1: 基于DataSet 批处理的API编程(最新版本Flink 1.12.0已经淘汰)
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.MapOperator;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* @author liu a fu
* @version 1.0
* @date 2021/3/3 0003
* @DESC Flink 的批处理 API编写 WordCount DataSet Flink1.12 流批一体被淘汰了
* 1.准备环境-env
* 2.准备数据-source
* 3.处理数据-transformation
* 4.输出结果-sink
* 5.触发执行-execute
*/
public class BatchWordCount {
public static void main(String[] args) throws Exception {
//1-环境准备 env
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//2-准备数据 source 这里从本地文件中获取
DataSource<String> inputDataSet = env.readTextFile("datas/wordcount.data");
//3- 数据的处理transformation
/*
step1. 将每行数据按照分割符分割为单词
spark spark flink -> spark, spark, flink
step2. 将每个单词转换为二元组,表示每个单词出现一次
spark, spark, flink -> (spark, 1), (spark, 1), (flink, 1)
step3. 按照单词分组,将同组中次数进行累加sum
(spark, 1), (spark, 1), (flink, 1) -> (spark, 1 + 1 = 2) , (flink, 1 = 1)
*/
//TODO: 3-1 将每行数据按照风格符来分割
FlatMapOperator<String, String> wordDataSet = inputDataSet.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> out) throws Exception {
String[] words = line.trim().split("\\s+"); //按照风格符 切割
for (String word : words) {
out.collect(word); //收集器收集数据
}
}
});
//TODO: 3-2 将每个单词转换为二元元组 表示每一个单词出现的次数
MapOperator<String, Tuple2<String, Integer>> tupleDataSet = wordDataSet.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String word) throws Exception {
return Tuple2.of(word, 1);
}
});
//TODO: 3-3 按照单词进行分组,将相同组的进行累加sum
AggregateOperator<Tuple2<String, Integer>> resultDataSet = tupleDataSet
.groupBy(0) // 二元组索引的第一个元素
.sum(1); // 二元组 的索引第二个元素 类似 Spark的按照相同Key的 value聚合 groupByKey算子
//4- 输出结果sink
resultDataSet.print(); //异常抛出
//5.触发执行-execute
//env.execute(BatchWordCount.class.getSimpleName()); 批处理不需要
}
}
2-基于DataStream 流处理的API编程,Flink 1.12 官网推荐使用的
