做个笔记,巩固一下,顺便为了以后复习。
首先,Facial Alignment就是在图片上找到68个点的位置,每个点坐标由(x,y)组成。这68个点,就是最后所求的输出结果。
机器学习的本质,就是“要知道怎么从这个物体身上提取属于他的特征出来,然后和其他物体进行区分”。这个特征的最重要因素之一就是6式中的φ,但也需要一个特征映射R矩阵来将特征进行映射为最终需要的输出结果。最终用一个b进行微调。Δx不是特征,是特征映射的结果,比如说,如果你做分类,那么Δx就是0或者1,来表示这张图片是不是你想要的结果。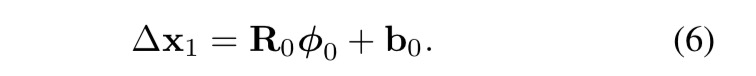
当前有监督的机器学习都有一个训练集和一个测试集。首先把训练集里面的每张图片的真实结果,做个平均计算,也就会得到一个平均的68个点,称为x0。然后当输入一张新的图片,就先用这个x0放在这个脸上。然后在每个特征点上提取特征,训练一个R矩阵,然后得到Δx1,然后x0+Δx1=x1。这个x1就相对x0来说,要精确的多。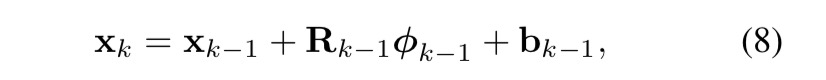 而第8式就是在重复第6式,在x1的基础上继续提取特征,然后训练新的R矩阵。然后得到x2,步步逼近最接近真实的结果。
而第8式就是在重复第6式,在x1的基础上继续提取特征,然后训练新的R矩阵。然后得到x2,步步逼近最接近真实的结果。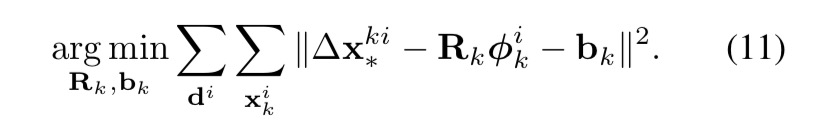 第11式:其中最左侧的argmin部分意味,求出R,b使得最右边的式子结果最小。最右边的式子为误差。
第11式:其中最左侧的argmin部分意味,求出R,b使得最右边的式子结果最小。最右边的式子为误差。
其中:Δx为真实的差值(由人为标定的68个点和当前你预测出来的68个点之间的差值),而右侧的两个项则为我们希望我们训练出来的R,能够将当前的特征映射出的结果,越接近越好。原论文截图如下:
