文章目录
一、pom文件
Finl跟Kafka结合的包
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.11</artifactId> <!--kafka版本是0.11 scala版本是2.11-->
<version>1.7.0</version> <!--flink版本是1.7.0-->
</dependency>
將json轉換成對象的依賴
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
剩下做需要的包,我在文章: https://blog.csdn.net/qq_44472134/article/details/104193662 中的《API操作》中提过,不知道的可以到这个网址上看看
二、将Kafka作为数据源,通过Flink进行词频统计 关键词:keyBy() reduce()
kafkaUtil工具类
package com.kafkautil
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011
/**
* TODO
*
* @author 徐磊
* @email [email protected]
* @data2020/02/06 下午 06:27
*/
object KafkaUtil {
val prop = new Properties()
prop.setProperty("bootstrap.servers","node132:9092")
prop.setProperty("group.id","gmall")
def getkafka(topic:String):FlinkKafkaConsumer011[String]={
//因为kafka版本是0.11所以选FlinkKafkaConsumer011
val kafkasource = new FlinkKafkaConsumer011[String](topic,new SimpleStringSchema(),prop)
kafkasource
}
}
用Flink计算Kafka传来的数据进行Wordcount求和
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
/**
* TODO
*
* @author 徐磊
* @email [email protected]
* @data2020/02/06 下午 06:47
*/
object StreamKafkaApi extends App {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//调用kafka工具类 传入1705a
val kafkautil = KafkaUtil.getkafka("1705a")
//将kafka作为Flink的数据源,kafkasource 就是kafka传过来的消息
val kafkasource: DataStream[String] = env.addSource(kafkautil)
// kafkasource.map(jsonstr=>JSON.parseObject(jsonstr,classOf[])) //json轉換成String *******
//kafka作为数据源,传过来的数据进行词频统计
val res = kafkasource.flatMap(_.split(" ")).map((_,1)).keyBy(0).reduce({
(res1,res2)=>(res1._1,res1._2+res2._2)
})
//想象SparkStream一样按批次的进行聚合(就是每隔5秒计算一次)
res.print()
env.execute()
}
三、通过split和select进行分流
package com.kafkautil
import com.alibaba.fastjson.JSON
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
/**
* TODO
*
* @author 徐磊
* @email [email protected]
* @data2020/02/06 下午 06:47
*/
object StreamKafkaApi extends App {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//调用kafka工具类 传入1705a
val kafkautil = KafkaUtil.getkafka("1705a")
//将kafka作为Flink的数据源,kafkasource 就是kafka传过来的消息
val kafkasource: DataStream[String] = env.addSource(kafkautil)
//**********************用Flink将Kafka数据进行分流,把一个流分成两个流
//**************1、先split+判断
val sp = kafkasource.split{startlog=>
var flags:List[String]=null //刚开始将flags设置成 null
//*****************************这一步就跟盖戳一样,最后通过select根据不同的戳然后再分发到不同的容器中
if(startlog=="mi"){ // 单词是是mi 的
flags=List("mi")
}else if(startlog=="huawei"){ // 单词是huawei 的
flags=List("huawei")
}else{ //既不是mi 又不是 huawei
flags=List("anzhuo")
}
flags //最后返回 flags
}
// **************** 2、通过select选择每部分分别存进那个容器中
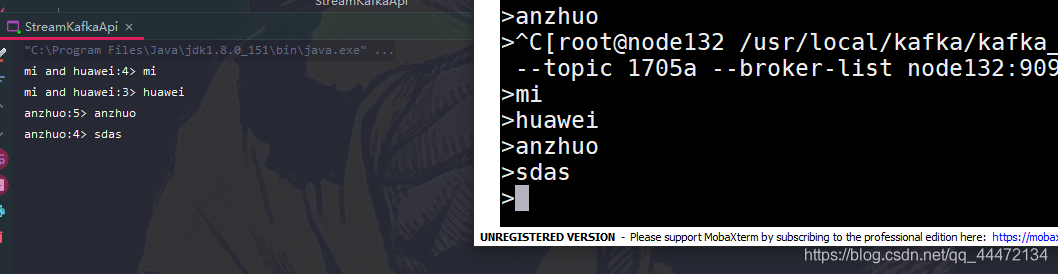
val sele1 = sp.select("mi","huawei") //判断sp中是否有 "mi","huawei",有的话就意味着kafka传过来的是 mi 或者 huawei
val sele2 = sp.select("anzhuo") //判断sp中是否有 "anzhuo" , 有的话就意味着kafka传过来的是 anzhuo 或者 其他单词
sele1.print("mi and huawei")
sele2.print("anzhuo")
env.execute()
}
分流结果
四、通过 connect map和union 进行合流
package com.kafkautil
import com.alibaba.fastjson.JSON
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
/**
* TODO
*
* @author 徐磊
* @email [email protected]
* @data2020/02/06 下午 06:47
*/
object StreamKafkaApi extends App {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//调用kafka工具类 传入1705a
val kafkautil = KafkaUtil.getkafka("1705a")
//将kafka作为Flink的数据源
val kafkasource: DataStream[String] = env.addSource(kafkautil)
// kafkasource.map(jsonstr=>JSON.parseObject(jsonstr,classOf[])) //json轉換成String *******
//**********************1、kafka作为数据源,传过来的数据进行词频统计
/*val res = kafkasource.flatMap(_.split(" ")).map((_,1)).keyBy(0).reduce({
(res1,res2)=>(res1._1,res1._2+res2._2)
})*/
//**********************2、用Flink将Kafka数据进行分流,把一个流分成两个流 关键词:split select
val sp = kafkasource.split{startlog=>
var flags:List[String]=null
if(startlog=="mi"){ //开头是mi的
flags=List("mi")
}else if(startlog=="huawei"){ //开头是华为的
flags=List("huawei")
}else{
flags=List("anzhuo")
}
flags
}
val sele1 = sp.select("mi","huawei")
val sele2 = sp.select("anzhuo")
//****************************3、将分开的流整合到一块
//**********************************3.1 第一種方法 connect map
val sele_one= sele1.connect(sele2)
//有可能connect之後是兩個不同的類型,就可以在map中進行轉換
val seleall_one=sele_one.map(
(sele1)=>sele1,
(sele2)=>sele2
)
seleall_one.print("整合到一块的")
//*********************************3.2 第二種方法 union
//需要在 union 之前把两个的类型弄一致 例:sele1和sele2都是 DataStreams[String]
val seleall_two=sele1.union(sele2)
seleall_two.print()
//***********************兩種方法的不同點
//1. connect 可以把兩個 不同類型 的流放到一塊,然後到map中再調整成 同一類型;優點是更加靈活
// union 是把兩個 類型完全一致 的流整合到一塊;優點是更加便捷
//2.connect map 一次只能操作兩個流 union一次可以操作多個流,只要類型一致都可以放,最後union把他們都擰到一塊
env.execute()
}
