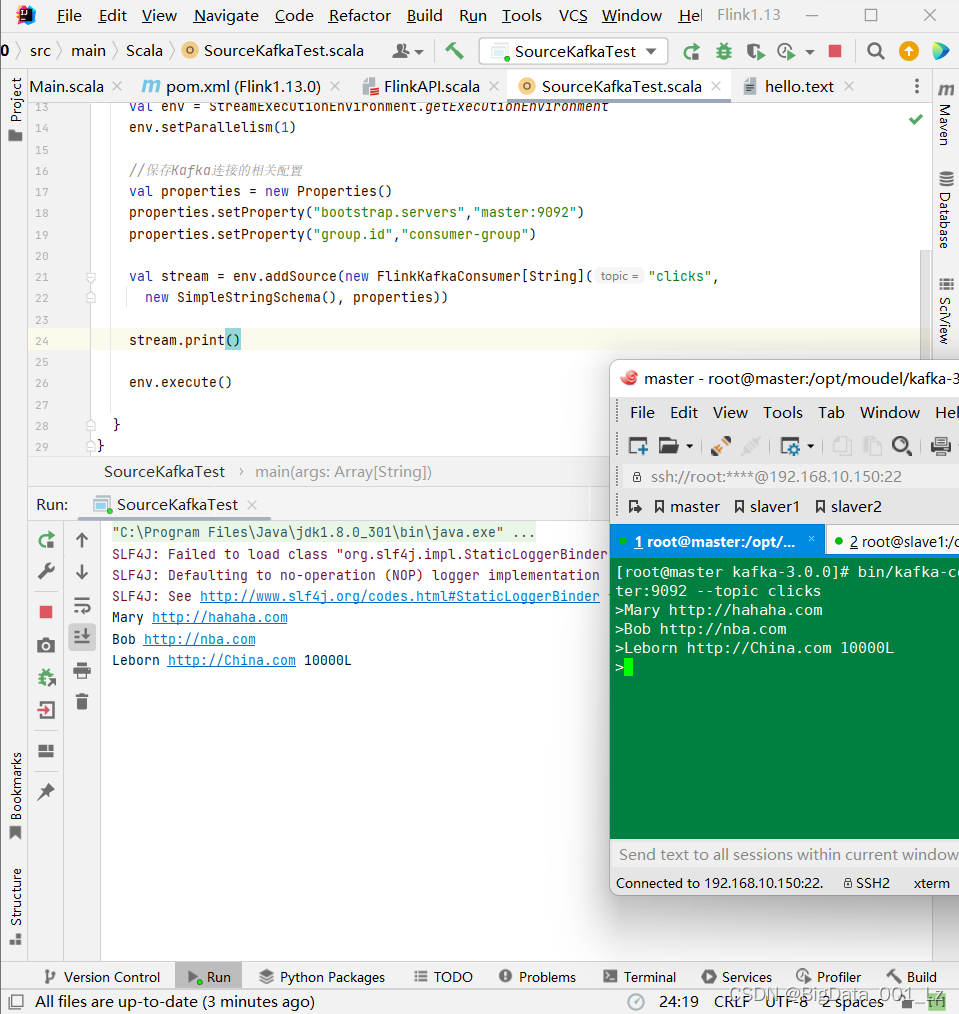
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, createTypeInformation}
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import java.util.Properties
/**
* DATE:2022/10/3 21:49
* AUTHOR:GX
*/
object SourceKafkaTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
//Kafka连接的相关配置
val properties = new Properties()
properties.setProperty("bootstrap.servers","master:9092")
properties.setProperty("group.id","consumer-group")
val stream = env.addSource(new FlinkKafkaConsumer[String]("clicks",
new SimpleStringSchema(), properties))
stream.print()
env.execute()
}
}
创建kafka生产者
bin/kafka-console-producer.sh --bootstrap-server master:9092 --topic clicks