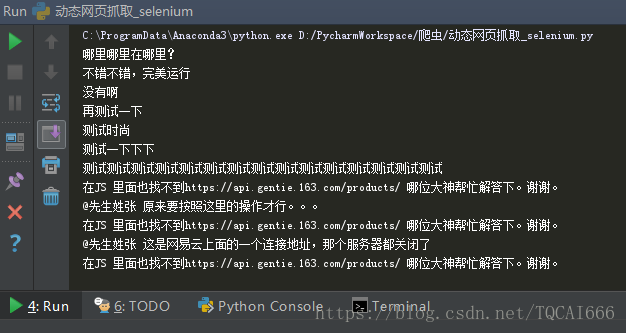
爬取网站:http://www.santostang.com/2017/03/02/hello-world/
首先定位到frame:
通过Ctrl+Shift+C定位,并且搜索frame,定位框架所在位置:
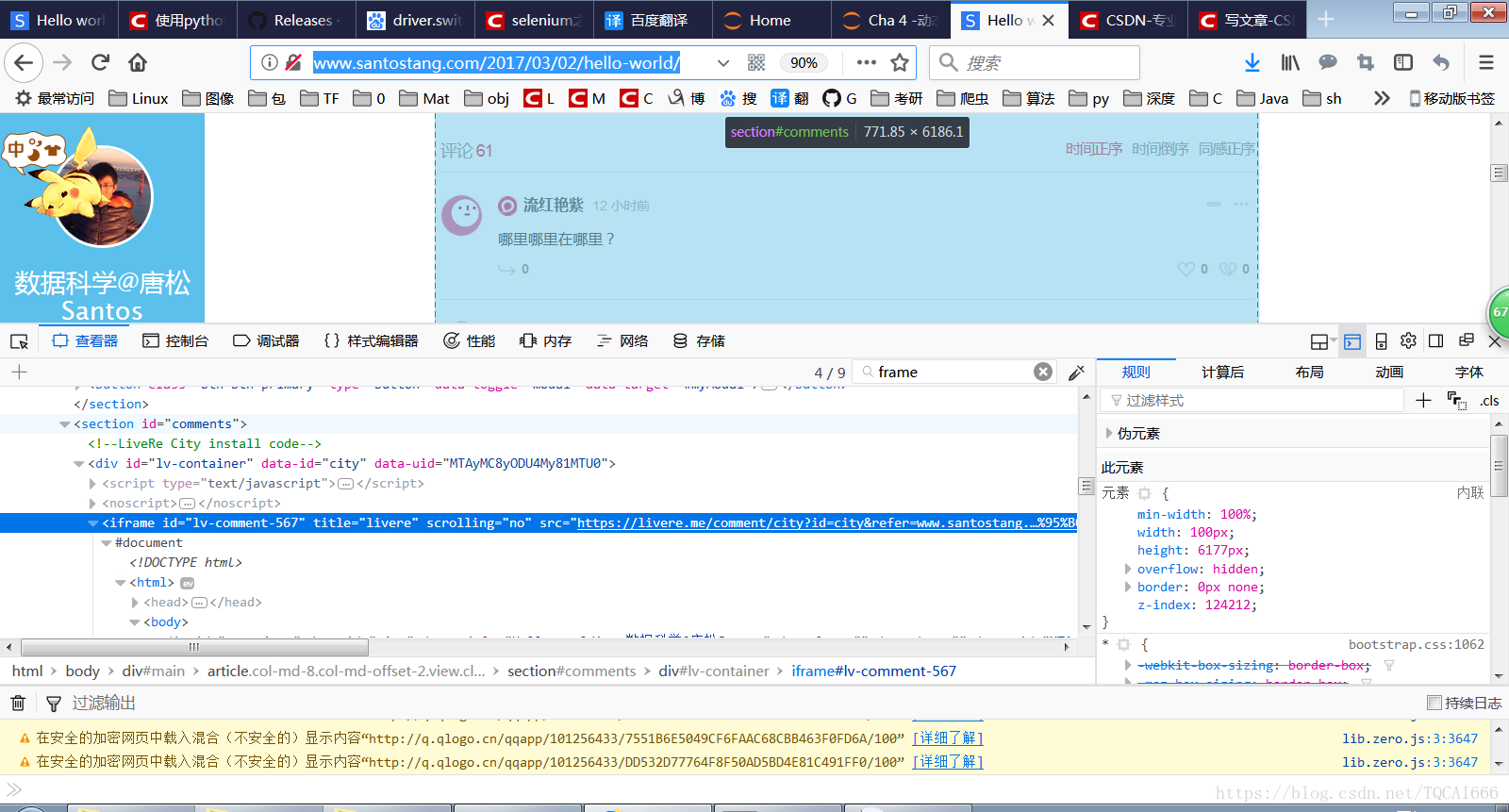
找到HTML代码:
< iframe
title = "livere"
scrolling = "no"
src = "https://livere.me/comment/city?id=city&refer=www.santostang.com%2F2017%2F03%2F02%2Fhello-world%2F&uid=MTAyMC8yODU4My81MTU0&site=http%3A%2F%2Fwww.santostang.com%2F2017%2F03%2F02%2Fhello-world%2F&title=Hello%20world!%20-%20%E6%95%B0%E6%8D%AE%E7%A7%91%E5%AD%A6%40%E5%94%90%E6%9D%BESantos"
style = "min-width: 100%; width: 100px; height: 6177px; overflow: hidden; border: 0px none; z-index: 124212;"
id = "lv-comment-567"
frameborder = "0" > < / iframe >在selenium中我们通过指定iframe的title名来定位:
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))然后定位每条评论的div

通过Ctrl+Shift+C定位,点击评论,找到div代码:
<div class="reply-content"><p>
哪里哪里在哪里?
</p></div>在selenium中通过查找对应的div找到评论:
comments = driver.find_elements_by_css_selector('div.reply-content')可以看到找到的评论在<p></p>中。对每个评论遍历一遍:
for eachcomment in comments:
content = eachcomment.find_element_by_tag_name('p')
print (content.text)