引言
前面的特征提取部分采用的是PCA,后面的识别分类是采用的BP神经网络。
1、PCA算法
算法大致步骤:
设有m条n维数据。
1)将原始数据按列组成n行m列矩阵X;
2)将X的每一行(这里是图片也就是一张图片变换到一行)进行零均值化,即减去这一行的均值(样本中心化和标准化);
将所有的样本融合到一个矩阵里面特征向量就是变换空间的基向量U=[u1,u2,u3,u4,…],脑袋里面要想到一个样本投影变换就是该空间的一个点,然后对于许多点可以用KNN等不同的方法进行分类。
3)求出协方差矩阵
;
4)求出协方差矩阵的特征值及对应的特征向量;
5)将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P;
6)
即为降维到
维后的数据。
对数据进行中心化预处理,这样做的目的是要增加基向量的正交性,便于高维度向低纬度的投影,即便于更好的描述数据。
对数据标准化的目的是消除特征之间的差异性,当原始数据不同维度上的特征的尺度不一致时,需要标准化步骤对数据进行预处理,使得在训练神经网络的过程中,能够加速权重参数的收敛。
过中心化和标准化,最后得到均值为0,标准差为1的服从标准正态分布的数据。
求协方差矩阵的目的是为了计算各维度之间的相关性,而协方差矩阵的特征值大小就反映了变换后在特征向量方向上变换的幅度,幅度越大,说明这个方向上的元素差异也越大(越有投影的必要,矩阵相乘的过程就是投影),故而选取合适的前k个能以及小的损失来大量的减少元数据的维度。
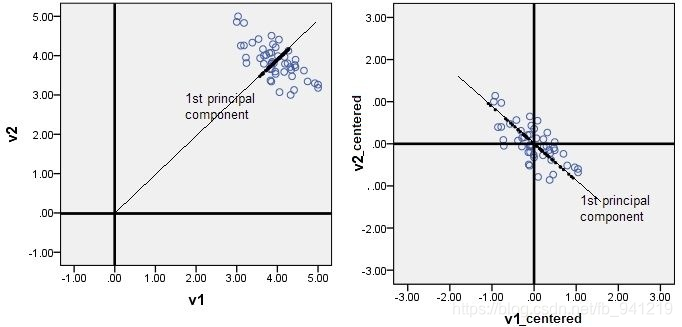
2、PCA原理推导
基于K-L展开的PCA特征提取:



3、神经网络
参考博客
4、matlab代码
使用的是ORL人脸库,40个人,一半做训练一半做测试。
fastPCA.m
function [pcaA V] = fastPCA( A, k )
% 快速PCA
%
% 输入:A --- 样本矩阵,每行为一个样本
% k --- 降维至 k 维
% 输出:pcaA --- 降维后的 k 维样本特征向量组成的矩阵,每行一个样本,列数 k 为降维后的样本特征维数
% V --- 主成分向量
[r c] = size(A);
% 样本均值
meanVec = mean(A);
% 计算协方差矩阵的转置 covMatT
Z = (A-repmat(meanVec, r, 1));
covMatT = Z * Z';
% 计算 covMatT 的前 k 个本征值和本征向量
[V D] = eigs(covMatT, k);
% 得到协方差矩阵 (covMatT)' 的本征向量
V = Z' * V;
% 本征向量归一化为单位本征向量
for i=1:k
V(:,i)=V(:,i)/norm(V(:,i));
end
% 线性变换(投影)降维至 k 维
pcaA = Z * V;
% 保存变换矩阵 V(10304*49) 和变换原点 meanVec(1*10304)(均值)
% 这里就是PCA部分训练得到的数据,保存后面测试的时候依然往这个空间投影2018.11.29_FB
save('Mat/PCA.mat', 'V', 'meanVec');
ReadFaces.m
function [imgRow,imgCol,FaceContainer,faceLabel]=ReadFaces(nFacesPerPerson, nPerson, bTest)
% 读入ORL人脸库的指定数目的人脸前前五张(训练)
%
% 输入:nFacesPerPerson --- 每个人需要读入的样本数,默认值为 5
% nPerson --- 需要读入的人数,默认为全部 40 个人
% bTest --- bool型的参数。默认为0,表示读入训练样本(前5张);如果为1,表示读入测试样本(后5张)
%
% 输出:FaceContainer --- 向量化人脸容器,nPerson(200) * 10304 的 2 维矩阵,每行对应一个人脸向量
if nargin==0 %default value
nFacesPerPerson=5;%前5张用于训练
nPerson=40;%要读入的人数(每人共10张,前5张用于训练)
bTest = 0;
elseif nargin < 3
bTest = 0;
end
img=imread('Data/sample/S1/1.pgm');%为计算尺寸先读入一张
[imgRow,imgCol]=size(img);
%构建40人*前5张共200行,imgRow*imgCol列的全零矩阵
FaceContainer = zeros(nFacesPerPerson*nPerson, imgRow*imgCol);
%构建200行,一列全零矩阵
faceLabel = zeros(nFacesPerPerson*nPerson, 1);
% 读入训练数据
for i=1:nPerson %40人
i1=mod(i,10); % 个位,%该函数用于进行取模(取余)运算
i0=char(i/10);% 将数转成字符串
%2018.11.29_FB
% num2str()是将数转成文字,eg. num2str(43)得到的将是'43',是两个字符
% char是按照ascii码表将数字映射成字符,char(43)得到的将是‘+’,(加号的ascii码是43)
if bTest == 0 % 读入训练数据 %bTest为导入训练样本还是测试样本的flag
strPath='Data/sample/S';
else
strPath='Data/test/S';
end
if( i0~=0 ) %组建图片的文件名!
