Paxos & Zookeeper ZAB协议
小灰灰上一篇博客简单介绍了2PC和3PC分布式系统一致性协议(https://blog.csdn.net/yangchenhui666/article/details/98512432) ,但是最重要的分布式一致性协议还是Paxos协议。
Zookeeper中使用的ZAB协议就是Paxos的一个变种协议。
1、Paxos
在分布式系统当中,比较简单的解决分布式一致性问题的方式可以有两种:
1、通过共享内存做到数据一致性,类似与cpu的实现方式;
2、通过主从节点方式实现,只有Leader节点能够进行写操作,其余节点只能够进行读操作,从节点上面收到的写操作都要转发到主节点上面进行。
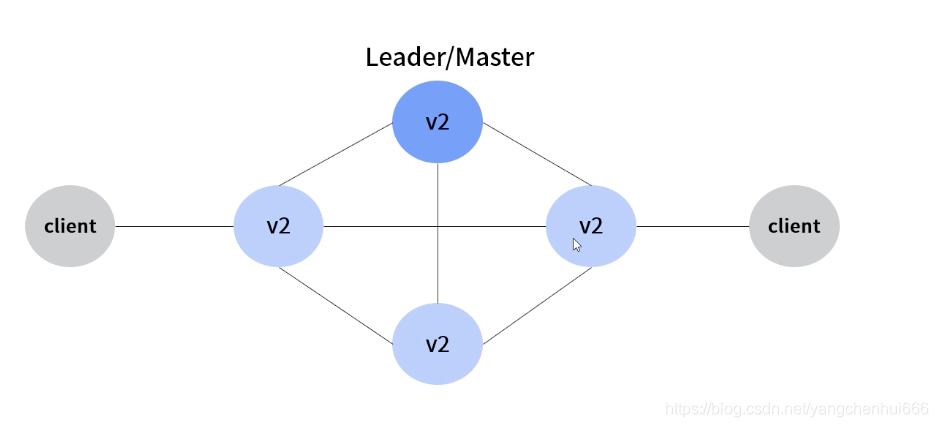
但是主从模式会有很大的中心化问题,如果Leader节点出现单点故障,那么将会导致整个集群不可用,所以去中心化就显得尤为重要,此时Paxos算法就应运而生。
Paxos算法的数学证明很复杂,有兴趣的同学可以查看下,下面对Paxos算法的过程做简要说明。
http://lamport.azurewebsites.net/pubs/lamport-paxos.pdf
http://lamport.azurewebsites.net/pubs/paxos-simple.pdf
Paxos算法是莱斯利·兰伯特(英语:Leslie Lamport,LaTeX中的“La”)于1990年提出的一种基于消息传递且具有高度容错特性的一致性算法。
1.1、Paxos中的角色
- Proposer:提议者,负责提议,提出希望达成一致的value提案
