LEETCODE算法注解30:
给定一个字符串 s 和一些长度相同的单词 words。找出 s 中恰好可以由 words 中所有单词串联形成的子串的起始位置。
注意子串要与 words 中的单词完全匹配,中间不能有其他字符,但不需要考虑 words 中单词串联的顺序。
首先,最初的想法是将words中的词全部组合,看s中是否有匹配的。但是这复杂度高的离谱,肯定超出时间限制。n为words的个数,s为字符串长度,复杂度为O(s*n!)。
第一种解法:利用hashmap
例如[tag,tad,best,word,best]这个例子在haspmap中的形式为
[tag,1]
[tad,1]
[best,2]
[word,1]
让当前字符串 tag tag tad best best word tag去匹配。
1>若字符串中单词未出现在hashmap中,则直接去匹配下一个单词。
2>单词匹配成功。将匹配成功的单词按照同样的方式存入hashmap2中。判断两个hashmap中匹配成功的单词的value值大小。如果hashmap1中的value值大于hashmap中的value值,代表此单词的匹配次数已经超过了words词组中给出的单词个数,其实是已经匹配失败了。
3>当全部正确匹配的个数已经等于words词组的个数时,就可以输出当前起始点了。
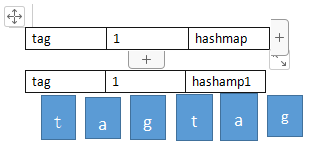
经过匹配到第二个tag时,
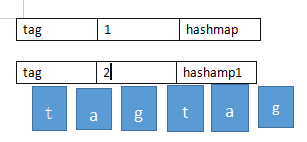
很明显第二次单词匹配虽然成功,但其实次数已经超出了words的次数,所以需要判断value值。
代码如下:
class Solution {
public List<Integer> findSubstring(String s, String[] words) {
List<Integer> ans = new ArrayList<Integer>();
int wordnumber = words.length;
if(wordnumber==0) return ans;
int wordlength = words[0].length();
//将所有单词存入hmp1中
HashMap<String, Integer> hmp1 = new HashMap<String, Integer>();
for(int i=0;i<wordnumber;i++)
{
//getOrDefaul此方法的含义;如果hmp1中不含有words[i],返回默认值0,含有返回此值的value值。
int value = hmp1.getOrDefault(words[i], 0);
//hashmap不允许key值重复,会覆盖
hmp1.put(words[i], value + 1);
}
//开始遍历s
for(int i=0 ; i< s.length()+1-wordnumber*wordlength ; i++)
{
HashMap<String, Integer> hmp2 = new HashMap<String, Integer>();
int num = 0;
//while循环为满足一次匹配的条件
while(num < wordnumber)
{
//依次截取出一个单词
String simpleword = s.substring(i+num*wordlength,i+(num+1)*wordlength);
//成功匹配
if(hmp1.containsKey(simpleword))
{
//将匹配成功的单词存入hmp2中
int value = hmp2.getOrDefault(simpleword, 0);
hmp2.put(simpleword, value + 1);
//边界条件,防止重复出现单词的个数超出words中给出的重复单词个数
if(hmp2.get(simpleword) > hmp1.get(simpleword)) break;
}
else//匹配失败
{
break;
}
num++;
}
//输出条件,单词全部匹配成功,增加i;
if(num == wordnumber)
{
ans.add(i);
}
}
return ans;
}
}
参考如下:https://leetcode-cn.com/problems/substring-with-concatenation-of-all-words/solution/xiang-xi-tong-su-de-si-lu-fen-xi-duo-jie-fa-by-w-6/
`
