Paxos要解决的问题,是分布式系统中的一致性问题。那么,到底什么是“分布式系统中的一致性问题”呢?在分布式系统中,为了保证数据的高可用,通常我们会将数据保留多个副本(replica),这些副本会放置在不同的物理的机器上。副本要保持一致,那么所有副本的更新序列就要保持一致。因为数据的增删改查操作一般都存在多个客户端并发操作,到底哪个客户端先做,哪个客户端后做,更新顺序要保证。如果不是分布式,那么可以通过加锁的方法,谁先申请到锁谁就先操作,但这就存在单点问题
1.有一个叫做Paxos的小岛(Island)上面住了一批居民,岛上面所有的事情由一些特殊的人决定,他们叫做议员(Senator)。
2.议员的总数(SenatorCount)是确定的,不能更改。
3.岛上每次环境事务的变更都需要通过一个提议(Proposal),每个提议都有一个编号(PID),这个编号是一直增长的,不能倒退。
4.每个提议都需要超过半数((SenatorCount)/2+1)的议员同意才能生效。
5.每个议员只会同意大于当前编号的提议,包括已生效的和未生效的。
6.如果议员收到小于等于当前编号的提议,他会拒绝,并告知对方:你的提议已经有人提过了。这里的当前编号是每个议员在自己记事本上面记录的编号,他不断更新这个编号。整个议会不能保证所有议员记事本上的编号总是相同的。
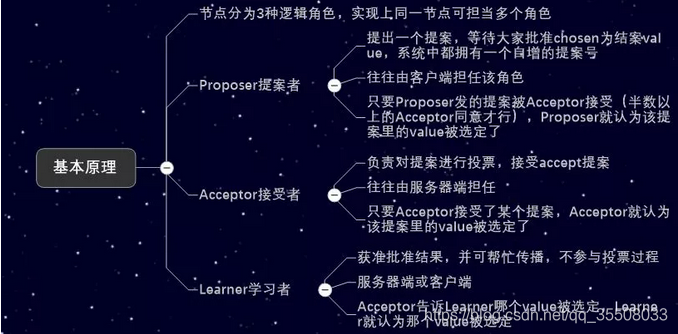
Paxos协议中有三种角色,每个节点可以扮演多个角色:
-
倡议者(Proposer):提议者可以提出提议(数值或在操作命令)以供投票表决。
-
接受者(Acceptor):接受者可以对提议者提出的提议进行投票表决,提议有超过半数的接收者投票即被选中。
-
学习者(Learner):学习者无投票者,只是从接收者那里获取哪个提议被选中。
Paxos算法分为以下三个阶段:
1、Prepare阶段
(1)Proposer向大多数Acceptor发起Proposal(epochNo,value)的Prepare请求。
(2)Acceptor收到Prepare请求,如果epochNo比之前接收到的小,直接拒绝;如果epochNo比之前已经接收的大,就将已经接收到的epochNo最大的Proposal返回到Proposer。
(3)Proposer发起的Proposal至少要收到大多数以上的Acceptor的Prepare应答后,才能进入接下来的Accept阶段,否则需要重新进行Prepare阶段向大多数Acceptor发起Prepare请求。
2、Accept阶段:
(1)Proposer收到大多数的Acceptor的Prepare应答后,看Acceptor是否已经有被接受的Proposal。如果没有已经接受的Proposal,就自己提出一个Proposal,发起Accept请求;如果已经有被接受的Proposal,就从中选出epochNo最大的Proposal,发起对该Proposal的Accept请求。
(2)Acceptor收到请求后,如果该Proposal的epochNo比它最后一次应答Prepare请求的epochNo要大,那么就接受该请求;否则拒绝该请求。
3、Learn阶段:
所有Acceptor接受的Proposal要不断通知Learner,或者Learner主动去查询,一旦Learner确认Proposal被大多数的Acceptor接受,那么表示这个Proposal的Value被Chosen,Learner就可以学习这个Proposal的Value,同时自己的Sever上就不再受理Proposor的请求。
Zookeeper基于ZAB(Zookeeper Atomic Broadcast),实现了主备模式下的系统架构,保持集群中各个副本之间的数据一致性。
ZAB协议定义了选举(election)、发现(discovery)、同步(sync)、广播(Broadcast)四个阶段。
选举(election)是选出哪台为主机; 发现(discovery)、同步(sync)当主选出后,要做的恢复数据的阶段;
广播(Broadcast)当主机和从选出并同步好数据后,正常的主写同步从写数据的阶段。
zk集群有三种角色:
-
leader 就是我们说的主;
-
follower 就是我们说的从;
-
observer 可以认为是主的clone copy,不参与投票;
zk集群的一个节点,有三种状态:
-
looking 选举状态,当前群龙无首;
-
leading leader才有的状态;
-
following follower才有的状态;
每次写成功的消息,都有一个全局唯一的标识,叫zxid。是64bit的正整数,高32为叫epoch表示选举纪元,低32位是自增的id,每写一次加一。 可以想象为中国古代的年号,例如万历十五年,万历是epoch,十五年是id。
zk集群一般都是奇数个机器(2n+1),只有一个主机leader,其余都是从机follower。选主还是写数据,要有>=n+1台选举相同,才能执行选举的操作。
投票优先级:优先比较zxid,如果相等,再比较机器的id,都按从大到小的顺序。
核心思想是递增的zxid顺序,保证了能够有优先级最高的节点当主。主从同步通过提议和提交两个阶段,有超过一半的节点写成功,则认为数据写成功