- Acceptor:接收者,负责对提案进行投票,决定是否接受此value提案
- Learner:学习者,不参与投票,只是被动的学习已经决定的提案
在分布式系统中,如果网络节点太多,那么并不需要所有的节点都参与投票,这样可以节约系统资源。同时一个网络节点既可以是提议者,也可以是接收者(自己可以为自己提出的提案进行投票)。
1.2、Paxos基本定义
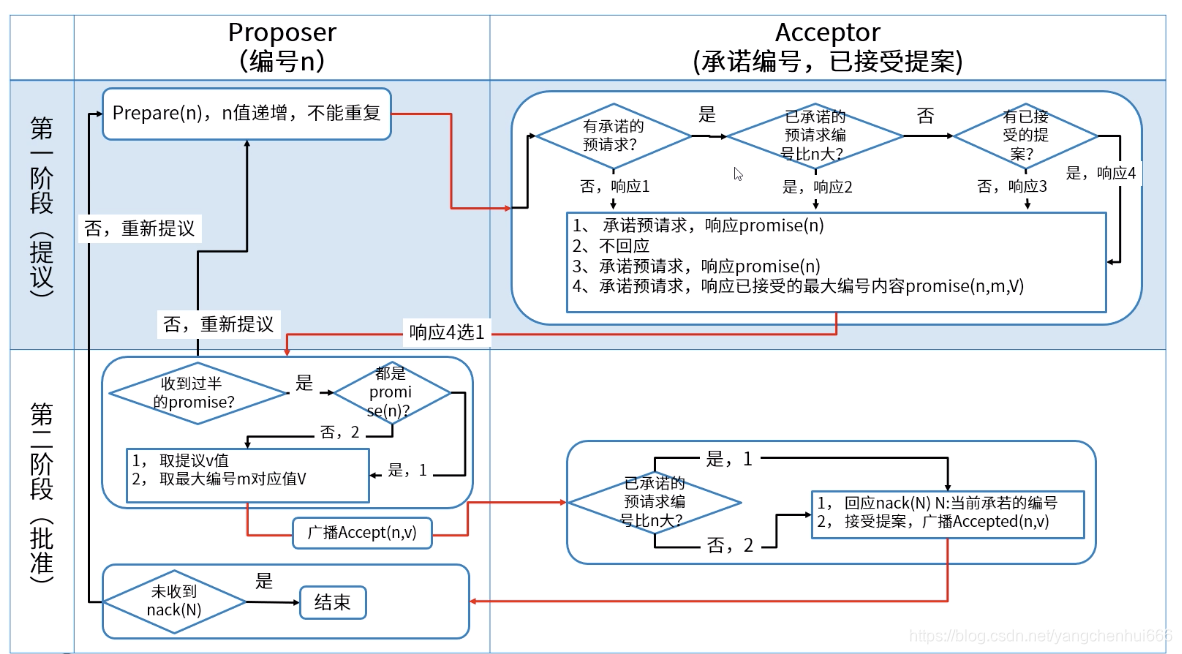
Paxos分为两个阶段,第一个阶段为提议阶段,第二个阶段为批准阶段。
I、投票阶段
提案由以下两个部分组成:
- 提案编号:所有节点当中的编号n是唯一的,同时保证全局递增,通过提案编号体现提案的先后顺序。
- 更新值:提案的更新值,请求更新的值
提议阶段主要操作如下:
- 提议者提出提案给接收者;
- 接收者如果同意该提案,响应promise响应,并不再接受比当前提案号更低的提案;
- 提议者接收到超过半数的promise响应,进入下一阶段,否则重新提案;
II、提交阶段
提议者接收到超过半数promise响应,进入提交阶段,主要操作如下:
- 提议者向接收者返送accept消息
- 接收者比较自己当前promise的提案号,如果accept比当前promise的提案号低,则响应Nack(当前提案号),否则Accept,广播Accepted
通过下图,我们可以看到整个Paxos算法执行过程。
1.3、Paxos示例
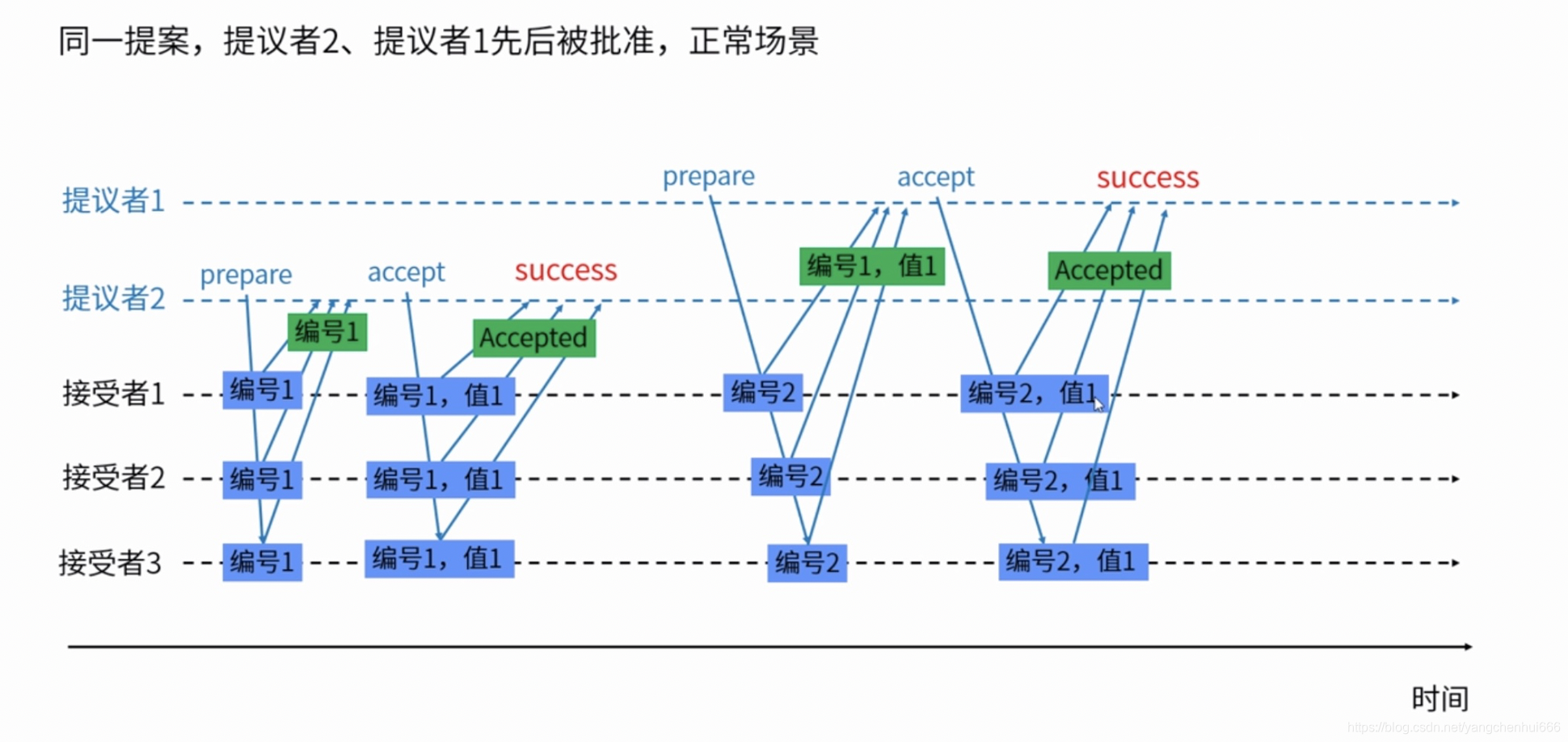
通过下面两个图,我们了解下具体的Paxos算法执行过程
1、正常场景
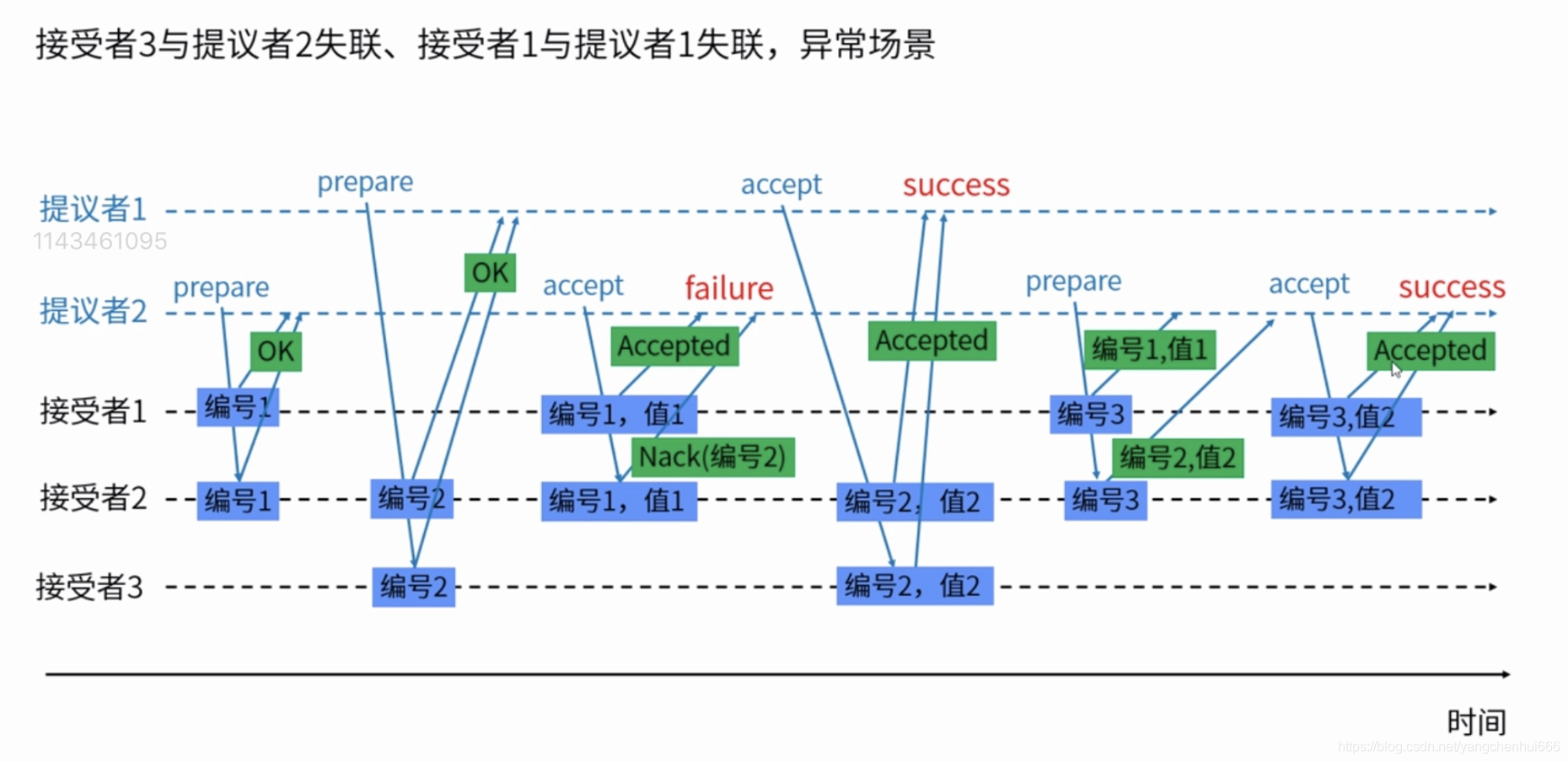
