因为是在单机环境下模拟集群环境,所以需要用不同端口来模拟不同主机。
搭建集群前,我们先来了解Zookeeper集群的角色;
文章目录
一、集群的角色
1)领导者(Leader) : 负责进行投票的发起和决议,最终更新状态。
2)跟随者(Follower): Follower用于接收客户请求并返回客户结果。参与Leader发起的投票。
3)观察者(observer): Oberserver可以接收客户端连接,将写请求转发给leader节点。但是Observer不参加投票过程,只是同步leader的状态。Observer为系统扩展提供了一种方法。
4)学习者 ( Learner ) : 和leader进行状态同步的server统称Learner,上述Follower和Observer都是Learner。
二、为什么要有Observer
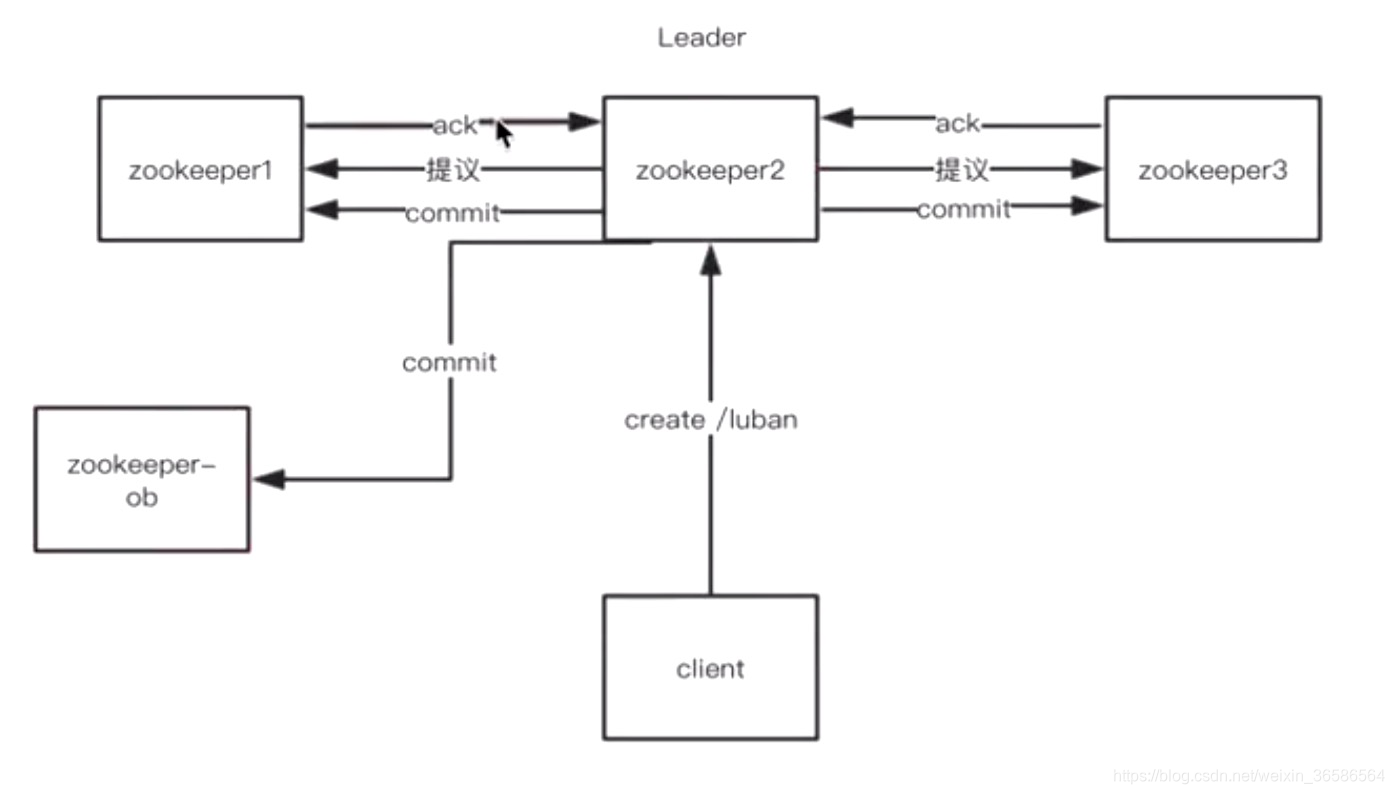
ZooKeeper服务中的每个Server可服务于多个Client,并且Client可连接到ZK服务中的任一台Server来提交请求。若是读请求,则由每台Server的本地副本数据库直接响应。若是改变Server状态的写请求,需要通过一致性协议来处理,这个协议就是我们前面介绍的Zab协议。
简单来说,Zab协议规定:来自Client的所有写请求,都要转发给ZK服务中唯一的Server—Leader,由Leader根据该请求发起一个Proposal。然后,其他的Server对该Proposal进行投票。之后,Leader对投票进行收集,当投票数量过半时Leader会向所有的Server发送一个通知消息。最后,当Client所连接的Server收到该消息时,会把该操作更新到内存中并对Client的写请求做出回应。
ZooKeeper 服务器在上述协议中实际扮演了两个职能。它们一方面从客户端接受连接与操作请求,另一方面对操作结果进行投票。这两个职能在 ZooKeeper集群扩展的时候彼此制约。例如,当我们希望增加 ZK服务中Client数量的时候,那么我们就需要增加Server的数量,来支持这么多的客户端。然而,从Zab协议对写请求的处理过程中我们可以发现,增加服务器的数量,则增加了对协议中投票过程的压力。因为Leader节点必须等待集群中过半Server响应投票,于是节点的增加使得部分计算机运行较慢,从而拖慢整个投票过程的可能性也随之提高,写操作也会随之下降。这正是我们在实际操作中看到的问题——随着 ZooKeeper 集群变大,写操作的吞吐量会下降。
所以,我们不得不,在增加Client数量的期望和我们希望保持较好吞吐性能的期望间进行权衡。要打破这一耦合关系,我们引入了不参与投票的服务器,称为 Observer。
Observer可以接受客户端的连接,并将写请求转发给Leader节点。但是,Leader节点不会要求 Observer参加投票。相反,Observer不参与投票过程,仅仅在上述第3歩那样,和其他服务节点一起得到投票结果。
这个简单的扩展,给 ZooKeeper 的可伸缩性带来了全新的镜像。我们现在可以加入很多 Observer 节点,而无须担心严重影响写吞吐量。但他并非是无懈可击的,因为协议中的通知阶段,仍然与服务器的数量呈线性关系。但是,这里的串行开销非常低。因此,我们可以认为在通知服务器阶段的开销无法成为主要瓶颈。
三、Zookeeper中的CAP
Zookeeper至少满足了CP,牺牲了可用性,比如现在集群中有Leader和Follower两种角色,那么当其中任意一台服务器挂掉了,都要重新进行选举,在选举过程中,集群是不可用的,这就是牺牲的可用性。
