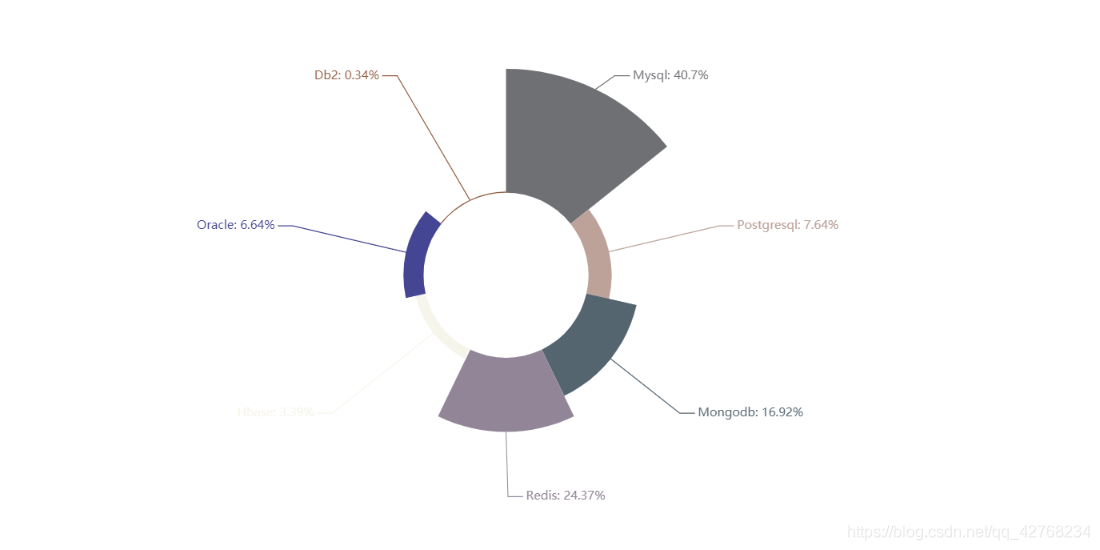
- 数据库热度
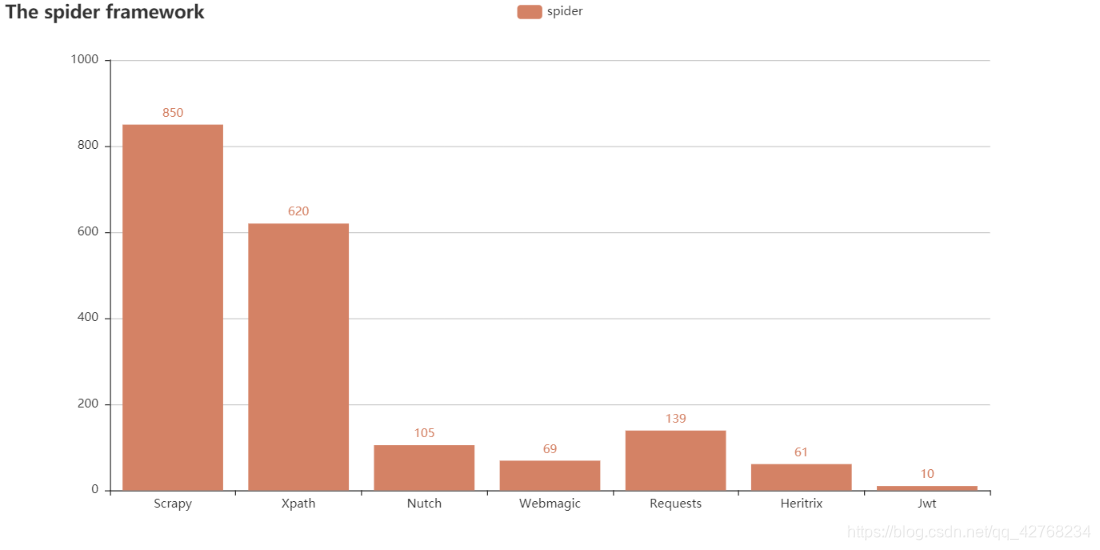
- 爬虫热门框架
