即上次写完整个爬虫程序到现在已有3天左右的时间了,今天拿出上一次的爬虫程序接着跑,就跑不下来了,不得不说,B站更新实在是快。感觉很可惜,故此修改了原本的程序,可以再次抓取b站视频了。由于网速等众多原因,导致爬取速度极其缓慢,故此,另外加上了 多进程 来提高程序的运行速度,另外加上了注释。本程序唯一的一个不好的地方在于,加上多进程以后,进度条显示错乱,对于这个问题,我也没有深入去解决,所以,原谅本程序的缺点。(本程序只能抓取改版以后的 .m4s 格式文件的视频 ---------> 大概是18年7月份以后的视频(没做具体查询))
程序运行结束后的截图
(这里用“韩女团饭拍视频库”实验的,因为相比较而言,b站高产这样的视频,所以抓个象征性的视频,均为高清原画质):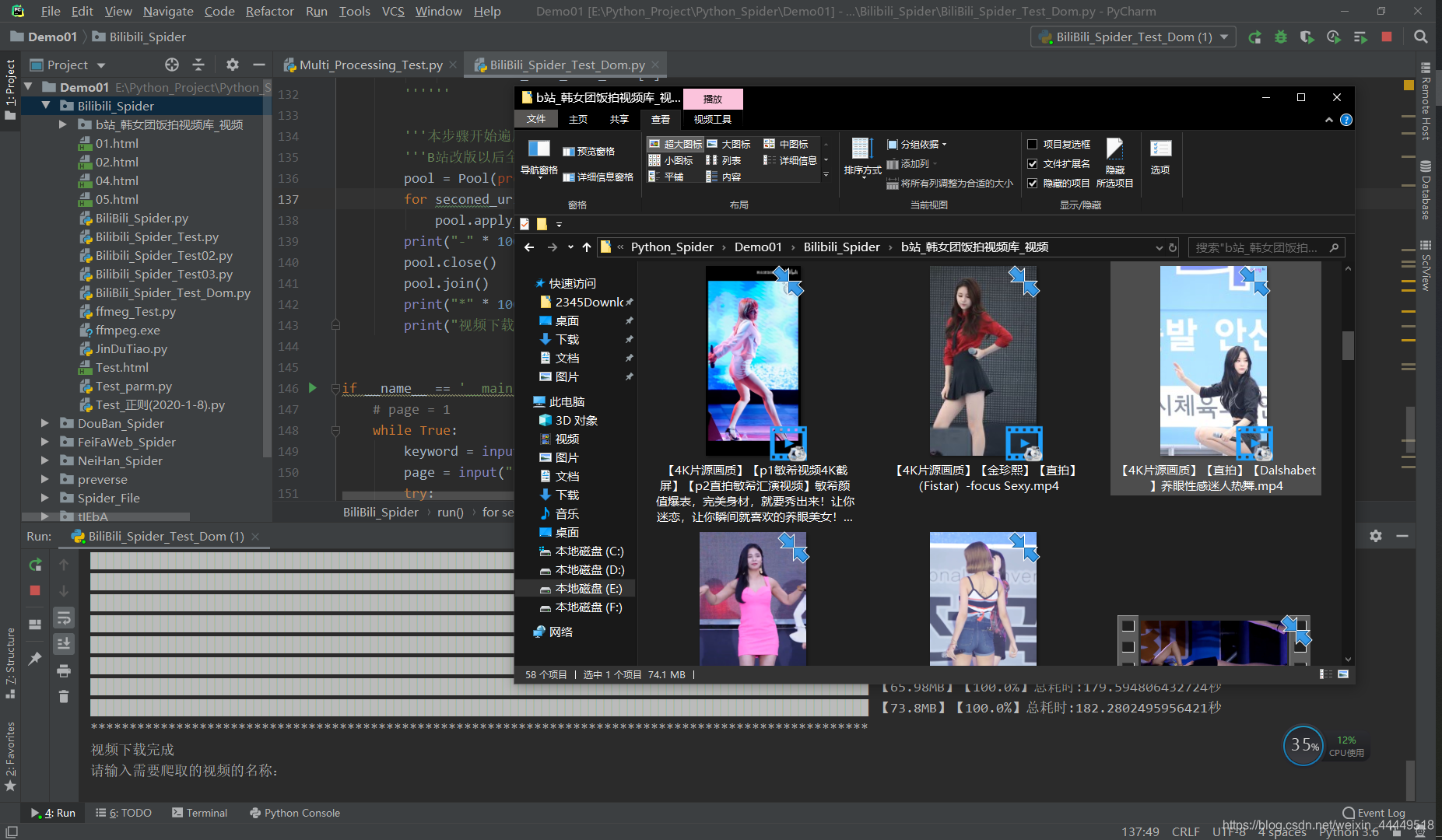
程序源码如下:
import requests
import re
import time
import os
from retrying import retry
from multiprocessing import Pool
class BiliBili_Spider:
def __init__(self, keyword, page, audio_condition):
self.audio_condition = audio_condition
self.page = page
self.num = 0
self.index_url = "https://search.bilibili.com/all?keyword={}&from_source=nav_search&page={}".format(keyword,
page)
self.index_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"
}
self.seconed_headers = {
"Accept-Encoding": "identity",
"Accept": "*/*",
"Connection": "keep-alive",
"Accept-Language": "zh-CN,zh;q=0.9",
"Sec-Fetch-Site": "cross-site",
"Sec-Fetch-Mode": "cors",
"Origin": "https://www.bilibili.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
self.File_name = "b站_{}_视频".format(keyword, page)
if not os.path.exists(self.File_name):
os.makedirs(self.File_name)
@retry(stop_max_attempt_number=2)
def get_request(self, url, headers, stream=False):
res = requests.get(url, headers=headers, stream=stream)
return res
@retry(stop_max_attempt_number=2)
def write_data(self, file_name, m4s_bytes, chunk_size, content_size):
size = 0
if os.path.exists(self.File_name + "/" + file_name):
print("遇到重复视频,已自动选择跳过此下载")
print(file_name)
else:
print("正在下载 {}:".format(file_name))
with open(self.File_name + "/" + file_name, "wb") as f:
for data in m4s_bytes.iter_content(chunk_size=chunk_size):
f.write(data)
size = len(data) + size
print('\r' + int(size / content_size * 100) * "█" + " 【" + str(
round(size / chunk_size / 1024, 2)) + "MB】" + "【" + str(
