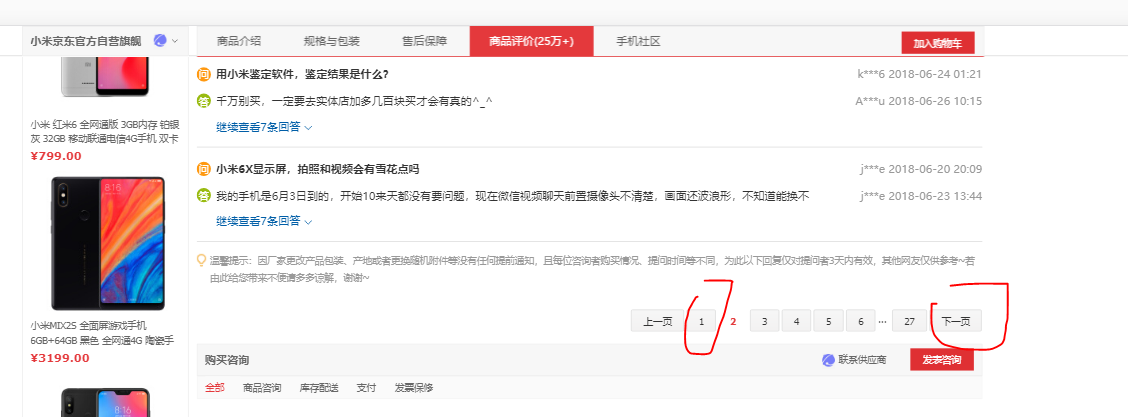
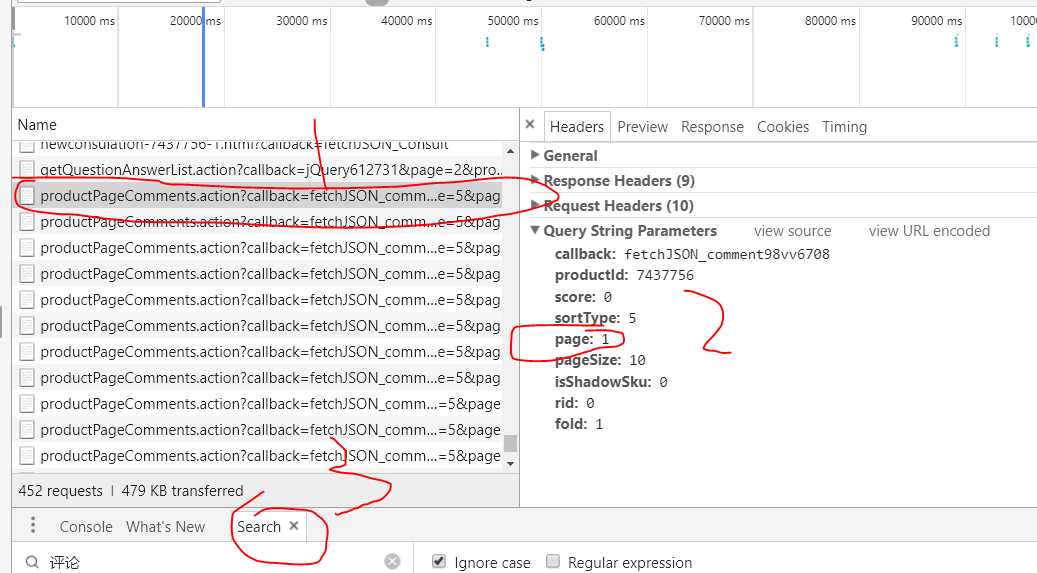
1.当网页打开的方式不同时,在开发者选项找到的包含评论的文件地址不同,比如第一种,当我们找到的评论界面是含有下一页选项的时候(如下图)。我们在左边文件界面发现包含评论的网页地址名字为‘'productPageComments.action'开头的,点开查看header和response可以分析得网址的规律,Query string parameters 里面的page对应着评论的页面,改变这个参数就可以实现评论网页的翻页了。
对于网页的内容点开response可以看见是json格式的网页,所以复制下来可以用在线的json在线解析工具解析一下,看清楚网站的结构。我随便找了个json解析的网站,分析了一下这个网页的结构。
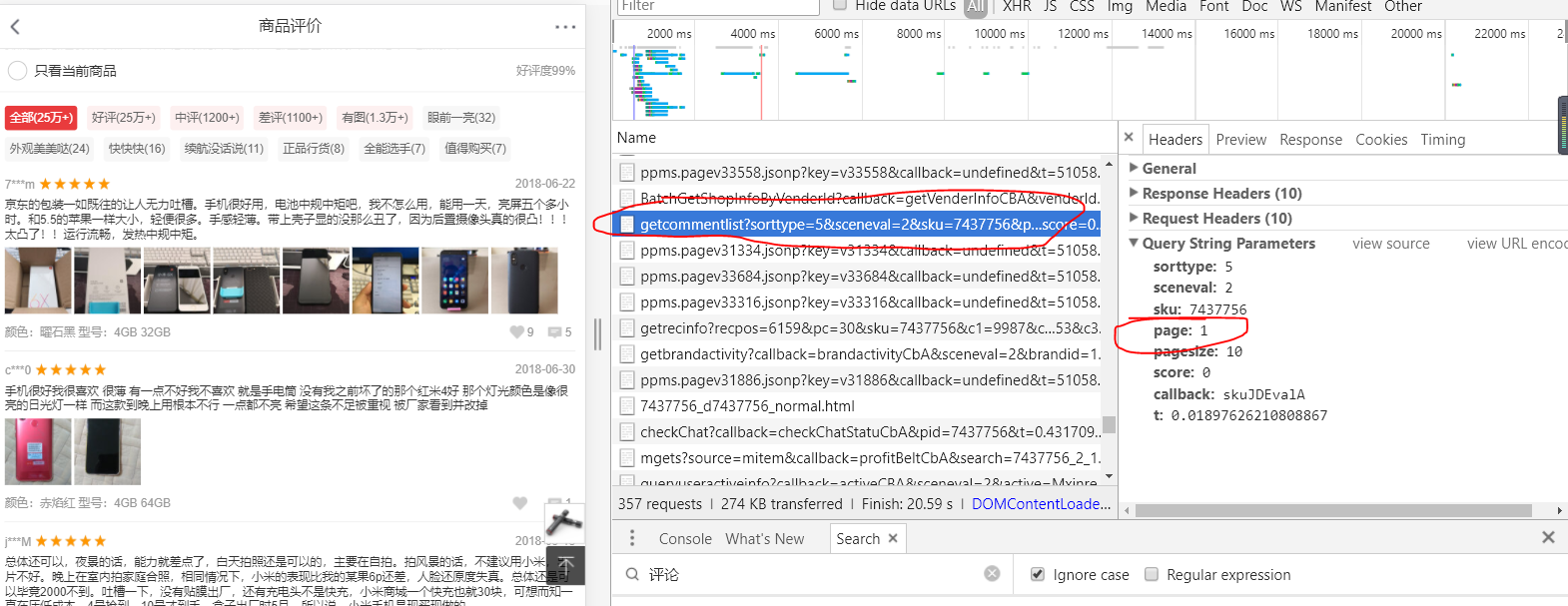
2.当评论网页是以另外一种方式打开,如下图,打开后网页可以一直往下拖自动加载评论,不需要点击下一页(也不包含下一页选项)。这时我们在左边的文件选项中找到包含评论的网页地址名字为‘'getcommentlist'开头的,其他的内容和上面一样,找到url的规律,再到网站里用爬虫规则来提取需要的信息。
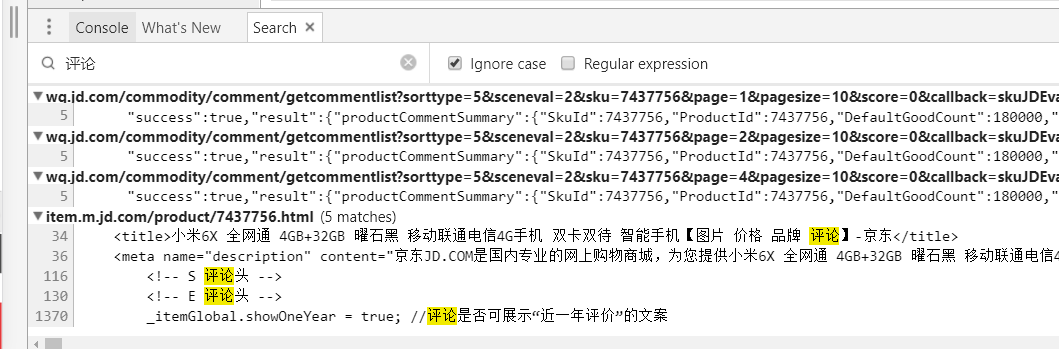
3.小技巧,当打开开发者选项时,在network里面文件特别多,找到想要的文件比较困难,可以按住'ctrl +shift+F',调出search选项,键入关键词,在打开的文件中查找包含关键词的文件。如下图,查找包含‘评论’的文件
4.因为这些动态网页通常都是脚本(json,xml)可以点击'Type'选项对文件进行自动归类,在script类型中找相应的评论文件,这样可以接更清晰,一目了然,如下图
5.爬取的代码

整体爬取的思路,首先,确定爬去的网页是否是动态网页,如果直接对爬取网页打开源代码可以看见所有的需要的信息,并且可以直接获得每一页的网页的url,那么静态网页就不需要上面的那些操作了,直接看源代码用写爬虫了。如果针对某一产品打开不同网页的评论页面但是url地址都不变,说明隐藏了url的其他部分,鉴定为动态网页,运用上面的方法打开开发者选项,找到对应的爬去的网页的文件,获取url参数,找到地址变动的规律,一般都是页面page的变动。找到url地址就好办了,找到某一个爬取页面,分析页面结构,用requests,BeautifulSoup,re等抽取需要的信息。下面是爬取京东小米手机的代码,因为网站反扒,所以限定了爬去的时间,不然爬太快会报错。关于json之前不太明白,查了一下后就是网页用字典形式来变现出来,网页结构清晰,易于处理。这里网页就是json格式。
1 from bs4 import BeautifulSoup 2 import requests 3 import re,json 4 import pandas as pd 5 import time 6 7 #京东小米官方网站爬取小米6X的评论 8 #动态网页爬取 9 10 def getHtml(url,data): #只输入URL的主体部分,后面的参数用下面的字典附加上 11 try: 12 r=requests.get(url,params=data) 13 r.raise_for_status() 14 r.encoding=r.apparent_encoding 15 return r.text 16 except: 17 print('爬取失败') 18 19 def getComment(html):#获得一页的评论 20 commentList=[] 21 i = json.dumps(html) # 将页面内容编码成json数据,(无论什么格式的数据编码后都变成了字符串类型str) 22 j = json.loads(i) # 解码,将json数据解码为Python对象 23 # print(type(j)) 24 comment = re.findall(r'{"productAttr":.*}', j) # 对网页内容筛选找到我们想要的数据,得到值为字典的字符串即'{a:1,b:2}' 25 #print(comment) 26 comm_dict = json.loads(comment[0]) # 将json对象obj解码为对应的字典dict 27 # print(type(comm_dict)) 28 commentSummary = comm_dict['comments'] # 得到包含评论的字典组成的列表 29 for comment in commentSummary: # 遍历每个包含评论的字典,获得评论和打分 30 c_content = ''.join(comment['content'].split()) # 获得评论,由于有的评论有换行,这里用split()去空格,换行,并用join()连接起来形成一整段评论,便于存储 