ZOOKEEPER系列
Paxos、Raft、ZAB
- Paxos算法
莱斯利·兰伯特(Leslie Lamport)这位大牛在1990年提出的一种基于消息传递且具有高度容错特性的一致性算法。如果你不知道这个人,那么如果你发表过Paper,就一定用过Latex,也是这位大牛的创作,
具体背景直接维基百科就可以,不深入讲解,直接讲Paxos算法。
分布式系统对fault tolorence 的一般解决方案是state machine replication。准确的描述Paxos应该是state machine replication的共识(consensus)算法。
Leslie Lamport写过一篇Paxos made simple的paper,没有一个公式,没有一个证明,这篇文章显然要比Leslie Lamport之前的关于Paxos的论文更加容易理解,但是,这篇文章是助于理解的,只到理解这一个层面是不够的。
在Leslie Lamport 的论文中,主要讲了三个Paxos算法
1. Basic Paxos
2. Multi Paxos
3. Fast Paxos
那么我们应该先从Basic Paxos学起
在Basic paxos算法中,分为4种角色:
Client: 系统外部角色,产生议题者,像民众
Proposer :接收议题请求,像集群提出议题(propose),并在冲突发生时,起到冲突调节的作用,像议员
Acceptor:提议的投票者和决策者,只有在形成法定人数(一般是majority多数派)时,提议才会被最终接受,像国会
Learner:最终提议的接收者,backup,对集群的已执行没有什么影响,像记录员

- 客户端给出一个提议,Proposer接收
- Proposer提交法案给Acceptor
- Acceptor把结果给Proposer,
- Proposer告诉Acceptor 议题已经被全部通过了,请求通过
- Acceptor 通过议题告诉Acceptor 和Learner,议题通过
- Learner返回给客户端,你的议题被通过了
这是一个正常的通过的情况

- 客户端给出一个提议,Proposer接收
- Proposer提交法案给Acceptor
- Acceptor把结果给Proposer,其中有一个Acceptor没有通过
- Proposer告诉Acceptor 议题已经被大多数通过了,请求通过
- Acceptor 通过议题告诉Acceptor 和Learner,议题通过
- Learner返回给客户端,你的议题被通过了

- 客户端给出一个提议,Proposer接收
- Proposer提交法案给Acceptor
- Acceptor把结果给Proposer,全部通过
- Proposer节点挂掉了,这个时候议案不会被通过
- 选举新的Proposer(leader)
- 新的Proposer提交2号法案给Acceptor
- Acceptor把结果给Proposer,全部通过
- Acceptor 通过议题告诉Acceptor 和Learner,议题通过
- Learner返回给客户端,你的议题被通过了
潜在问题
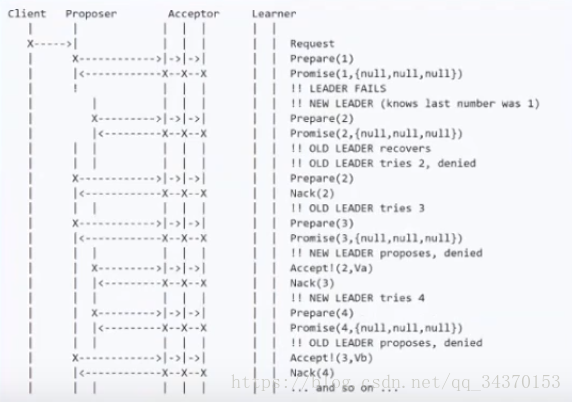
就是在新旧的leader在争抢通过法案,旧的leader法案被pass后,新的leader法案在提交,准备阶段,这个时候旧的leader发现自己的法案被pass了,然后提出一个新的法案,序号加1,Acceptor看到这个法案是最新的,那新的leader发来的法案就被pass掉了,来看旧的leader发来的法案,这个时候新的leader发现自己的法案被pass了,也回在序号上加1,然后提交申请,Acceptor看到新的leader才是最新的法案,把旧的leader法案pass了,这个时候就会发生活锁现象,实际上都是一个法案,但是最后导致机器无线循环
Basic Paxos问题
难实现,效率低(两轮RPC)、活锁
- Multi Paxos
新概念,Leader:唯一的proposer,所有的请求都需要经过此Leader
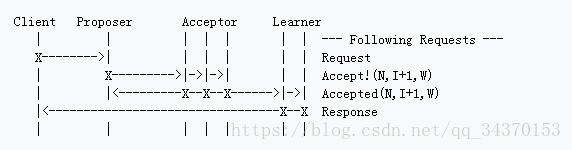
首先先做一下Proposer的Leader选举
Proposer提出的议案,所有的Acceptor需要通过
这个时候就有些像我们所说的一些模式了
Multi Paxos 还做了一个简化操作 如下图

首先servers先竞选leader,2.3步骤,选举好leader,选举好leader后,leader的每一个法案或者议题,都要被通过,然后返回给Client更像我们现实当中的流程了
raft 简化版的Multi Paxos
划分了三个子问题- Leader Electtion
- Log Replication
- Safety
重定义了三个角色
- eader
- Fllower
- Candidate
这个解释的非常明白
原理动画解释:https://http://thesecretlivesofdata.com/raft/
这个是怎样选举的leader,某个节点宕机了怎么解决的详细动画演示
场景测试:http://raft.github.io
Candidate是一个中间状态,Candidate的状态才能够竞选Leader
机器之间与leader之间发送心跳,其中心跳包里可以夹杂着具体的业务数据,每个节点都有自己的超时的时间,每次心跳发送过来了,超时的时钟会重新刷新加载重新走超时,如果真正的超时了那么,就会重新竞选Leader
如果出现网络分区的话怎么办?
一般来说,分布式的机器都是奇数的,那么出现脑裂,一定会有多于一般的机器和少于一半的机器,Raft执行Accept的时候,在大多数机器,也就是半数以上机器通过后,才会执行通过,那么就会出现,两个小集群都会接收到propose,但是数量少的集群没有大多数通过,也就不会执行Accept,数量多的集群会执行Accept,所以不会出现重复执行的脑裂问题。
一致性并不能代表一定是正确的
三个可能的结果:
- 成功
- 失败
- unknown
Client 向Server 发送请求 Leader 向Follower 发送同步日志,此时集群中有三个节点失败,2个节点存活,那么应该是什么样的情况?
会写入记录,但是不会提交执行,因为5个机器,最少三个是多数情况,现在只有两个几点存活,那么不会执行Accept操作
如果集群中的leader发送follower请求,共5台机器,3台宕机,这个时候不是多数派的情况,不会执行请求,但是会记录请求,这个时候leader挂掉,启动其他3台已经宕机的follower,这时,会重新选举leader,然后新的leader会发送新的请求给follower,此时,大多数机器同意,事务被执行,但是上一个leader发送的请求会被覆盖掉,这个时候事务发生丢失现象,所以Raft会存在这样的问题,但是整个系统的一致性和共识是没有问题的。
- ZAB算法
基本与Raft相同,在一些名词叫起来是有区别的
ZAB将Leader的一个生命周期叫做epoch,而Raft称之为term
实现上也有些许不同,如raft保证日志的连续性,心跳是Leader向Follower发送,而ZAB方向与之相反
暂时先讲这么多吧,有时间再进行补充