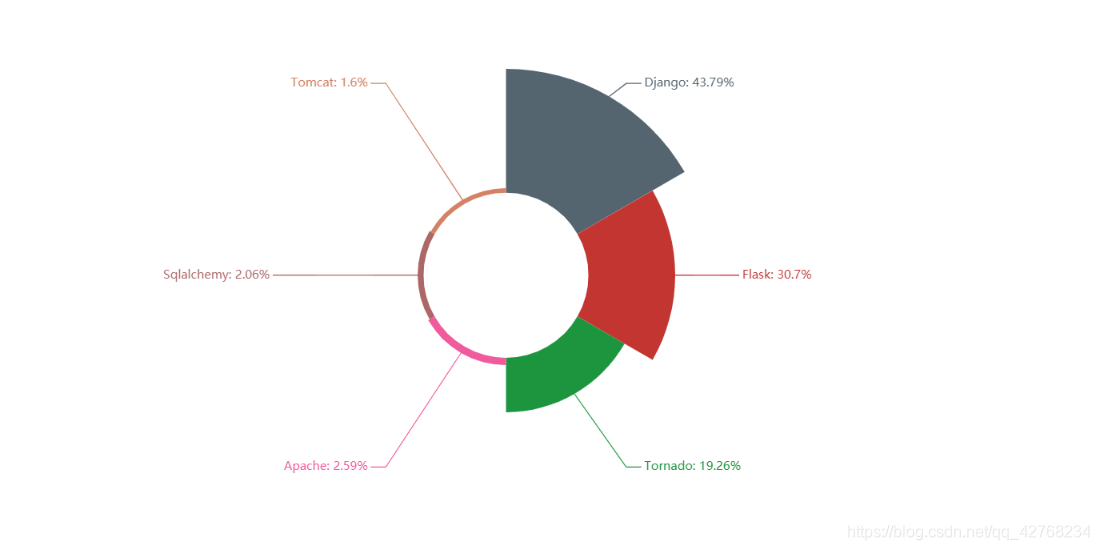
- 通信协议
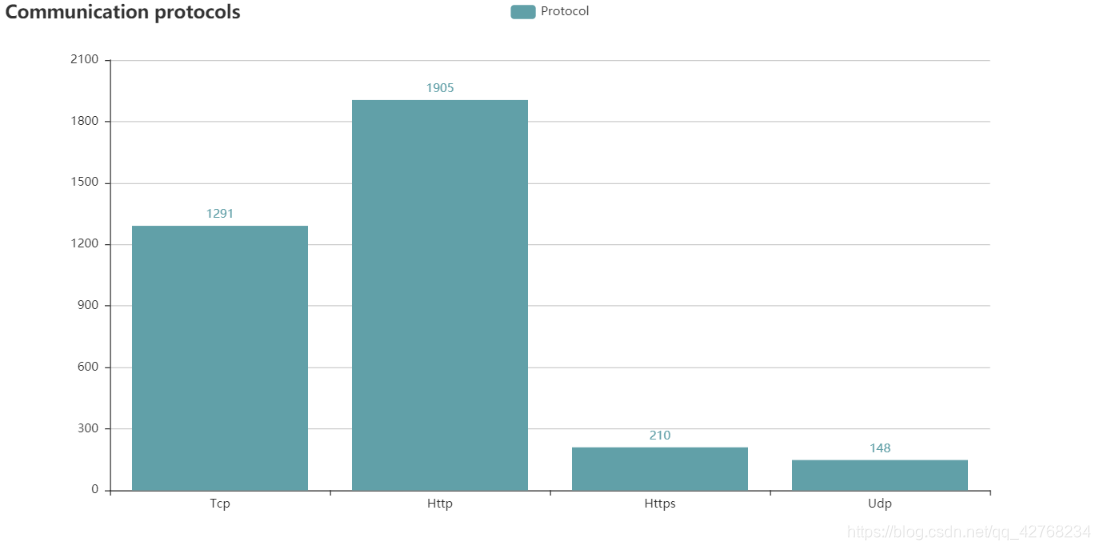
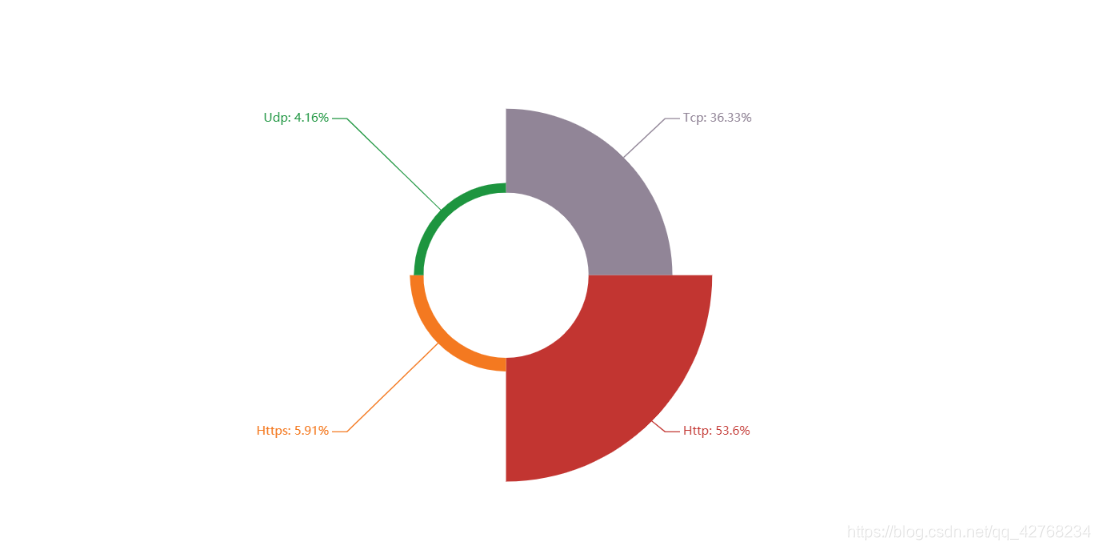
