一、简介
(1)选用requests
(2)数据来源以执法惩戒网站为例网址:http://119.6.84.165:8085/sfgk/webapp/area/cdsfgk/zxxx/zxcj.jsp
目录
二、考察网站
按f12,f5刷新,点击network如图:
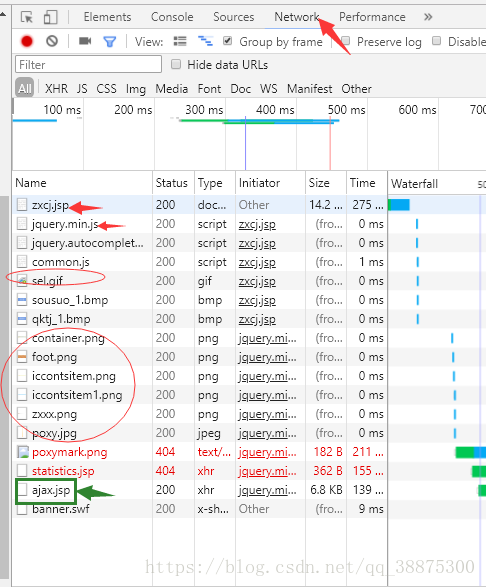
点击每一个请求,查找哪个是你需要的,假如我们是爬取图片和动图的话,我们就看看jpg是不是我们想要的。但是我们的目标是爬取表格,我们就完全没有必要点开.png\.gif\.jpg。重点要关注看.jsp结尾的,首先打开第一个zxcj.jsp,看preview和response都可以,但是preview比较直观,显示的是网页的一些标题、菜单栏之类的。在我们一顿搜索以后找到了ajax.jsp,仔细一看数字信息对上了,如图,所以ajax.jsp就是我们想要请求的。
首先是考察from提交的信息:
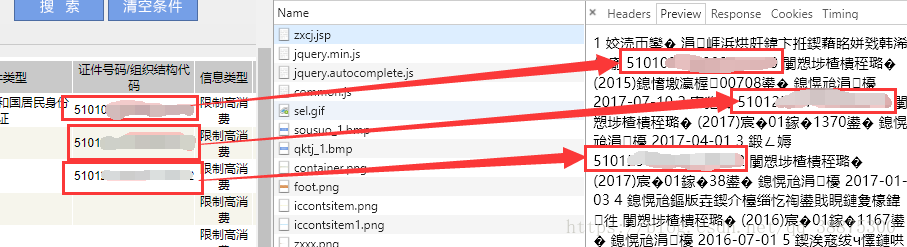
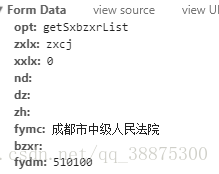
还有from的信息
三、开始爬虫
(1)找到请求头Headers,From Data的信息,这些参数都是我们要用来发送post请求的,复制到本地备用。通过from种格式传到服务器。我选用了元组的格式。 当data 参数传入一个元组列表。在表单中多个元素使用同一 key 的时候,这种方式尤其有效。现在只能爬取一页,通过进一步考察from的参数可以找到参数currentPage显示当前为第几页。同样post_data里面等待post请求发送时一同传过去。
post_data = (('opt', 'getSxbzxrList'), ('zxlx','zxcj'), ('xxlx', 0), ('nd', ''),
('dz',''), ('zh', ''), ('fymc', '成都市中级人民法院'), ('bzxr',''),
('fydm', 510100),('currentPage',i))(2)按照标准套路填写,我只爬了4页:
url = 'http://119.6.84.165:8085/sfgk/webapp/area/cdsfgk/zxxx/ajax.jsp'
for page in range(0, 4):
post_data = (('opt', 'getSxbzxrList'), ('zxlx','zxcj'), ('xxlx', 0), ('nd', ''),
('dz',''), ('zh', ''), ('fymc', '成都市中级人民法院'), ('bzxr',''),
('fydm', 510100),('currentPage',page))
response = requests.post(url, data=post_data)
print(response.text)
四、爬取的数据:

class getData(object):
def __init__(self,url):
self.url = url
self.html = ''
def get_html(self):
for page in range(0, 4):
post_data = (('opt', 'getSxbzxrList'), ('zxlx','zxcj'), ('xxlx', 0), ('nd', ''),
('dz',''), ('zh', ''), ('fymc', '成都市中级人民法院'), ('bzxr',''),
('fydm', 510100),('currentPage',page))
self.html += requests.post(self.url, data=post_data).text
return self.html
gd = getData(URL)
print(gd.get_html())