2、异常场景
2、ZAB
ZAB(Zookeeper Automatic Broadcast)是zookeeper原子消息广播协议,是zookeeper数据一致性的核心算法。
ZAB定义了那些会改变zookeeper服务器数据状态的事务请求的处理方式,具体描述如下:
所有的事务必须由已全局唯一的服务器来协调处理,这样的服务器被称之为leader服务器,其他的服务器都称之为follower服务器。
leader:将客户端的请求转化为事务proposal(提议),同时将proposal分发到follower服务器。
follower:接受proposal并进行投票响应
如果leader服务接收到过半的follower响应请求,leader将会向所有follower发送commit消息,要求follower将前一个proposal提交。
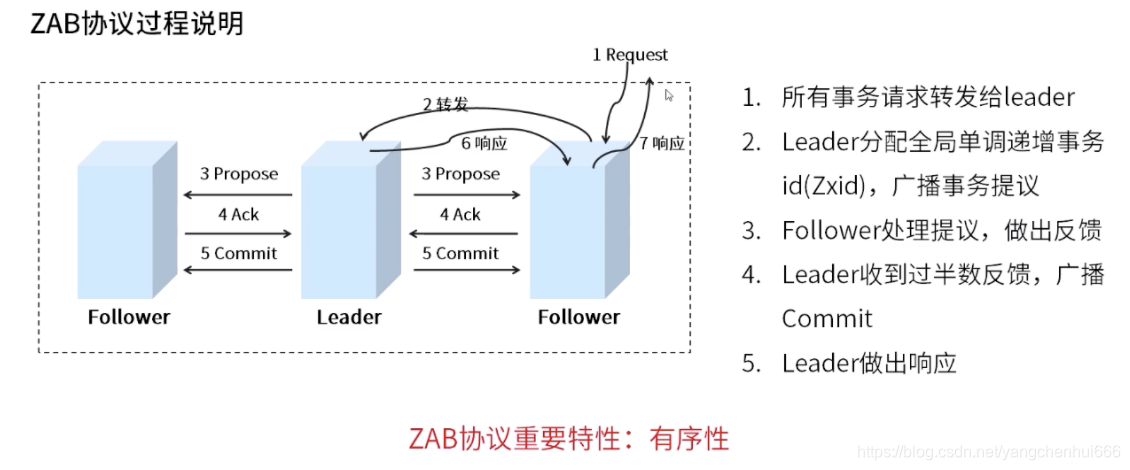
2.1、协议介绍
ZAB协议包含两个部分:崩溃恢复和消息广播。
当zookeeper集群启动或者是当leader服务器出现崩溃退出,断网或者是重启的时候等异常情况时,ZAB协议就会进入恢复模式,经过leader选举的过程产生新的leader,并当集群中超过半数的follower完成状态(follower同步leader的节点数据)同步之后,ZAB协议就会退出恢复模式。
超过半数follower完成状态同步,ZAB协议进入消息广播模式。此时如果有新的节点加入集群,发现已经存在了leader服务器,将会自动进入恢复模式,同步leader的节点数据,完成数据同步后进入消息广播模式。