round(float(size / content_size) * 100, 2)) + "%" + "】", end="")
def for_run_url(self, seconed_url_w):
seconed_url = seconed_url_w[0]
file_name = seconed_url_w[1]
'''请求 seconed_url 获取页面,对页面进行处理'''
html_str02 = self.get_request("http:" + seconed_url, self.index_headers).content.decode("utf-8")
try:
'''匹配 m4s_30080 视频文件的url'''
m4s_30080 = re.findall(r'''"baseUrl":"(.*?)"''', html_str02, re.S)[0]
except Exception as e:
print(e)
self.num = self.num + 1
raise Exception(print("continue"))
'''匹配 mp3_30216 音频文件的 url'''
if self.audio_condition == 'Y':
mp3_30216 = re.findall(r'''"baseUrl":"(.*?)"''', html_str02, re.S)[-2]
'''上一步拿到 视频 音频 文件的url之后,需要构造 (试探total) 的请求头请求数据'''
Referer_key = seconed_url
# 试探请求头大小
Range_key = 'bytes=0-5'
self.seconed_headers['Referer'] = 'https://' + Referer_key
self.seconed_headers['Range'] = Range_key
'''获取请求头中的total'''
html_bytes = self.get_request(m4s_30080, headers=self.seconed_headers).headers['Content-Range']
if self.audio_condition == 'Y':
audio_bytes = self.get_request(mp3_30216, headers=self.seconed_headers).headers['Content-Range']
'''正则匹配 total 的值'''
total = re.findall(r"/(.*)", html_bytes, re.S)[0]
if self.audio_condition == 'Y':
audio_total = re.findall(r"/(.*)", audio_bytes, re.S)[0]
'''上一步通过试探获取到了total,这里就构造请求头请求全部的视音频数据'''
self.seconed_headers['Range'] = total
'''进度条效果参数 stream chunk_size content_size'''
stream = True
chunk_size = 1024 # 每次块大小为1024
content_size = int(total)
if self.audio_condition == 'Y':
content_size_audio = int(audio_total)
print("文件大小:" + str(round(float((content_size + content_size_audio) / chunk_size / 1024), 4)) + "[MB]")
else:
print("文件大小:" + str(round(float(content_size / chunk_size / 1024), 4)) + "[MB]")
start = time.time()
try:
m4s_bytes = self.get_request(m4s_30080, headers=self.seconed_headers, stream=stream)
self.write_data(file_name + ".mp4", m4s_bytes, chunk_size, content_size)