strPath=strcat(strPath,'0'+i0);
end
strPath=strcat(strPath,'0'+i1);
strPath=strcat(strPath,'/');
tempStrPath=strPath;
for j=1:nFacesPerPerson %训练数据集的五张图片nFacesPerPerson = 5
strPath=tempStrPath;
if bTest == 0 % 读入训练数据
strPath = strcat(strPath, '0'+j);
else
% 读入测试数据,这里把数字5改为nFacePerPreson维护性更好2018.11.29_FB
strPath = strcat(strPath, num2str(5+j));
end
strPath=strcat(strPath,'.pgm');
img=imread(strPath);%具体读入单张图片
%把读入的图像按列存储为行向量放入向量化人脸容器faceContainer的对应行中2018.11.29_FB
FaceContainer((i-1)*nFacesPerPerson+j, :) = img(:)';
%类别标签111112222233333...(五个为一个类别,40个类别)
faceLabel((i-1)*nFacesPerPerson+j) = i;
end % j
end % i
% 保存人脸样本矩阵FaceMat(200*10304)每一行为一个样本
save('Mat/FaceMat.mat', 'FaceContainer')
scaling.m 归一化
function [SVFM, lowVec, upVec] = scaling(VecFeaMat, bTest, lRealBVec, uRealBVec)
% Input: VecFeaMat --- 需要scaling的 m*n 维数据矩阵,每行一个样本特征向量,列数为维数
% bTest --- =1:说明是对于测试样本进行scaling,此时必须提供 lRealBVec 和 uRealBVec
% 的值,此二值应该是在对训练样本 scaling 时得到的
% =0:默认值,对训练样本进行 scaling
% lRealBVec --- n维向量,对训练样本 scaling 时得到的各维的实际下限信息
% uRealBVec --- n维向量,对训练样本 scaling 时得到的各维的实际上限信息
%
% output: SVFM --- VecFeaMat的 scaling
% upVec --- 各维特征的上限(只在对训练样本scaling时有意义,bTest = 0)
% lowVec --- 各维特征的下限(只在对训练样本scaling时有意义,bTest = 0)
if nargin < 2
%函数输入参数个数的意思,当输入参数少于2个时,说明是训练阶段,故将bTest置为零,2018.11.29_FB
%nargin输入参数个数,nargout输出参数个数
bTest = 0;
end
% 缩放目标范围[-1, 1]
lTargB = -1;
uTargB = 1;
%pcaFaces(200*49)
[m n] = size(VecFeaMat);
SVFM = zeros(m, n);
if bTest
if nargin < 4
error('To do scaling on testset, param lRealB and uRealB are needed.')
end
if nargout > 1 %nargout输出参数个数
error('When do scaling on testset, only one output is supported.')