在整个zookeeper集群工作的过程中,可能会产生多个leader服务器,同一个zookeeper节点可能会多次充当leader角色。
进入崩溃恢复模式的过程中,必须有超过半数的节点能够正常通信,否则将无法选举出leader节点。
2.2、崩溃恢复
在zookeeper集群运行过程中,有以下情况会进入崩溃恢复模式:
1、leader服务器故障
2、leader服务器失去了与过半follower的联系
ZAB崩溃恢复中重新产生leader的算法称为“leader选举算法”,算法需要保证leader和follower都能够快速感知到是哪个节点成为了leader。
ZAB协议规定如果一个事务proposal在一个节点上处理成功,那么应该在所有的节点都处理成功,即使节点出现故障崩溃,也需要处理成功。即:
I、ZAB协议需要保证已经在leader上提交的事务最终被所有服务器都提交
假设一个事务已经在leader服务器上面提交,并且leader服务器已经收到超过半数的follower的ack响应,但是当leader服务器发出Commit指令前,leader服务挂掉,如下图所示:
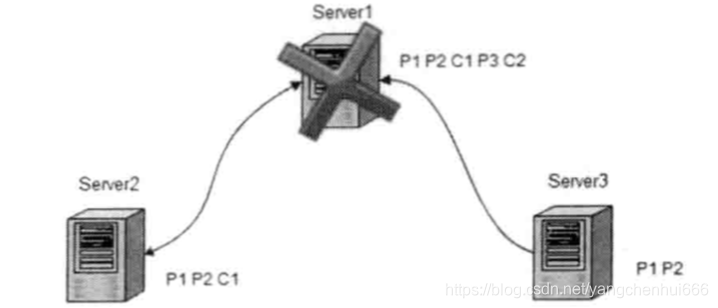
在集群正常运行的时候,server1为leader,先后分别广播消息 P1、P2、C1、P3、C2,但是当server1准备广播提交事务P2时,即广播消息C2时,leader发生崩溃并退出。此时ZAB协议需要保证事务proposal2最终能够在所有的节点上进行提交,才能够保证数据的一致性。
II、ZAB协议需要确保丢弃那些只在leader服务器上提出的事务
