scrapy爬取动态网页下载图片
静态页面练习了后,我们开始来爬取动态页面,为了满足广大程序猿的需求,在这里就选择360图片吧,网址是image.so.com。希望大家学会后身体一天不如一天。
首先我们来分析这个网页,打开开发者工具,滑动页面等加载出新的图片后,找到如下链接: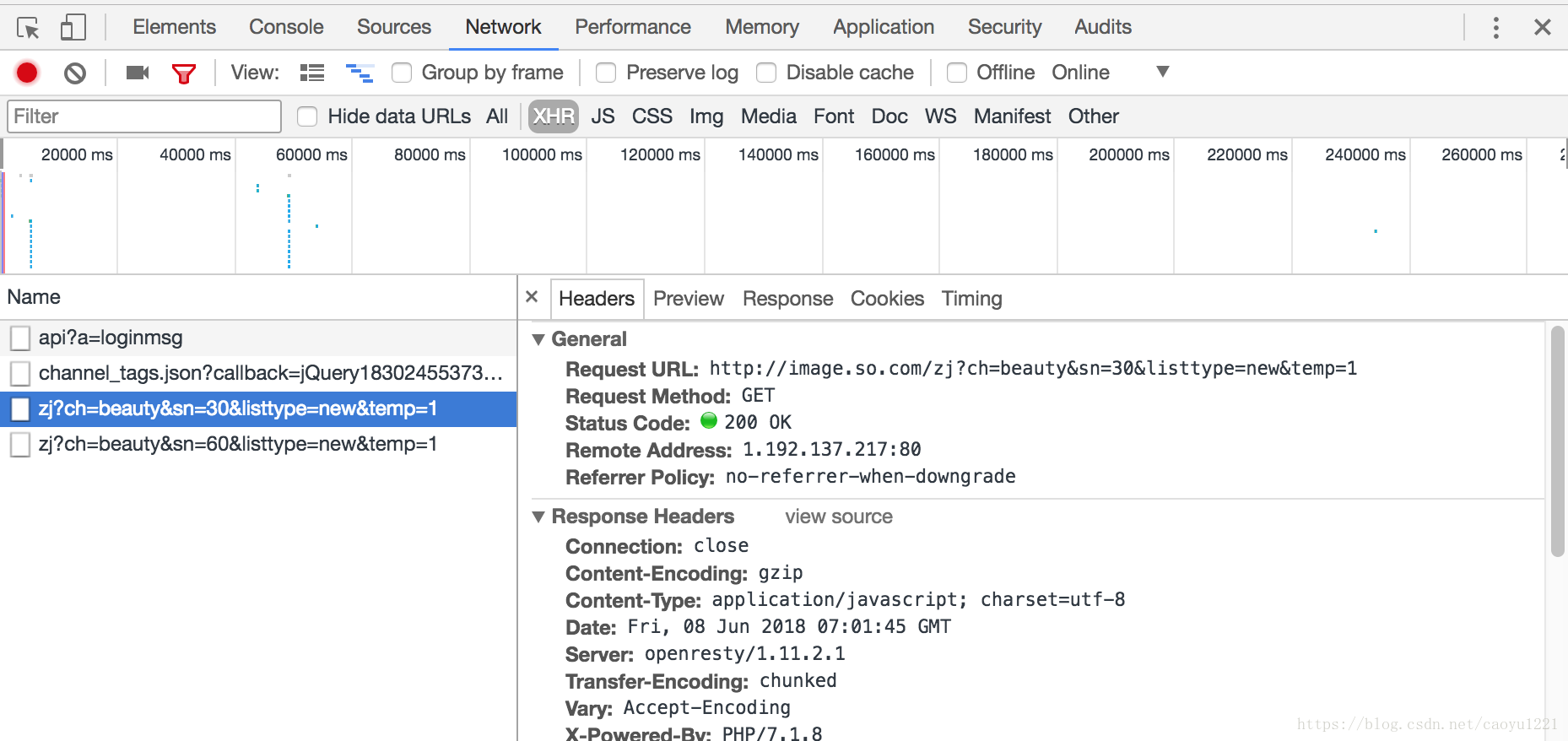
我们可以看到Request URL, 打开并到runoob.com在线解析工具解析出来,解析后我们可以看到如下的json数据: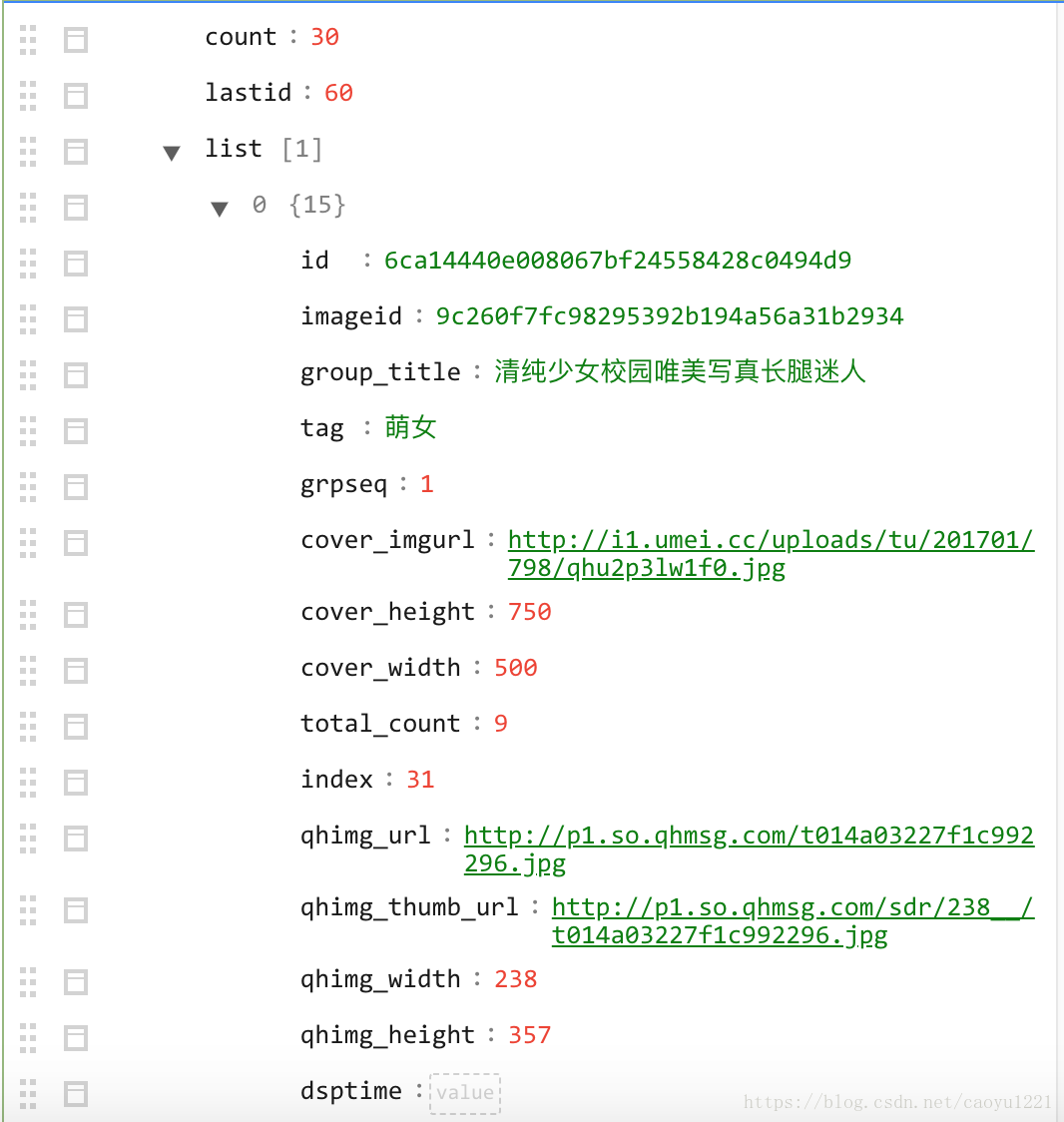
接下来就创建project,开始爬取我们想要的图片, 首先还是在item.py里面设置我们需要的:
import scrapy
class BeautyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
tag = scrapy.Field()
width = scrapy.Field()
height = scrapy.Field()
url = scrapy.Field()image.py
import scrapy
from json import loads
from urllib.parse import urlencode
from image360.items import BeautyItem
class ImageSpider(scrapy.Spider):
name = 'image'
allowed_domains = ['image.so.com']
# 重写方法
def start_requests(self):
base_url = 'http://image.so.com/zj?'
# 创建字典,把不变的参数写死
param = {'ch': 'beauty', 'listtype': 'new', 'temp': 1}
for page in range(10):
param['sn'] = page * 30
full_url = base_url + urlencode(param)
yield scrapy.Request(url=full_url, callback=self.parse)
def parse(self, response):
# 模型循环
model_dict = loads(response.text)
for elem in model_dict['list']:
item = BeautyItem()
item['title'] = elem['group_title']
item['tag'] = elem['tag']
item['width'] = elem['cover_width']
item['height'] = elem['cover_height']