if self.audio_condition == 'Y':
print("\n")
self.seconed_headers['Range'] = audio_total
mp3_bytes = self.get_request(mp3_30216, headers=self.seconed_headers, stream=stream)
self.write_data(file_name + ".mp3", mp3_bytes, chunk_size, content_size_audio)
except Exception as e:
print(e)
self.num = self.num + 1
raise Exception(print("continue"))
end = time.time()
print("总耗时:" + str(end - start) + "秒")
self.num = self.num + 1
def run(self):
'''获取开始爬取的原始页面'''
# print("第一次请求开始。。。。。")
html_str01 = self.get_request(self.index_url, self.index_headers).content.decode("utf-8")
# print(html_str01)
'''本步骤开始获取待爬取的视频的 跳转链接 以及 名字'''
avi_href_name_list = re.findall(
r'''<li class="video-item matrix"><a href="(.*?)" title="(.*?)" target="_blank" class="img-anchor">''',
html_str01)
# print(avi_href_name_list)
'''此步爬虫失效,由Blibili更新引起,2020-1-8 重写爬虫'''
'''本步防止出现正则匹配到最前面开头部分的名字导致请求失败'''
if len(avi_href_name_list) != 20:
count = len(avi_href_name_list) - 20
for i in range(count):
del avi_href_name_list[i]
''''''
'''本步骤开始遍历 avi_href_name_list ,分别取出 url 与 name'''
'''B站改版以后全面限速,考虑网速与下载速度原因,加上多进程'''
pool = Pool(processes=20)
for seconed_url_w in avi_href_name_list:
pool.apply_async(self.for_run_url, args=(seconed_url_w,))
print("-" * 100)
pool.close()
pool.join()
print("*" * 100)
print("视频下载完成")
if __name__ == '__main__':
# page = 1
while True:
keyword = input("请输入需要爬取的视频的名称:\n")
page = input("请输入需要爬取的视频的页码(只能为数字):\n")
try:
int(page)
except:
print("输入的字符不为数字,请重试!!!\n\n")
continue
audio_condition = input("是否需要音频一同下载('视音频分离下载,速度原因,请使用格式工厂合并视音频'):(请输入单个字符:'Y' or 'N')\n")
if not audio_condition in ('Y', 'N'):
print("输入的字符不为单个字符:'Y' or 'N',请重新输入:\n\n")
continue
# keyword = "舞蹈"
# audio_condition = 'N'
bilibili_spider = BiliBili_Spider(keyword, page, audio_condition)
bilibili_spider.run()
# page = page + 1
我这里把进程数默认设置为20,当然,如果你在本程序上进行修改,把程序修改为自动下载多页视频的时候,可以根据自己电脑cpu占用情况来适当调大(如下图所示)
