文章地址:https://arxiv.org/pdf/1702.03814.pdf
文章标题:Bilateral Multi-Perspective Matching for Natural Language Sentences(自然语言句子的双边多视角匹配)IJCAI2017
文章代码:https://github.com/zhiguowang/BiMPM
实验数据集:the Quora Question Pairs dataset
Abstract
自然语言句子匹配是完成各种任务的基础技术。以前的方法要么从一个方向匹配句子,要么只应用单个粒度(单词或句子)匹配。在这项工作中,我们提出了一个双边多视角匹配(BiMPM)模型。给定两个句子P和Q,我们的模型首先用BiLSTM编码器对它们进行编码。接下来,我们将两个编码后的句子在两个方向P对Q, Q对P进行匹配。在每个匹配的方向上,一个句子的每一个时间步都从多个角度匹配另一个句子的所有时间步。然后,利用另一个BiLSTM层将匹配结果聚合成固定长度的匹配向量。最后,基于匹配向量,通过全连通层进行决策。 我们从三个方面来评估我们的模型:意思识别、自然语言推理和答案句选择。在标准基准数据集上的实验结果表明,我们的模型在所有任务上都达到了最新的性能。
一、Introduction
自然语言句子匹配(NLSM)是比较两个句子并识别它们之间的关系。它是完成各种任务的基础技术。例如,在释义识别任务中,NLSM被用来判断两个句子是否属于释义[Yin et al., 2015]。在自然语言推理任务中,NLSM用于判断假设句是否可以从前提句中推断出来[Bowman et al., 2015]。在回答问题和信息检索任务中,NLSM用于评估查询-答案对之间的相关性,并对所有候选答案进行排序[Wang et al., 2016d]。在机器理解任务中,NLSM用于将一篇文章与一个问题进行匹配,并指出正确的答案范围[Wang et al., 2016b]。
随着神经网络模型的复兴[LeCun et al., 2015; Peng et al., 2015a; Peng et al., 2016]提出了两种深度学习框架。第一个框架是基于“Siamese(暹罗)”架构[Bromley et al., 1993]。在该框架中,将相同的神经网络编码器(如CNN或RNN)分别应用于两个输入句子,使两个句子都被编码到相同嵌入空间的句子向量中。然后,仅根据两个句子向量进行匹配决策[Bowman et al., 2015;Tan等人,2015]。该框架的优点是,共享参数使模型更小,更容易训练,句子向量可以用于可视化、句子聚类等目的[Wang et al., 2016c]。然而,缺点是在编码过程中两个句子之间没有明确的交互作用,可能会丢失一些重要的信息。针对这一问题,提出了第二种框架“matching-aggregation(匹配聚合)”架构[Wang and Jiang, 2016;Wang等,2016d]。在这个框架下,首先匹配两个句子中较小的单位(如单词或上下文向量),然后(通过CNN或LSTM)将匹配结果聚合到一个向量中,做出最后的判断。 新的框架捕获了两句话之间更多的交互特性,因此它获得了显著的改进。但是,以前的“匹配聚合”方法仍然有一些限制。首先,一些方法只探索逐字匹配,而忽略了其他粒度匹配(例如,逐句匹配);其次,匹配只在一个方向上进行(如P对Q的匹配),而忽略了相反的方向(如Q对P的匹配)。