item['url'] = elem['qhimg_url']
yield itemsetting.py
BOT_NAME = 'image360'
SPIDER_MODULES = ['image360.spiders']
NEWSPIDER_MODULE = 'image360.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 2
DOWNLOAD_DELAY = 3
RANDOMIZE_DOWNLOAD_DELAY = True
# 文件存取,存在当前路径下resources目录
IMAGES_STORE = './resources'
ITEM_PIPELINES = {
'image360.pipelines.SaveImagePipeline': 300,
'image360.pipelines.SaveToMongoPipeline': 301,
}到这里,我们的爬虫就可以开始跑了。接下来我们开始完成我们的数据持久化的部分。
from scrapy import Request
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
class SaveImagePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
# 返回requests
yield Request(url=item['url'])
def item_completed(self, results, item, info):
# 下完文件后, 给一个results,返回处理结果
# 传了一个item,所以这个列表只有一个值,而这个值是个元组,我们需要通过results来判断是否下载成功
if not results[0][0]:
raise DropItem('下载失败')
return item
def file_path(self, request, response=None, info=None):
# 拿到文件名
return request.url.split('/')[-1]
class SaveToMongoPipeline(object):
def process_item(self, item, spider):
# 把数据持久化到 mongo
return item现在开始运行程序,可以在resources路径下可以看到下载的图片:
如果想提高一下逼格,写个日志,我们可以接着写下去,首先导入logging这个模块,如果想在下载的时候打印日志,只需要在item_completed里面加入logger.debug('图片下载完成!')。
现在就可以尽情的开始欣赏下载的图片了,大家学会后还是要注意节制,毕竟樯橹灰飞烟灭啊!