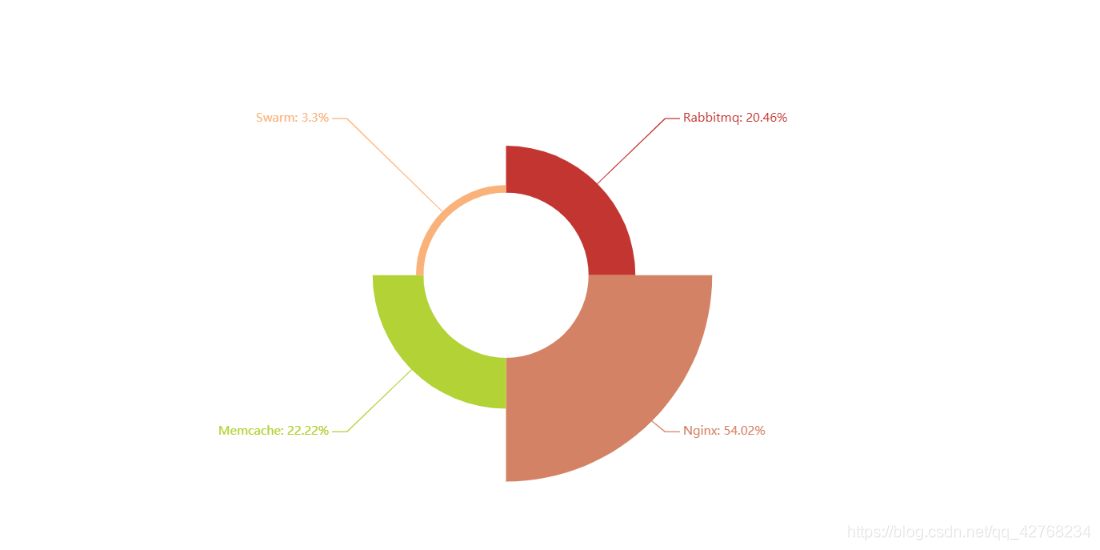
- 分布式相关(Nginx这么热)
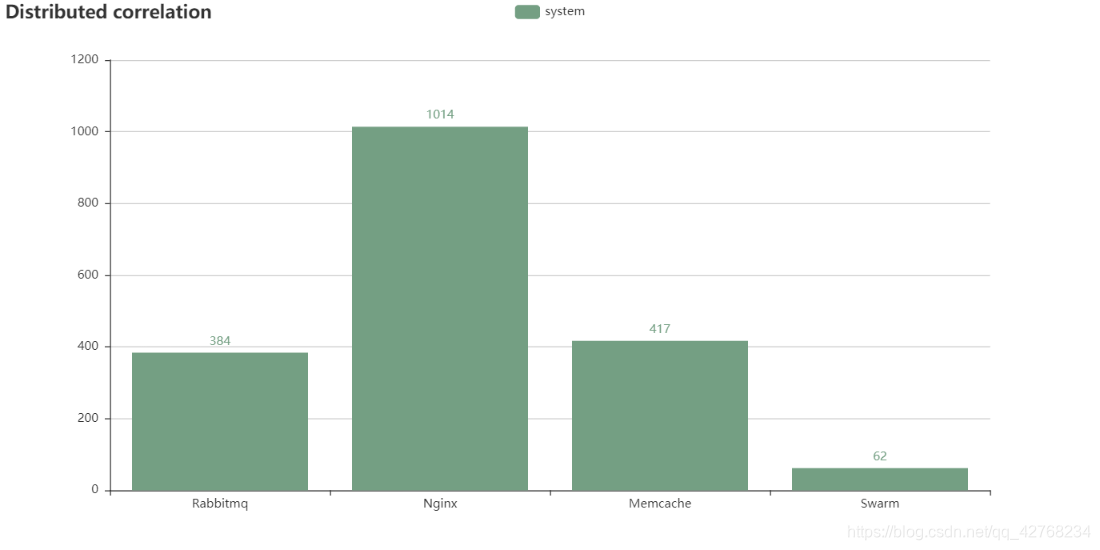