在本文中,为了解决这些局限性,我们提出了一个双边多视角匹配(BiMPM)模型用于NLSM任务。我们的模型本质上属于“匹配聚合”框架。给出两个句子P和Q,我们的模型首先用双向长短时记忆网络(BiLSTM)对它们进行编码。接下来,我们将两个编码后的句子在两个方向P->Q和P<-Q,在每个匹配的方向上,我们说P->Q,Q的每个时间步长从多个角度对应P的所有时间步长。然后,利用另一个BiLSTM层将匹配结果聚合成固定长度的匹配向量。最后,基于匹配向量,通过全连通层进行决策。我们用三个NLSM任务来评估我们的模型:意译识别、自然语言推理和答案句子选择。在标准基准数据集上的实验结果表明,我们的模型在所有任务上都达到了最新的性能。
二、Task Definition
形式上,我们可以将NLSM任务的每个示例表示为一个三元组(P,Q,y),其中P=(p1,…,pMj)是一个长度为M的句子,Q = (q1,…,qN)是第二个长度为N的句子,y是表示P和Q之间关系的标签,y是一组特定于任务的标签。NLSM任务可以表示成一个条件概率Pr。具体来说,对于一个意思识别任务,P和Q是两个句子,Y = {0,1},其中y = 1表示P和Q互为意译,否则y = 0。对于自然语言推理任务,P是前提句,Q是假设句,Y = {entailment,contradiction,netural},其中entailment表示Q可以从P中推出,contradiction表示Q不可能是P上的真条件,netural表示P和Q互不相关。在一个答案句选择任务中,P是一个问题,Q是一个候选答案,Y = {0,1},其中y = 1表示Q是P的正确答案,否则y = 0。
三、Method
在本节中,我们首先在3.1小节中对我们的模型进行了高层次的概述,然后在3.2小节中详细介绍了我们的新型多视角匹配操作。
3.1 Model Overview
我们提出了一种双边多视角匹配(BiMPM)模型来估计概率分布Pr(y|P,Q)。我们的模型属于“匹配-聚合”框架[Wang and Jiang, 2016]。与之前的“匹配-聚合”方法相反,我们的模型在两个方向上匹配P和Q (P->Q和P<-Q)。在每个方向上,我们的模型从多个角度匹配这两个句子。图1显示了我们的模型的架构。给定一对句子P和Q,BiMPM模型通过以下五层估计概率分布Pr(y|P,Q)。
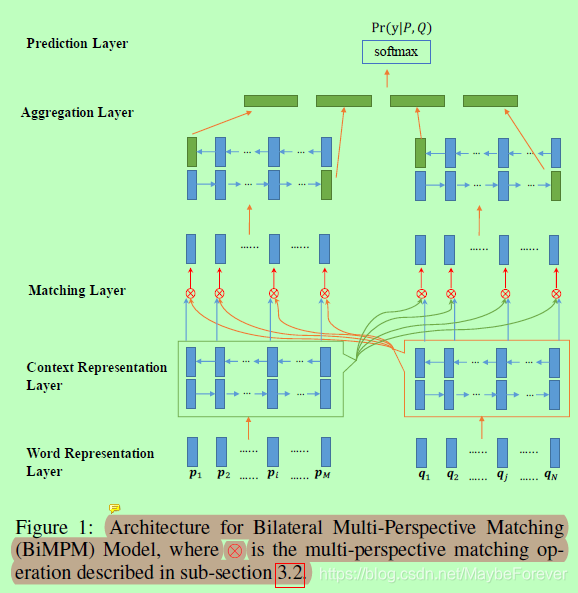
图一:双边多视角匹配(BiMPM)模型的体系结构,其中⊕为3.2小节中描述的多视角匹配操作。
(1)Word Representation Layer(字表示层)
这一层的目标是用d维向量表示P和Q中的每个单词。我们构造了包含两个分量的d维向量:一个词嵌入和一个字符组合嵌入。单词嵌入是每个单独单词的固定向量,使用GloVe [Pennington et al., 2014]或word2vec [Mikolov et al., 2013]对其进行预处理。字符组合嵌入是通过将单词内的每个字符(表示为字符嵌入)输入长短时记忆网络(LSTM)来计算的,其中字符嵌入是随机初始化的,并与NLSM任务中的其他网络参数共同学习。该层的输出是两个字向量序列P和Q。
(2)Context Representation Layer(上下文表示层)
将上下文信息合并到P和Q的每个时间步的表示中。我们利用一个**双向LSTM (BiLSTM)**来为P的每个时间步长编码上下文嵌入。
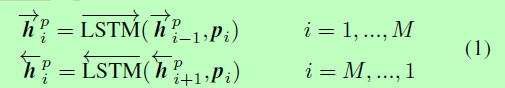
同时,我们应用相同的BiLSTM对Q进行编码:
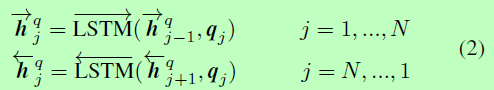
(3)Matching Layer(匹配层)
模型的核心层,这一层的目标是将一个句子的每个上下文嵌入(时间步长)与另一个句子的所有上下文嵌入(时间步长)进行比较。如图1所示,我们将两个句子P和Q进行两个方向的匹配:将P的每个时间步与Q的所有时间步进行匹配,将Q的每个时间步与P的所有时间步进行匹配。为了使一个句子的一个时间步长与另一个句子的所有时间步长匹配,我们设计了一个多视角匹配操作。我们将在第3.2小节中给出关于这个操作的更多细节。该层的输出是两个匹配向量的序列,其中每个匹配向量对应于一个时间步对另一个句子的所有时间步的匹配结果。
(4)Aggregation Layer(聚合层)
该层用于将两个匹配向量序列聚合成一个固定长度的匹配向量。我们利用另一个BiLSTM模型,分别将其应用于两个匹配向量序列。然后,通过将BiLSTM模型最后一个时间步长的四个绿色向量串联起来,构造定长匹配向量。
(5)Prediction Layer(预测层)
这一层的目的是计算概率分布Pr(y|P,Q)。为此,我们采用了两层前馈神经网络来计算定长匹配向量,并在输出层应用了softmax函数。输出层中的节点数是根据第2节中描述的每个特定任务设置的。
3.2 Multi-perspective Matching Operation(多角度匹配操作)
我们按照如下两步来定义多角度匹配操作:
①首先,我们定义了一个多视角余弦匹配函数fm来比较两个向量。
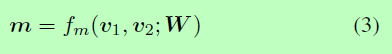
其中v1和v2是两个d维的向量,W是具有 l x d 形状的可训练参数,l 为perspective的数量,返回值m是一个 l 维度的向量m=m[m1,…,ml]。每个元素mk从第k个角度得到一个匹配值,并由两个加权向量之间的余弦相似度计算得到。
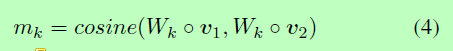
其中,小o表示向量乘法,Wk代表W的第k行,它控制第k个角度,并为d维空间的不同维度分配不同的权重。
②其次,基于fm,我们定义了四种匹配策略来比较一个句子的每个时间步和另一个句子的所有时间步。为了避免重复,我们只定义了一个匹配方向P->Q的匹配策略。读者可以很容易地推导出反方向的方程。
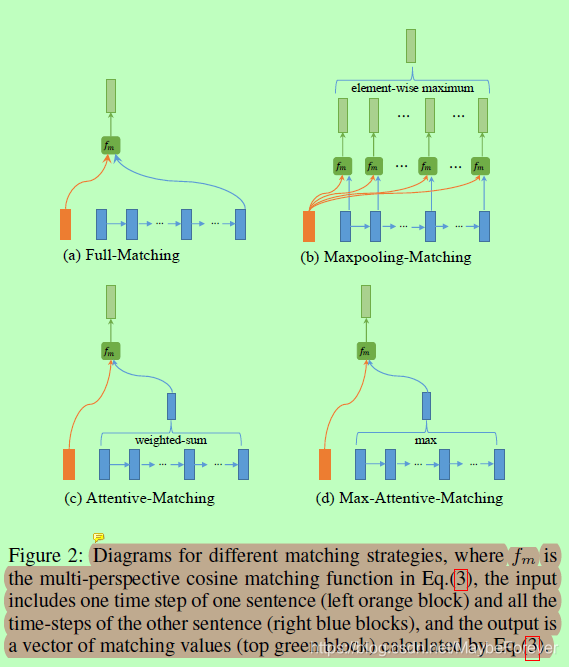
图二:不同的匹配策略图,fm是公式3中的多角度余弦匹配函数。输入包含一个时间步的一句话橙色块(左)和所有其他的时间步长句子蓝色块(右)和匹配的输出是一个矢量值(顶部绿色块)通过公式3计算。
(1)Full-Matching
图2(a)显示了这种匹配策略的关系图。在这个策略中,每个向前(向后)上下文嵌入hp与其他句子hq最后的时间步相比。
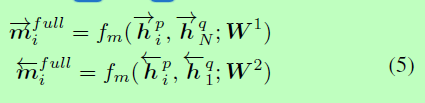
(2)Maxpooling-Matching
图2(b)给出了这种匹配策略的关系图。在这个策略中,每个向前(向后)上下文嵌入hp与每一个其他句子的前向(后向)上下文嵌入hq比较,而只保留每个维度的最大价值。