如果一个事务只在leader节点上提出,但是并没有到达其他follower节点,此时这个proposal事务就是应该被丢弃的。如下图所示:
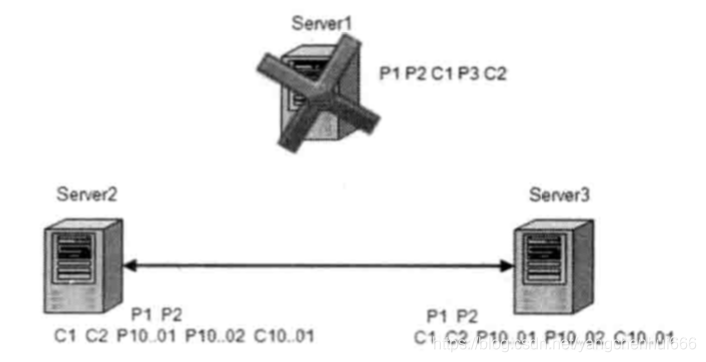
在集群正常运行时,server1作为leader角色,但是当server1提出P3之后就崩溃退出,导致其他节点都没有接收到P3。如果server1重启后加入到zookeeper集群中,P3就是需要被丢弃的proposal事务。
为了满足上面两种情况,ZAB协议是这样设计leader选举算法的:
新leader具有集群中所有机器最高ZXID的事务proposal ===> 保证新leader一定具有所有已经提交的提案(因为zookeeper是严格顺序执行的,所以具有了最高的ZXID,之前的肯定都存在)
让拥有最高编号事务proposal的机器称为leader ===> 可以省去leader节点检查proposal的提交和丢弃的操作(自己的就是最全的)
2.3、数据同步
在新的leader选举出来之后,还需要超过半数的follower完成与leader的数据同步才能够对外提供服务。同步的具体过程如下:
- leader为每个follower分配一个队列,将需要同步的proposal存在队列中,逐个发送到follower节点,并在每个proposal后都发送commit指令,让follower提交该指令
- follower同步完proposal,存入到节点内存中后,leader会将该follower加入到真正可用follower列表中
ZAB协议事务编号ZXID是64位数字,设计如下:
- 低32位:单调自增id,针对客户端的每个请求,leader产生新的proposal时,都会对其+1