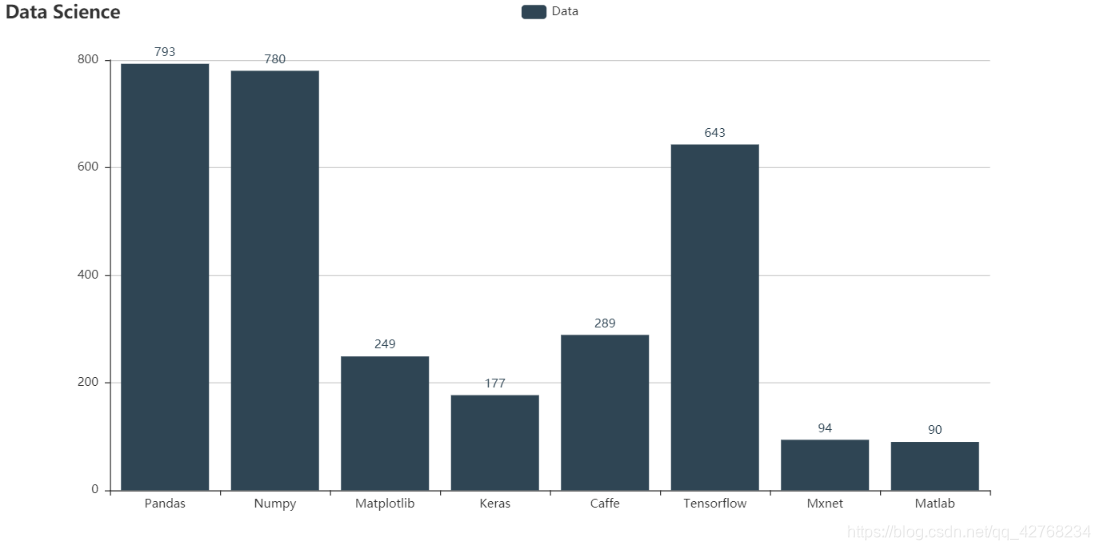
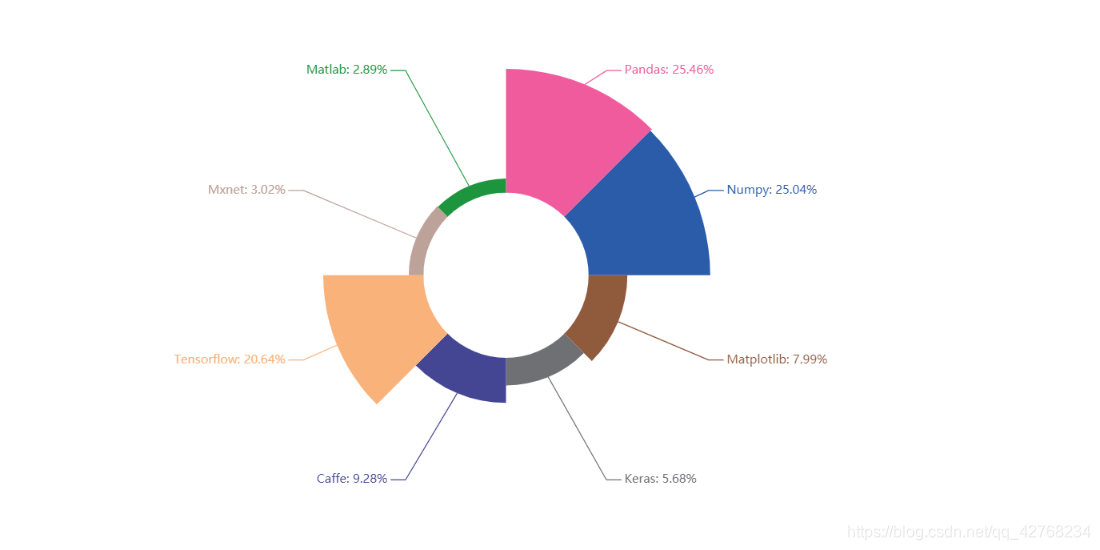
- 数据科学相关及深度学习框架
- 词云图(新加的)