但是,如果集群中有Leader、Follower、Observer三种角色,那么如果挂掉的是Observer,那么对于集群来说并没有影响,集群还是可以用的,只是Observer节点的数据不同了,从这个角度考虑,Zookeeper又是牺牲了一致性,满足了AP
四、集群环境搭建
(一)复制配置文件
cd {zookeeperurl}/conf/
cp zoo.cfg zoo1.cfg
cp zoo.cfg zoo2.cfg
cp zoo.cfg zoo3.cfg
cp zoo.cfg zoo_ob.cfg
(二)创建数据以及日志文件目录
mkdir -p /zookeeper/data_1
mkdir -p /zookeeper/data_2
mkdir -p /zookeeper/data_3
mkdir -p /zookeeper/data_ob
mkdir -p /zookeeper/logs_1
mkdir -p /zookeeper/logs_2
mkdir -p /zookeeper/logs_3
mkdir -p /zookeeper/logs_ob
(三)创建myid文件
echo “1” > /zookeeper/data_1/myid
echo “2” > /zookeeper/data_2/myid
echo “3” > /zookeeper/data_3/myid
echo “4” > /zookeeper/data_ob/myid
(四)修改配置文件
zoo1.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/zookeeper/data_1
clientPort=2181
dataLogDir=/zookeeper/logs_1
#server.x中的x和myid中的一致,
#第一个端口用户Leader和Learner之间的同步,
#第二个端口用于选举过程中的投票通信
server.1=localhost:2887:3887
server.2=localhost:2888:3888
server.3=localhost:2889:3889
server.4=localhost:2890:3890:observer
zoo2.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/zookeeper/data_2
clientPort=2181
dataLogDir=/zookeeper/logs_2
server.1=localhost:2887:3887
server.2=localhost:2888:3888
server.3=localhost:2889:3889
server.4=localhost:2890:3890:observer
zoo3.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/zookeeper/data_3
clientPort=2181
dataLogDir=/zookeeper/logs_3
server.1=localhost:2887:3887
server.2=localhost:2888:3888
server.3=localhost:2889:3889
server.4=localhost:2890:3890:observer
zoo_ob.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/zookeeper/data_ob
clientPort=2181
dataLogDir=/zookeeper/logs_ob
peerType=observer
server.1=localhost:2887:3887
server.2=localhost:2888:3888
server.3=localhost:2889:3889
server.4=localhost:2890:3890:observer
(五)启动集群
zkServer.sh start {zookeeperUrl}/apache-zookeeper-3.5.5-bin/conf/zoo1.cfg
zkServer.sh start {zookeeperUrl}/apache-zookeeper-3.5.5-bin/conf/zoo2.cfg
zkServer.sh start {zookeeperUrl}/apache-zookeeper-3.5.5-bin/conf/zoo3.cfg
zkServer.sh start {zookeeperUrl}/apache-zookeeper-3.5.5-bin/conf/zoo_ob.cfg
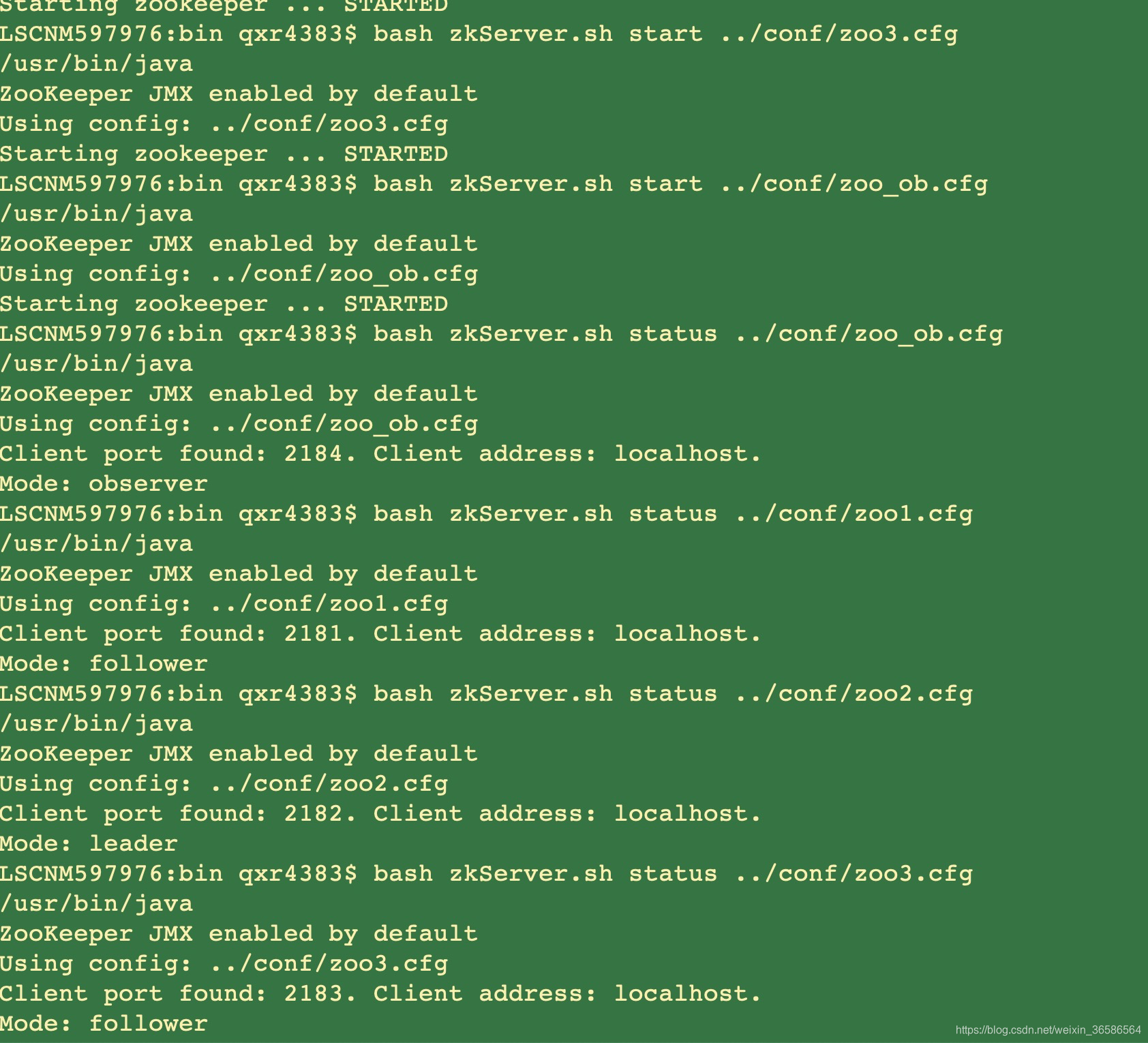
(六)验证
zkServer.sh status {zookeeperUrl}apache-zookeeper-3.5.5-bin/conf/zoo1.cfg
zkServer.sh status {zookeeperUrl}apache-zookeeper-3.5.5-bin/conf/zoo2.cfg
zkServer.sh status {zookeeperUrl}apache-zookeeper-3.5.5-bin/conf/zoo3.cfg
zkServer.sh status {zookeeperUrl}apache-zookeeper-3.5.5-bin/conf/zoo_ob.cfg
可以看到server1:Mode: follower
可以看到server2:Mode: leader
可以看到server3:Mode: follower
可以看到server4:Mode: observer
关闭指令:
zkServer.sh stop {zookeeperUrl}apache-zookeeper-3.5.5-bin/conf/zoo1.cfg
zkServer.sh stop {zookeeperUrl}apache-zookeeper-3.5.5-bin/conf/zoo2.cfg
zkServer.sh stop {zookeeperUrl}apache-zookeeper-3.5.5-bin/conf/zoo3.cfg
zkServer.sh stop {zookeeperUrl}apache-zookeeper-3.5.5-bin/conf/zoo_ob.cfg
打开四个命令行客户端分别连上四个server
zkCli.sh -server localhost:2181
zkCli.sh -server localhost:2182
zkCli.sh -server localhost:2183
zkCli.sh -server localhost:2184
连上之后,在三个客户端执行ls /可以分别查到4个server的当前目录结构都是一样的。
在server1上执行命令create /firstNode “server1创建的”,执行完成后可以看到在server2、server3、server4都能同步被创建成功。
Observer
节点配置中增加
peerType=observer
servers列表中增加:
server.4=localhost:2890:3890:observer
(七)排坑
如果启动异常,可以查看日志
bash zkServer.sh start-foreground …/conf/zoo_ob.cfg
我搭建集群是,复制粘贴写最下面的端口时,末尾不小心打了一个空格,所以总是启动报错,大家搭建集群的时候也要注意细节哦。
五、Zookeeper能做什么?
(一)统一命名服务
命名服务也是分布式系统中比较常见的一类场景。在分布式系统中,通过使用命名服务,客户端应用能够根据指定名字来获取资源或服务的地址,提供者等信息。被命名的实体通常可以是集群中的机器,提供的服务地址,远程对象等等——这些我们都可以统称他们为名字(Name)。其中较为常见的就是一些分布式服务框架中的服务地址列表。通过调用ZK提供的创建节点的API,能够很容易创建一个全局唯一的path,这个path就可以作为一个名称。
(二)配置中心
配置的管理在分布式应用环境中很常见,例如同一个应用系统需要多台 PC Server 运行,但是它们运行的应用系统的某些配置项是相同的,如果要修改这些相同的配置项,那么就必须同时修改每台运行这个应用系统的 PC Server,这样非常麻烦而且容易出错。
像这样的配置信息完全可以交给 Zookeeper 来管理,将配置信息保存在 Zookeeper 的某个目录节点中,然后将所有需要修改的应用机器监控配置信息的状态,一旦配置信息发生变化,每台应用机器就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中。
集群管理与Master选举
集群机器监控:这通常用于那种对集群中机器状态,机器在线率有较高要求的场景,能够快速对集群中机器变化作出响应。这样的场景中,往往有一个监控系统,实时检测集群机器是否存活。过去的做法通常是:监控系统通过某种手段(比如ping)定时检测每个机器,或者每个机器自己定时向监控系统汇报“我还活着”。
利用ZooKeeper有两个特性,就可以实时另一种集群机器存活性监控系统:
- 客户端在节点 x 上注册一个Watcher,那么如果 x?的子节点变化了,会通知该客户端。
- 创建EPHEMERAL类型的节点,一旦客户端和服务器的会话结束或过期,那么该节点就会消失。
例如,监控系统在 /clusterServers 节点上注册一个Watcher,以后每动态加机器,那么就往 /clusterServers 下创建一个 EPHEMERAL类型的节点:/clusterServers/{hostname}. 这样,监控系统就能够实时知道机器的增减情况,至于后续处理就是监控系统的业务了。
在分布式环境中,相同的业务应用分布在不同的机器上,有些业务逻辑(例如一些耗时的计算,网络I/O处理),往往只需要让整个集群中的某一台机器进行执行,其余机器可以共享这个结果,这样可以大大减少重复劳动,提高性能,于是这个master选举便是这种场景下的碰到的主要问题。
(三)分布式锁
分布式锁,这个主要得益于ZooKeeper为我们保证了数据的强一致性。锁服务可以分为两类,一个是保持独占,另一个是控制时序。
所谓保持独占,就是所有试图来获取这个锁的客户端,最终只有一个可以成功获得这把锁。通常的做法是把zk上的一个znode看作是一把锁,通过create znode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。
控制时序,就是所有试图来获取这个锁的客户端,最终都是会被安排执行,只是有个全局时序了。做法和上面基本类似,只是这里 /distribute_lock 已经预先存在,客户端在它下面创建临时有序节点(这个可以通过节点的属性控制:CreateMode.EPHEMERAL_SEQUENTIAL来指定)。Zk的父节点(/distribute_lock)维持一份sequence,保证子节点创建的时序性,从而也形成了每个客户端的全局时序。
以上均为鲁班学院学习资料,欢迎大家报班学习,真心推荐!