end
for iCol = 1:n %n为pcaFaces 列数 k=49
if uRealBVec(iCol) == lRealBVec(iCol) %实际上限信息 = 实际下限信息
SVFM(:, iCol) = uRealBVec(iCol);
SVFM(:, iCol) = 0;
else
%lTargB = -1; uTargB = 1;
SVFM(:, iCol) = lTargB + ( VecFeaMat(:, iCol) - lRealBVec(iCol) ) / ( uRealBVec(iCol)-lRealBVec(iCol) ) * (uTargB-lTargB); % 测试数据的scaling
end
end
else
%训练阶段的scaling归一化
upVec = zeros(1, n);% 归一化 各个特征的上下限训练后需要保存的向量
lowVec = zeros(1, n);
for iCol = 1:n
lowVec(iCol) = min( VecFeaMat(:, iCol) ); %就是选取一个最小值
upVec(iCol) = max( VecFeaMat(:, iCol) );
if upVec(iCol) == lowVec(iCol)
SVFM(:, iCol) = upVec(iCol);
SVFM(:, iCol) = 0;
else
SVFM(:, iCol) = lTargB + ( VecFeaMat(:, iCol) - lowVec(iCol) ) / ( upVec(iCol)-lowVec(iCol) ) * (uTargB-lTargB); % 训练数据的scaling
end
end
end
FastBPfacedetection.m
function FastBPfacedetection()
%% 第一步,读入数据
global imgRow;
global imgCol;
global net
display(' ');
display(' ');
display('训练开始...');
nPerson=40;
nFacesPerPerson = 5;
display('读入人脸数据...');
[imgRow,imgCol,FaceContainer,faceLabel]=ReadFaces(nFacesPerPerson,nPerson);
nFaces=size(FaceContainer,1);%样本(人脸)数目(40*5=200个人脸)
display('PCA降维...');
k=49; %前 k 个本征值和本征向量
[pcaFaces, W] = fastPCA(FaceContainer, k); % 主成分分析PCA
% pcaFaces是200*49的矩阵, 每一行代表一张主成分脸(共40人,每人5张),每个脸49维特征
% W是分离变换矩阵, 10304*49 的矩阵
visualize_pc(W);%显示主成分脸
X = pcaFaces;
display('归一化开始...');
display('.........');
[X,A0,B0] = scaling(X);
save('Mat/scaling.mat', 'A0', 'B0');
% 保存 scaling 后的训练数据至 trainData.mat
TrainData = X;
trainLabel = faceLabel; %在ReadFaces.m里面定义,人脸类别标签200*1(期望输出)
save('Mat/trainData.mat', 'TrainData', 'trainLabel');
display('归一化完成...');
%% 第二步,创建并训练BP神经网络
%生成训练BP神经网络的输入 P
%200*49的矩阵, 每一行代表一张主成分脸(共40人,每人5张),每个脸49维特征(输入)
%与faceLabel的200*1相对应(输出)
P=TrainData;
%生成目标输出矢量 T
T=zeros(200,40);
for i=1:40
for j=1:5
T((i-1)*5+j,i)=1;
end
end
%打乱训练样本顺序
%P(200*49) T(200*40)全零矩阵
gx2(:,1:k)=P; %前 k 个本征值和本征向量 k=49
gx2(:,(k+1):(k+40))=T;
xd=gx2(randperm(numel(gx2)/(k+40)),:); %matlab randperm()函数,猜测应该是样本与标签对应打乱
gx=xd(:,1:k);d=xd(:,(k+1):(k+40));
P=gx';
T=d';
%创建BP神经网络
[R,Q]=size(P);
[S2,Q]=size(T);
net=newff(minmax(P),T,[fix(sqrt(R*S2))],{'purelin','purelin'},'traingdx');
%训练BP神经网络
net.trainparam.epochs=5000; %训练步数
net.trainparam.goal=0.0001; %训练目标误差
net.divideFcn = ''; %所有的样本都用于训练
[net,tr]=train(net,P,T); %P为输入,T为输出,开始训练
%仿真BP神经网络
Y=sim(net,P);
%% 第三步,测试BP神经网络并计算其识别率
display('测试开始...');
%测试BP神经网络
s=0;
load('Mat/PCA.mat');
load('Mat/scaling.mat');
load('Mat/trainData.mat');
% load('Mat/multiSVMTrain.mat');
display('..............................');
for i=1:40
for j=6:10 %读入40x5副测试图像
a=imread(strcat('Data\test\s',num2str(i),'\',num2str(j),'.pgm'));
b=a(1:10304);
b=double(b);
TestFace=b;
[m n] = size(TestFace);
TestFace = (TestFace-repmat(meanVec, m, 1))*V; % 经过pca变换降维
TestFace = scaling(TestFace,1,A0,B0);
X = TestFace;
Z=sim(net,X');
[zi,index2]=max(Z);
if index2==i
s=s+1;
else
% i %输出识别出错的那个人 i
% j %输出识别出错的那张图片 j
% index2; %输出误识别成的那个人
disp=(['测试集中第 ' ,num2str(i), '个人,第', num2str(j) , '张图片被错误分类到' ,num2str(index2), '类'])
end
end
end
%计算识别率
accuracy=s/Q

5、C++代码
后面补充。