文章目录
处理缺失值的步骤一般为:
- 识别缺失值
- 补全个案或删除个案
个案、行都是指代一个意思
###识别缺失值
识别缺失值的方法很多,这里主要介绍三种。
####is.na函数
R语言中用NA代表缺失值。使用is.na函数可以检测缺失值,并返回True或FALSE组成的向量。
下面用举一个例子。
#首先生成一个有缺失值的数据框
a <- c(1,2,3,NA)
b <- c(5,6,7,8)
c <- c(7,8,NA,2)
data <- data.frame(a,b,c)
#data数据集的3和4行存在缺失值
data
a b c
1 1 5 7
2 2 6 8
3 3 7 NA
4 NA 8 2
#用is.na函数
is.na(data)
a b c
[1,] FALSE FALSE FALSE
[2,] FALSE FALSE FALSE
[3,] FALSE FALSE TRUE
[4,] TRUE FALSE FALSE
#结果显示第3行第3列和第四行第1列存在缺失值。
####!complete.case函数
complete.case函数可以列出没有缺失值的行,开头加**!可以列出存在缺失值的行。R语言中!**是否定的意思。
引用上面数据集作!complete.case函数示例。
data[!complete.cases(data),]
a b c
3 3 7 NA
4 NA 8 2
#结果显示第3行和第4行有缺失值
还可用sum函数和mean函数获取缺失值的有关信息
#检查data中a的缺失值数量
sum(is.na(data$a))
#1个
[1] 1
#检查data中a的缺失值比例
mean(is.na(data$a))
#缺失25%
[1] 0.25
#!complete.cases函数同样可以
sum(!complete.cases(data$a))
[1] 1
mean(!complete.cases(data$a))
[1] 0.25
####mice包
当数据集较小时用is.namice包中的md.pattern函数可以帮助检测缺失值,并以矩阵或数据框形式和图片展示缺失值表格。
#首先安装mice包
install.packages("mice")
#载入mice包
library(mice)
#检测数据,以data数据集为例
md.pattern(data)
b a c
2 1 1 1 0
1 1 1 0 1
1 1 0 1 1
0 1 1 2
结果在左上角显示有2行没有缺失值,有1行c变量缺失,1行a变量缺失,最右下角共计2个缺失值
返回的图片则以可视化方式展示表达同样的意思。
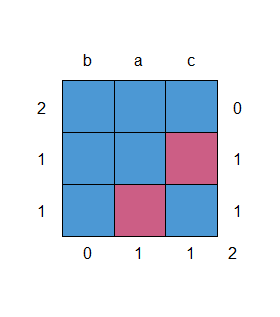
如果数据没有缺失值,则返回一行计数为0的图片
###缺失值处理
缺失值处理一般分为两种。一种是删除个案,一种是补全个案。
####删除个案
用complete.cases函数生成一个新的数据集或na.omit函数删除存在缺失值的行。
newdata <- data[complete.cases(data),]
newdata
a b c
1 1 5 7
2 2 6 8
na.omit(data)
a b c
1 1 5 7
2 2 6 8
####补全个案
一般采用多重插补(MI)方法补全个案,它是基于重复模拟思想而来。Amelia、mice和mi包都可以实现这一功能。本次主要使用mice包为例。
基于mice包分析通常分析过程:
- library(mice)
- imp <- mice(data,m)
- fit <- with(imp,analysis)
- pooled <-pool(fit)
- summary(pooled)
其中
- data是一个包含缺失值的矩阵或数据框。
- imp是一个包含m个插补数据集的列表对象,默认m为5。
- analysis是一个表达式对象,用来设定应用于m个插补数据集的统计分析方法。包括线性回归模型lm函数,广义线性模型glm函数等。
- fit是一个包含这m个统计分析单独统计分析结果的列表对象。
- pooled是一个包含着m个统计分析平均结果的列表对象。
示例:
library(mice)
data(sleep,package='VIM')
imp <- mice(sleep,seed=1234)
fit <- with(imp,lm(Dream~Span+Gest))
pooled <-pool(fit)
summary(pooled)
#通过imp查看更多信息
imp
#查看实际插补值
imp$imp$Dream
#指定m个完整数据集中的一个来展示
dataset <- complete(imp,action=3)
补全缺失值数据的方法还有均值补充、中位数补充、线性回归、线性趋势等,另表不题。