(3)Attentive-Matching
图2©显示了这种匹配策略的关系图。我们首先计算每个前向(后向)上下文嵌入之间的余弦相似性hp和每一个其他句子的前向(后向)上下文嵌入hq。
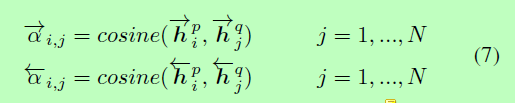
然后,我们计算α作为hq/hp的权重,并且为整个句子Q计算一个attentive vector并对Q所有上下文嵌入项进行加权求和。
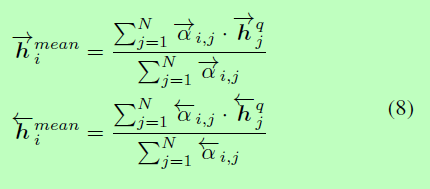
最后,我们将hp的每一个前向(或后向)上下文嵌入与其对应的attentive向量进行匹配:
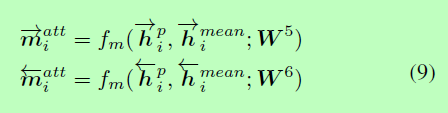
(4)Max-Attentive-Matching
图2(d)显示了这种匹配策略的关系图。这种策略类似于注意力匹配策略。然而,我们并没有将所有上下文嵌入的加权和作为attentive向量,而是选择余弦相似度最高的上下文嵌入作为attentive向量。然后,我们用新的attentive向量来匹配句子P的每个上下文嵌入。
我们将这四种匹配策略应用于P语句的每一个时间步,并将生成的八个向量串联起来作为P的每一个时间步的匹配向量,我们对反向匹配方向也进行同样的处理。
四、Experiments
在这一节中,我们将从三个方面来评估我们的模型:意思识别、自然语言推理和答案句选择。我们将首先在4.1小节中介绍我们的BiMPM模型的一般设置。然后,我们在4.2小节中通过一些消融研究来展示我们的模型的特性。最后,我们将我们的模型与一些标准基准数据集上的最新模型进行比较。
五、Related Work
自然语言句子匹配(NLSM)的研究已有多年历史。早期的方法侧重于设计手工特性来捕获n-gram重叠、单词重新排序和语法对齐现象[Heilman和Smith, 2010;Wang and Ittycheriah, 2015]。这种方法可以很好地处理特定的任务或数据集,但很难很好地推广到其他任务。
随着大规模带注释数据集的可用性[Bowman et al., 2015],许多针对NLSM的深度学习模型被提出。第一类框架是基于Siamese体系结构[Bromley et al., 1993],其中,基于一些神经网络编码器将句子编码成句子向量,然后仅根据两个句子向量确定两个句子之间的关系[Bowman et al., 2015;Yang et al., 2015;Tan等人,2015]。然而,这种框架忽略了两个句子之间的低层交互特征是必不可少的这一事实。因此,许多神经网络模型被提出来从多个粒度级别匹配句子[Yin et al., 2015;王和江,2016;Wang等,2016d]。在许多任务上的实验结果证明,新框架的工作性能明显优于以前的方法。我们的模型也属于这个框架,我们在第4节中已经展示了它的有效性。
六、Conclusion
在这项工作中,我们提出了一个双边多视角匹配(BiMPM)模型下的“匹配-聚合”框架。与之前的“匹配聚合”方法不同,我们的模型从两个方向(P->Q和P<-Q),在每个单独的方向上,我们的模型从多个角度匹配这两个句子。我们在三个任务上对我们的模型进行了评估:意译识别、自然语言推理和答案句选择。在标准基准数据集上的实验结果表明,我们的模型在所有任务上都达到了最新的性能。