- 高32位:leader周期纪元编号,没新产生一个leader,都会对周期纪元+1,并将低32位计数器清零
这样设计就不会出现不同的leader使用相同的ZXID提交不同的proposal,同时如果某个节点包含上一个leader周期纪元的编号,肯定无法成为leader,因为当前集群节点中肯定还有更高leader周期纪元的事务proposal。当该节点加入到集群中时,将会以follower的身份进行数据同步,对比的时候,leader会要求该follower进行回退操作,回退到最新的已经在过半节点中提交的最新的proposal状态,即在上图中的server1连接上leader后,leader会要求server1去除P3。
关于zookeeper的ZAB算法的推导证明还是比较复杂的,想要了解的朋友可以去看《从Paxos到Zookeeper 分布式一致性原理与实践》。
2.4、ZAB示例
我们先了解在leader选举算法中的下列概念:
- 服务器id:myid
- 事务id:服务器中存放的最大ZXID
- 逻辑时钟:发起的投票轮次计数
- 选举状态:
LOOKING,竞选状态
FOLLOWING,随从状态,同步leader状态,参与投票
OBSERVING,观察状态,同步leader状态,不参与投票(在zookeeper集群数量很大的时候,不需要所有的节点都参加竞选)
LEADING,领导者状态
选举规则:
先比较ZXID,如果收到的投票信息ZXID比自己的大,投票认同,如果小于自己的ZXID,保持自己的投票信息,如果ZXID相等,比较myid,如果接收到的投票信息myid比自己的大,投票认同,反之保持自己的投票信息。