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @author liu a fu
* @version 1.0
* @date 2021/3/3 0003
* @DESC Flink的流处理的 WordCount DataStream API 官方推荐使用的API 1.12 流批一体的API
*
* TODO: 使用Flink 计算引擎实现流式数据处理:从Socket接收数据,实时进行词频统计WordCount
*/
public class StreamWordCount {
public static void main(String[] args) throws Exception {
//1- 环境准备env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2- 数据源 source
DataStreamSource<String> inputDataStream = env.socketTextStream("node1.itcast.cn", 9999);
//3- 数据的转换 transformation
/*
step1. 将每行数据按照分割符分割为单词
spark spark flink -> spark, spark, flink
step2. 将每个单词转换为二元组,表示每个单词出现一次
spark, spark, flink -> (spark, 1), (spark, 1), (flink, 1)
step3. 按照单词分组,将同组中次数进行累加sum
(spark, 1), (spark, 1), (flink, 1) -> (spark, 1 + 1 = 2) , (flink, 1 = 1)
*/
//TODO: 3-1 对每行的数据进行指定的分割符号切割
SingleOutputStreamOperator<String> wordDataStream = inputDataStream.flatMap(new FlatMapFunction<String, String>() {
/**
*
* @param line 按照是定的分割符号切割 成 一行 数据
* @param out 数据收集器 输出
* @throws Exception
*/
@Override
public void flatMap(String line, Collector<String> out) throws Exception {
for (String word : line.trim().split("\\s+") ) {
out.collect(word);
}
}
});
//TODO: 3-2 将每个单词转换为二元组,表示每个单词出现一次
SingleOutputStreamOperator<Tuple2<String, Integer>> tupleDataStream = wordDataStream.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String word) throws Exception {
return Tuple2.of(word,1);
}
});
//TODO: 3-3 将二元元组 按照指索引 将指定key的Value 聚合
SingleOutputStreamOperator<Tuple2<String, Integer>> resultDataStream = tupleDataStream
.keyBy(0).sum(1);
//4- 数据终端的 sink
resultDataStream.print();
//5- 触发执行器 execute
env.execute(StreamWordCount.class.getSimpleName());
}
}
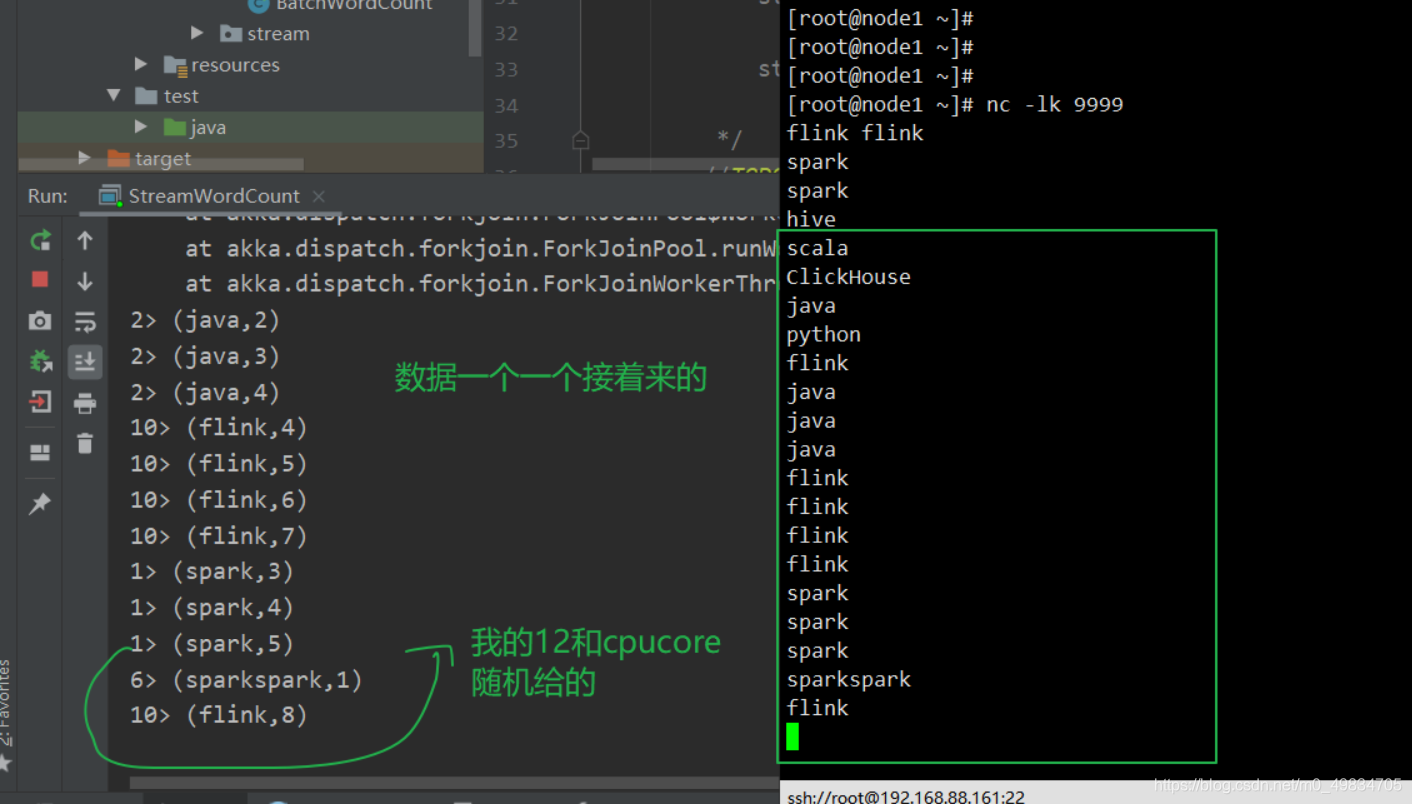
结果: 模拟 scoket发送通信
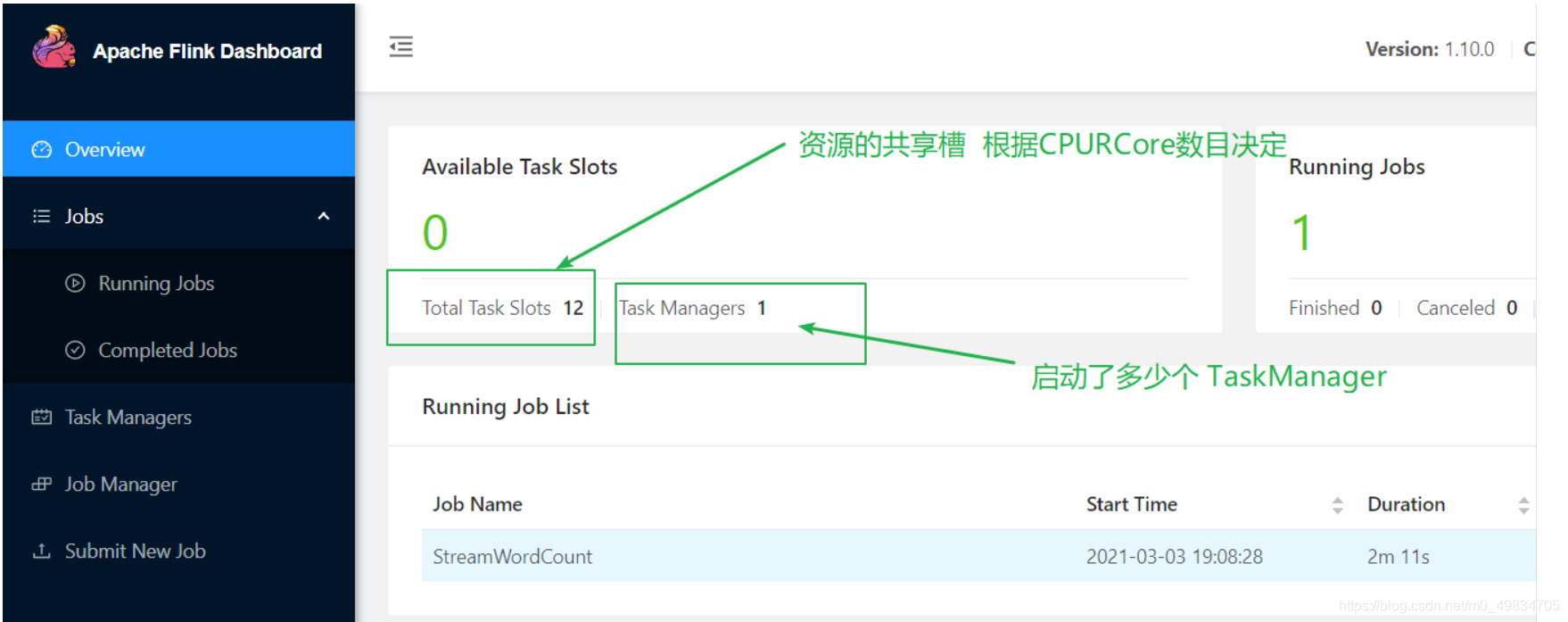
webUI: