一、ZooKeeper分布式锁
使用Eclipse的Maven来搭建工程,注意使用这种方式需要连接互联网,连接互联网自动下载ZK的所依赖的jar包
所需要的pom.xml文件如下
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-client</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.6</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>16.0.1</version>
</dependency>
</dependencies>将上面的pom.xml粘贴到Eclipse中pom.xml文件中
具体的java代码如下
package com.org.lz;
import org.apache.curator.CuratorConnectionLossException;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import org.apache.curator.retry.ExponentialBackoffRetry;
public class DistributedLock {
//定义共享资源
private static int count = 20;
private static void printCountNumber() {
System.out.println("#########业务方法开始###########");
System.out.println("当前值:" + count);
count --;
//休息2秒
try {
Thread.sleep(2000);
}catch (InterruptedException ex) {
ex.printStackTrace();
}
System.out.println("########业务方法结束########");
}
public static void main(String[] args) {
//定义客户端重试的策略
ExponentialBackoffRetry policy = new ExponentialBackoffRetry(1000,//每次等待的时间
20);//最大重试的次数
//定义ZK的一个客户端
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString("192.168.100.11:2181")
.retryPolicy(policy)
.build();
//在ZK生成锁 -----> 就是ZK的目录
client.start();
final InterProcessMutex lock = new InterProcessMutex(client,"/Threadlock");
//启动20个线程去访问共享资源
for (int i = 0 ;i<20;i++) {
new Thread(new Runnable() {
public void run() {
try {
//请求得到锁
lock.acquire();
//访问共享资源
printCountNumber();
}catch (Exception ex) {
ex.printStackTrace();
}finally {
//释放锁
try {
lock.release();
}catch (Exception ex) {
ex.printStackTrace();
}
}
}
}).start();
}
}
}
运行所得到的结果如图



在ZooKeeper客户端查看,发现多了一个Threadlock节点

在程序未执行完的时候,zai在ZooKeeper客户端查看发现,每次得到的信息不一样,如图所示


当程序执行完的时候,发现没有数据了,每次执行的时候所得到的信息为临时信息。

二、ZooKeeper 集群的搭建
- 首先要保证ZooKeeper的时间同步
在Xshell工具中同时向三个服务器发送一条命令查看他们各自的时间,如果不同步,需要修改为同步的时间,怎么修改,请查看我的CSDN博客的Hadoop三种模式的搭建中的的全分布式模式的搭建

- 在bigdata12上搭建
使用Xshell5配套的工具Xftp5将zooKeeper软件包上传到Linux上去
tar -zxvf zookeeper-3.4.10.tar.gz -C ~/training/
环境变量 vi ~/.bash_profile
ZOOKEEPER_HOME=/root/training/zookeeper-3.4.10
export ZOOKEEPER_HOME
PATH=$ZOOKEEPER_HOME/bin:$PATH
export PATH
生效环境变量
source ~/.bash_profile
注意:环境变量的配置和生效环境变量在三台服务器上都要执行
创建文件mkdir -p /root/training/zookeeper-3.4.10/tmp,此目录用于存放ZK的数据和日志信息
核心的配置文件
cd /root/training/zookeeper-3.4.10/conf/
将cp zoo_sample.cfg zoo.cfg
vi zoo.cfg 在12行中修改成如下所示
dataDir=/root/training/zookeeper-3.4.10/tmp,并在配置文件的zui'最后面添加如下内容
server.1=bigdata12:2888:3888
server.2=bigdata13:2888:3888
server.3=bigdata14:2888:3888
为什么需要修改目录?
因为在Linux中的tmp目录为存放临时文件的,重启服务器,文件内容会丢失。

在/root/training/zookeeper-3.4.10/tmp下创建一个文件 myid
vi myid 在里面写入数字1
1
将配置好的ZK复制到其他节点上
scp -r zookeeper-3.4.10/ root@bigdata13:/root/training
scp -r zookeeper-3.4.10/ root@bigdata14:/root/training
因为在前面搭建Hadoop的全分布式环境的时候已经配置了免密登陆(互信)
修改bigdata13和bigdata14上的myid文件
将bigdata13上的myid文件中的1修改成2
将bigdata14上的myid文件中的1修改成3
每台机器启动ZooKeeper
zkServer.sh start
ZooKeeper集群有数据同步和选举的功能
模拟数据同步:
首先查看三者的数据

在bigdata12上创建一个节点 create /node1 bigdata

查看三者的数据同步情况和节点信息

证明数据同步成功
再查看三者的身份信息
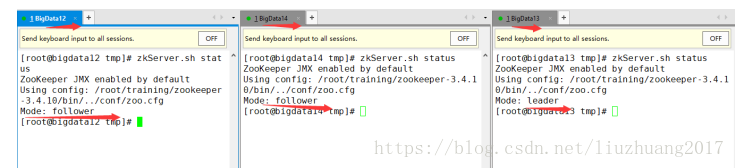
模拟ZooKeeper集群的选举功能
首先把bigdata13的ZK宕机,然后查看剩下两台服务器身份信息

观察发现,将bigdata14变成了leader,证明选举成功
然后重启bigdata13的ZooKeeper,观察三者的身份信息
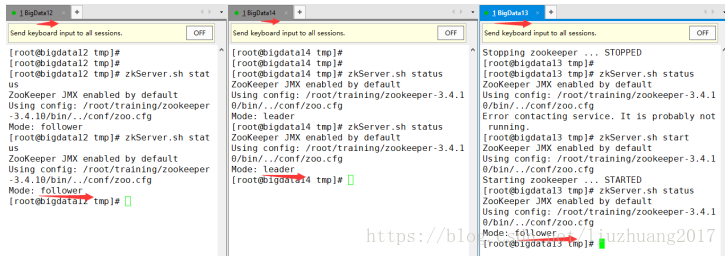
观察发现bigdata12变成了leader,而bigdata14bai变成了follower。