下图为《从Paxos到Zookeeper 分布式一致性原理与实践》中的描述:
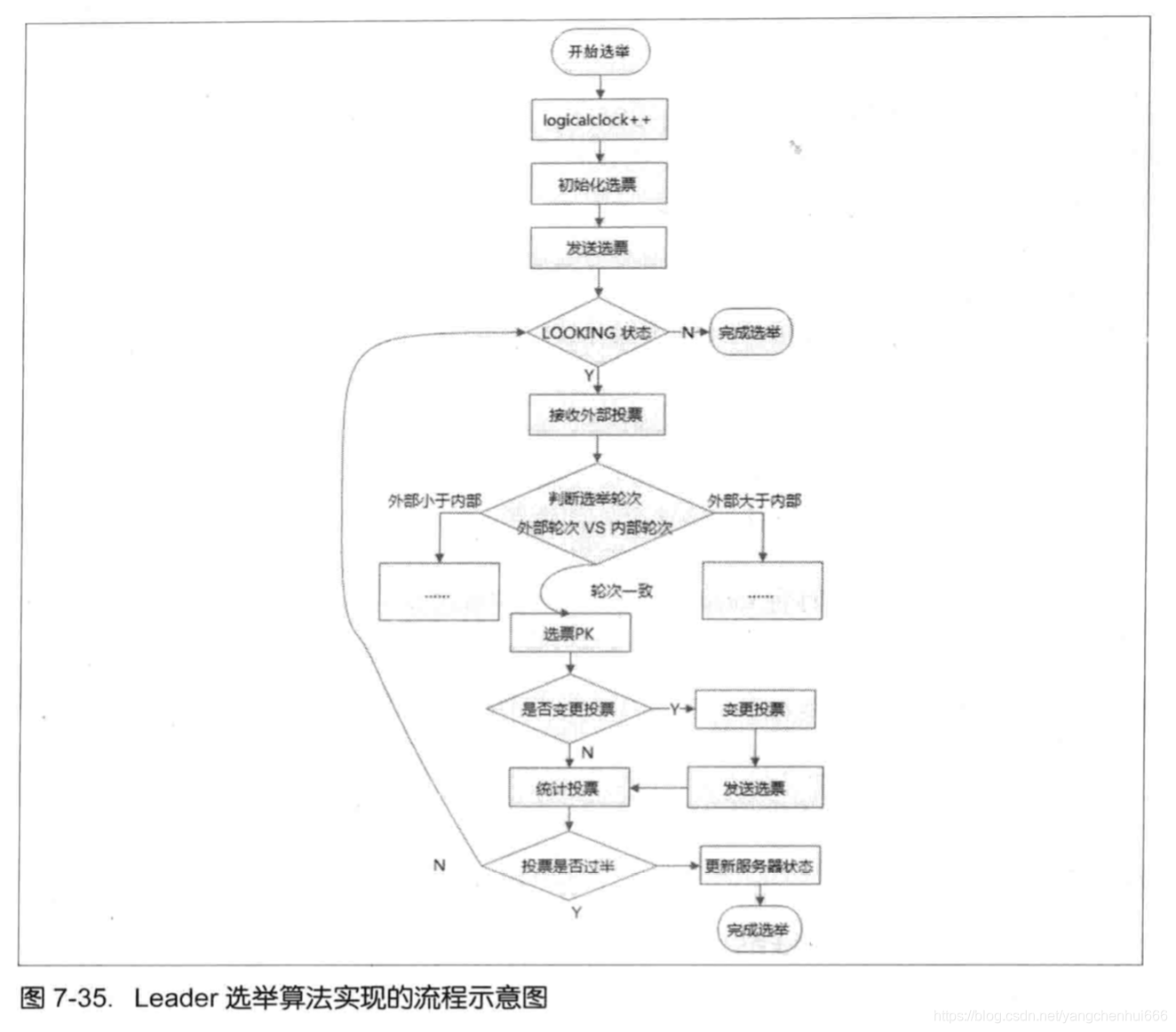
启动时:
目前有5台服务器,每台服务器均没有数据,它们的编号分别是1,2,3,4,5,按编号依次启动,它们的选择举过程如下:
- 服务器1启动,给自己投票,然后发投票信息,由于其它机器还没有启动所以它收不到反馈信息,服务器1的状态一直属于Looking(选举状态)。
- 服务器2启动,给自己投票,同时与之前启动的服务器1交换结果,由于服务器2的编号大所以服务器2胜出,但此时投票数没有大于半数,所以两个服务器的状态依然是LOOKING。
- 服务器3启动,给自己投票,同时与之前启动的服务器1,2交换信息,由于服务器3的编号最大所以服务器3胜出,此时投票数正好大于半数,所以服务器3成为领导者,服务器1,2成为小弟。
- 服务器4启动,给自己投票,同时与之前启动的服务器1,2,3交换信息,尽管服务器4的编号大,但之前服务器3已经胜出,所以服务器4只能成为小弟。
- 服务器5启动,后面的逻辑同服务器4成为小弟。
运行时重新选举leader:
我们通过下图可以了解到在zookeeper集群运行状态下,重新进行leader选举的过程:

小结
通过对Paxos和ZAB的学习,可以了解到两者之间的一些联系和区别。
- 都会要求过半数通过才能够变更集群节点数据
- 都有类似ZXID的设计
但是在Paxos的基础上,ZAB额外添加了数据同步的过程,同时两者的设计目标也不太一致,ZAB协议主要用于构建一个高可用的分布式数据主备系统,而Paxos算法侧重于构建一个分布式的一致性状态系统。