31 score = comment['score'] # 用户打分 32 # print(score) 33 # print(c_content) 34 commentList.append([score,c_content]) 35 return commentList 36 37 '''获得多页评论''' 38 def conments(url,num):#url主体和爬取网页的数量 39 data = {'callback': 'fetchJSON_comment98vv6708', # 调整页数page 40 'productId': '7437756', 41 'score': 0, 42 'sortType': 5, 43 'page': 0, 44 'pageSize': 10, 45 'isShadowSku': 0, 46 'rid': 0, 47 'fold': 1 48 } 49 comments=[] 50 for i in range(num+1): 51 data['page']=i 52 html = getHtml(url, data) 53 comment = getComment(html) 54 comments+=comment 55 print('页数',i) 56 time.sleep(5)#由于网站反爬虫,所以每爬一页停5秒 57 # if i/20==0: 58 # time.sleep(5) 59 return comments 60 61 if __name__ =='__main__': 62 time_start = time.time() 63 url = 'https://sclub.jd.com/comment/productPageComments.action?' 64 comm=conments(url,50) 65 print('共计%d条评论'%(len(comm)))#打印出总共多少条评论 66 name=['score','comment'] 67 file=pd.DataFrame(columns=name,data=comm) 68 file.to_csv('D:/machinelearning data/crawlerData/mi6x_JD3.csv',index=False) 69 time_end = time.time() 70 print('耗时%s秒' % (time_end - time_start))