1.ZAB协议的核心
在一个zk集群中,只有一个leader节点可以将客户端的写请求转化为事务或提议proposal,leader节点写完数据库,
把proposal消息发送到leader和follower直接的通信队列中去,follower节点处理完leader节点发送的proposal消息后,
给leader节点返回ACK消息确认,当leader节点接收到半数以上的follower返回的ACK消息后,leader节点就向所有的
follower节点发送commit消息。
2.ZAB协议的两种模式
1.崩溃恢复模式
2.消息广播模式
3.zookeeper 中的ZXID
1.为了保证zookeeper事务的顺序一致性,zxid采用的时递增的事id(zxid)来标识事务
2.zxid有64位组成
---高32位是epoch编号(用来标识leader的周期变化,即每次新选举出leader,epoch编号自动加1)
---低32位用于递增计数 (每次新选出leader时,清零)
4.崩溃恢复模式
1.崩溃恢复模式需要解决两个问题
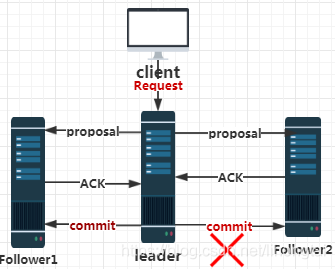
A:已经被处理的消息不能丢失-产生的原因如下图所示
当leader节点在向follower节点发送commit消息的时候,只有follower1 消息发送成功后,leader节点直接崩溃,
还没有向follower2节点发送commit消息。
也就是说当zk集群恢复使用(选出新的leader)后,老leader节点最后提交到follower1节点的消息不能丢失
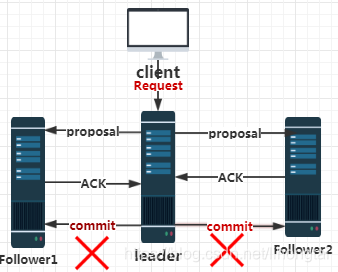
B:被丢弃的消息不能再次出现-客户端只能重新发一次请求 -产生的原因如下图所示
当leader节点向所有的follower节点发送commit消息之前,leader节点直接崩溃,也就是说,
所有的follower节点都没有同步到leader节点最后崩溃前处理的客户端请求的数据。
就是说当老leader节点可以使用,加入新的leader领导的集群中作为follower节点使用的时候,
老leader节点最后处理的客户端请求需要丢弃
2 .崩溃恢复的解决方案
A:针对第一个问题,选出集群中拥有最高zxid编号事务proposal机器之一,作为新的leader节点
B:针对第二个问题,当老的leader作为新的follower节点加入集群时,新的leader把老的leader中所
有旧的epoch号标记的未被提交的事务proposal清除
5.消息广播模式
1.消息广播模式流程图
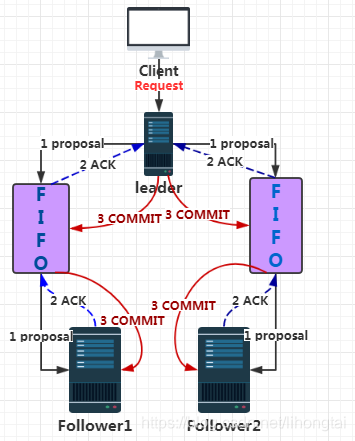
2.消息广播模式的步骤
- 客户端发起一个写操作请求
- Leader服务器将客户端的request请求转化为事物proposql提案,同时为每个proposal分配一个全局唯一的ID,即ZXID。
- leader服务器与每个follower之间都有一个队列,leader将消息发送到该队列
- follower机器从队列中取出消息处理完(写入本地事物日志中)毕后,向leader服务器发送ACK确认。
- leader服务器收到半数以上的follower的ACK后,即认为可以发送commit
- leader向所有的follower服务器发送commit消息。
3. leader节点和每个follower节点之间都有一个队列进行收发消息
使用队列消息可以做到异步解耦。leader和follower之间只要往队列中发送了消息即可。
如果使用同步方式容易引起阻塞。性能上要下降很多。
6.ZAB协议的原理-每个leader都要经历3个阶段
1.发现 -即每个ZK集群必须选举出一个leader节点;每个leader节点维护一个follower列表,将来客户端可以和这些节点通信
2.同步 - 即leader节点负责把本身的数据同步到所有的follower节点上去,做到多副本保存;follower将队列中未处理完的
请求消费完成后,写入本地事物日志中。
3.广播 - 即leader可以接受客户端新的proposal请求,将新的proposal请求广播给所有的follower
7.zookeeper满足CAP理论的CP理论
原因:可以从ZAB协议的崩溃恢复模式的第二个问题来回答,即当老的leader节点作为follower节点加入
新的leader领导的集群中去的时候,新的leader会把老的leader节点中未提交的事务proposal丢弃,
这样就牺牲了一定的可用性